強化学習:コンピューターに最適な決定をさせる方法の教え方
強化学習:コンピューターへの最適な決定方法を教える
強化学習とは何ですか?
強化学習は、エージェントが複雑な環境との相互作用を経験を通じて学習する機械学習の一分野です。
チェスや囲碁などの複雑なボードゲームで人間のパフォーマンスを超えるAIエージェントから自律的なナビゲーションまで、強化学習には興味深いさまざまな応用があります。
強化学習の分野での注目すべきブレイクスルーには、DeepMindのエージェントAlphaGo Zeroが囲碁で人間のチャンピオンさえも打ち負かすことができることや、複雑な3Dタンパク質構造を予測できるAlphaFoldなどがあります。
このガイドでは、強化学習のパラダイムについて紹介します。シンプルでありながら動機づけられる現実世界の例を取り上げ、強化学習のフレームワークを理解します。
- SAM-PTとは SAM(Segment Anything Model)の機能を拡張し、動画内の任意のオブジェクトのトラッキングとセグメンテーションを可能にする、新しいAIメソッドです
- Falcon-7Bの本番環境への展開
- 物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
強化学習のフレームワーク
まず、強化学習のフレームワークの要素を定義しましょう。
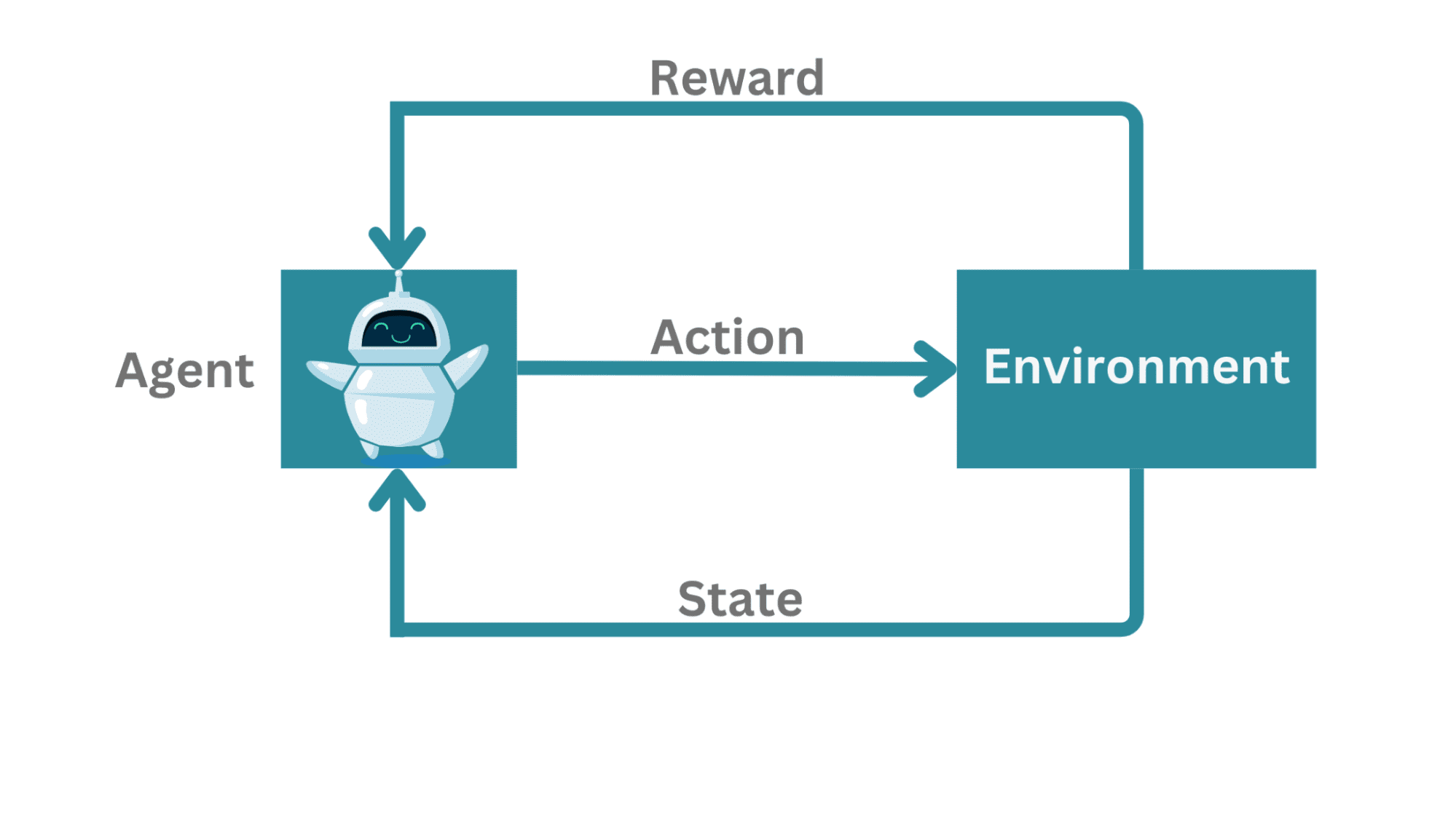
典型的な強化学習のフレームワークでは、以下の要素があります:
- エージェントが環境との相互作用を学習します。
- エージェントは状態を測定し、行動を取り、時々報酬を受け取ります。
この設定の実例としては、エージェントが対戦相手(例えばチェスのゲーム)と対戦したり、複雑な環境をナビゲートしようとすることがあります。
超単純化された例として、迷路にいるネズミを考えてみましょう。ここでは、エージェントは対戦相手ではなく、出口への経路を見つけようとしています。出口への経路が複数ある場合、迷路からの最短経路を選ぶことができます。

この例では、ネズミが迷路内をナビゲートしようとするエージェントであり、迷路が環境です。ここでの行動はネズミの迷路内での移動です。迷路から出口に成功すると、報酬としてチーズをもらいます。
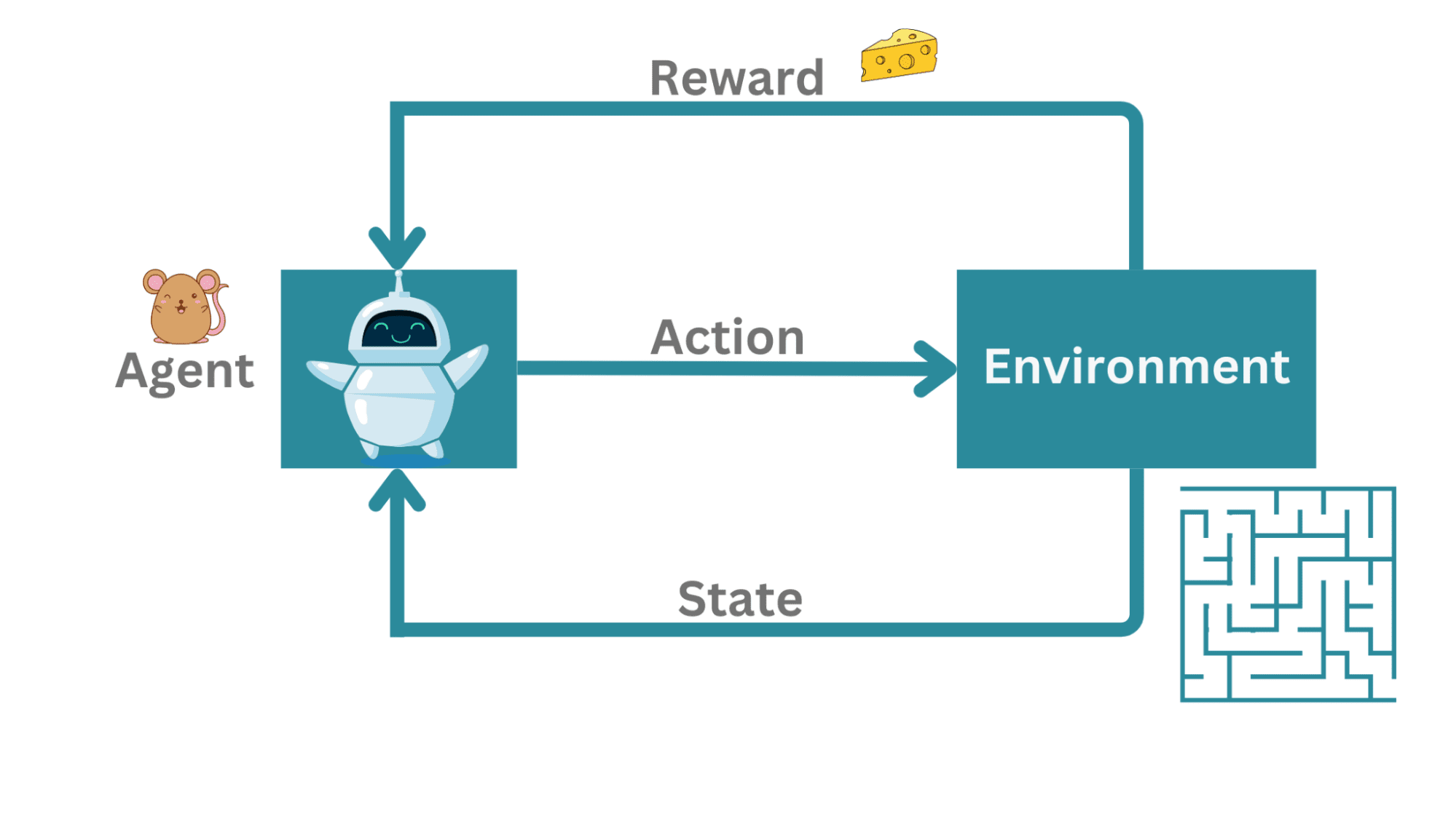
行動のシーケンスは離散的な時間ステップ(t = 1, 2, 3,…)で発生します。任意の時間ステップ t では、ネズミは迷路内の現在の状態のみを測定できます。まだ迷路全体を知りません。
したがって、エージェント(ネズミ)は時間ステップ t で環境内の自身の状態 s_t を測定し、有効な行動 a_t を取り、状態 s_(t + 1) に移動します。
強化学習はどのように異なるのですか?
ネズミ(エージェント)が迷路から試行錯誤を通じて出口を見つける必要があることに注意してください。もしネズミが迷路の壁に当たった場合、別の経路を見つけて出口にたどり着く必要があります。
もしもこれが教師あり学習の設定ならば、各動作の後に、エージェントはその行動が正しいかどうか、報酬につながるかどうかを知ることができるでしょう。教師あり学習は教師から学ぶことに似ています。
一方、評価者はいつもパフォーマンスが終わった後に、あなたのパフォーマンスがどれほど良いか悪いかを教えてくれます。このため、強化学習は批評者の存在のもとで学習するとも呼ばれています。
終端状態とエピソード
ネズミが出口に到達すると、それが終端状態に達します。これは、これ以上探索することができないことを意味します。
初期状態から終端状態までの行動のシーケンスはエピソードと呼ばれます。エージェントがナビゲートするための行動のシーケンスを学び、その結果としてチーズを受け取るために、エージェント(ネズミ)には多くのエピソードが必要です。
密な報酬と疎な報酬
エージェントが正しいアクションまたは正しいアクションのシーケンスを取るたびに、それに対して報酬を得ます。この場合、ネズミは迷路(環境)を通って出口に正しい経路を刻んだことに対して、チーズの一片を報酬として受け取ります。
この例では、ネズミは非常に最後になるまでチーズの一片を受け取りません。これは疎で遅延した報酬の例です。
報酬がより頻繁にあれば、密な報酬システムになります。
振り返ってみると、エージェントが報酬を得た原因となるアクションまたはアクションのシーケンスを特定する必要があります(これは一般的にクレジット割り当て問題と呼ばれています)。
方策、価値関数、最適化問題
環境は通常確定的ではなく確率的であり、方策も同様です。状態s_tが与えられた場合、エージェントはある確率でアクションを取り、別の状態s_(t+1)に移行します。
方策は、可能な状態の集合からアクションへのマッピングを定義するのに役立ちます。以下のような質問に答えるのに役立ちます:
- 期待報酬を最大化するためにどのようなアクションを取るべきですか?
- ある状態が与えられた場合、エージェントが期待報酬を最大化するために取ることができる最善のアクションは何ですか?
したがって、エージェントは方策πを実行していると考えることができます:

もう1つ関連する有用な概念は価値関数です。価値関数は次のように与えられます:

これは、方策πに従って状態にいる価値を示しています。量は、エージェントが状態で開始し、以降方策πを実行した場合に将来の期待報酬を表します。
まとめると、強化学習の目標は、方策を最適化して将来の期待報酬を最大化することです。したがって、πについて解くべき最適化問題と考えることができます。
割引率
新しい量ɣがあることに注意してください。これは何を表しているのでしょうか?ɣは割引率と呼ばれ、0から1の間の量です。これは将来の報酬が割引されることを意味します(読み方: 現在は遥かに重要です)。
探索と活用のトレードオフ
ネズミが迷路の食べ物ループの例に戻ってみましょう:もしネズミが小さなチーズのある出口Aへの経路を見つけることができれば、それを繰り返してチーズの一片を集め続けることができます。しかし、もし迷路にもっと大きなチーズのある出口Bがあった場合(より大きな報酬)はどうでしょうか?
ネズミが現在の戦略を活用し続け、新しい戦略を探索しない限り、出口Bのより大きなチーズの報酬を得ることはありません。
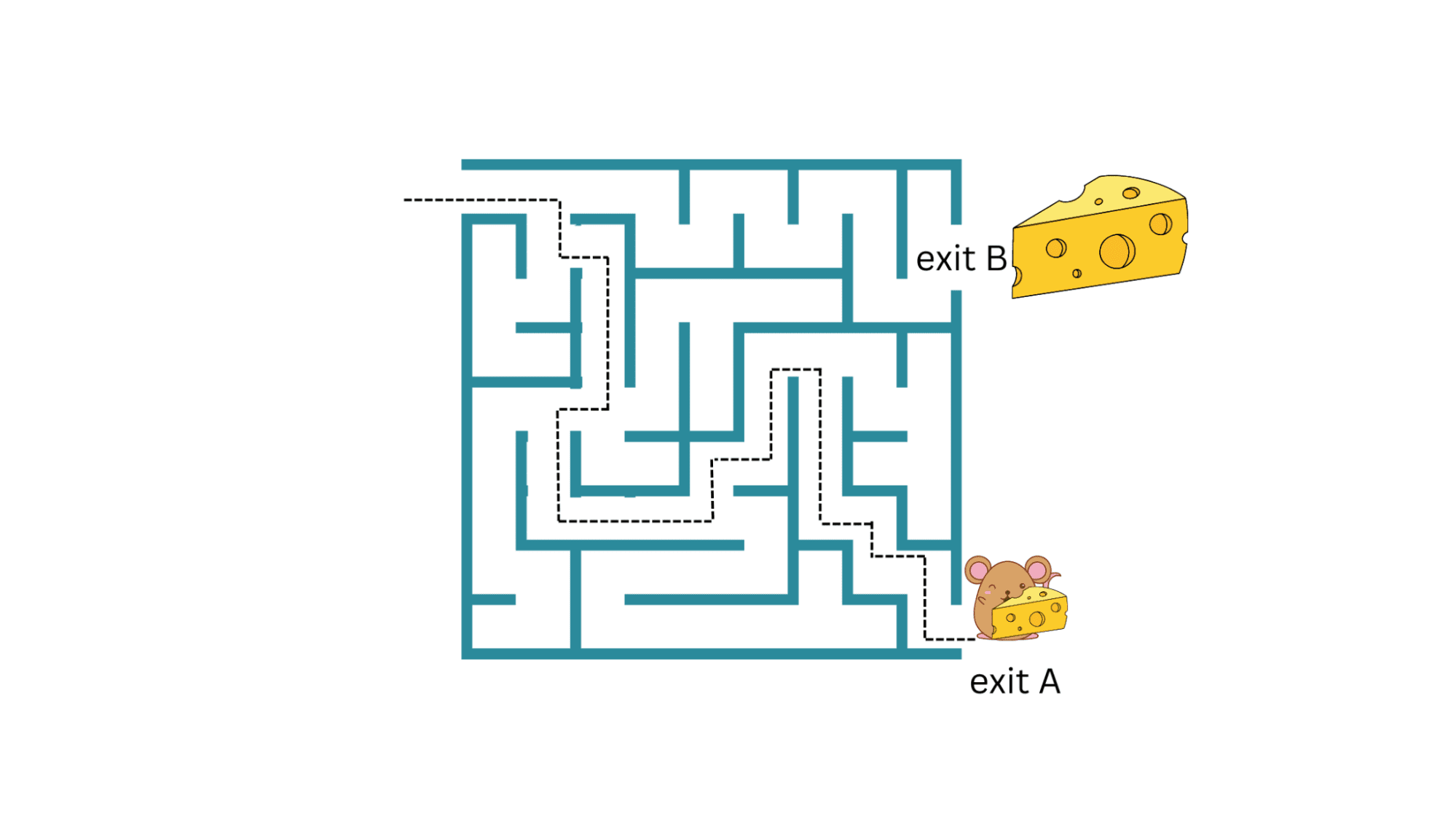
しかし、新しい戦略と将来の報酬に関連する不確実性は大きいです。では、どのように活用と探索を行うのでしょうか?現在の戦略を活用する割合と新しい戦略を探索する割合が、探索と活用のトレードオフと呼ばれます。
1つの可能なアプローチはε-グリーディーサーチです。可能なアクションのセットが与えられた場合、ε-グリーディーサーチは確率εで可能なアクションの1つを探索し、確率1-εで現在の戦略を活用します。
まとめと次のステップ
これまでにカバーした内容をまとめましょう。強化学習フレームワークのコンポーネントについて学びました:
- エージェントは環境とやり取りし、現在の状態を計測し、アクションを取り、報酬を正の強化として受け取ります。このフレームワークは確率的です。
- 次に、価値関数と方策について説明しました。最適化問題はしばしば期待将来報酬を最大化する最適な方策を見つけることに帰着します。
強化学習の領域をナビゲートするために、十分な知識を得ました。次はどこへ進むべきでしょうか?このガイドでは、強化学習のアルゴリズムについては触れませんでしたので、いくつかの基本的なアルゴリズムを探索することができます:
- 環境についてすべてを知っている(かつ完全にモデル化できる)場合、方策反復法や価値反復法などのモデルベースのアルゴリズムを使用することができます。
- しかし、ほとんどの場合、環境を完全にモデル化することはできません。この場合、状態-行動のペアを最適化するQ学習などのモデルフリーのアルゴリズムを見ることができます。
強化学習の理解を深めるためには、David Silver氏のYouTubeでの強化学習講義やHugging FaceのDeep Reinforcement Learning Courseなどが参考になるでしょう。Bala Priya Cはインド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点での仕事が好きです。彼女の興味と専門知識の範囲にはDevOps、データサイエンス、自然言語処理などが含まれます。彼女は読書、執筆、コーディング、そしてコーヒーを楽しみます!現在は、チュートリアル、ハウツーガイド、意見記事などを執筆することで、開発者コミュニティと彼女の知識を共有することに取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






