「Q-学習を用いたダイナミックプライシングのための強化学習」
強化学習によるダイナミックプライシングのQ学習
実践的なPythonの例を使ったQ学習の紹介
目次
- はじめに
- 強化学習の基礎2.1 キーコンセプト2.2 Q関数2.3 Q値2.4 Q学習2.5 ベルマン方程式2.6 探索 vs. 活用2.7 Qテーブル
- 動的価格設定の問題3.1 問題の設定3.2 実装
- 結論
- 参考文献
1. はじめに
この記事では、強化学習の基本的な概念を紹介し、報酬と経験に基づいて情報を元にした意思決定を行うことで最適な方策を学習する手法であるQ学習について詳しく説明します。
また、ゼロから構築された実践的なPythonの例も共有します。具体的には、ビジネスの重要な側面である価格設定の技術をマスターするためにエージェントを訓練し、利益を最大化する方法を学習させます。
それでは、早速旅を始めましょう。
2. 強化学習の基礎
2.1 キーコンセプト
強化学習(RL)は、エージェントが試行錯誤を通じてタスクを達成するために学習する機械学習の分野です。
- メタAIは、SeamlessM4Tを発表しましたこれは、音声とテキストの両方でシームレスに翻訳と転写を行うための基盤となる多言語・マルチタスクモデルです
- 「TADAをご紹介します 口述された説明を表現豊かな3Dアバターに変換するための強力なAI手法」
- このAI論文は、「MATLABER:マテリアルを意識したテキストから3D生成のための新しい潜在的BRDFオートエンコーダ」を提案しています
簡単に言うと、エージェントは報酬メカニズムを介して正反応または負反応に関連付けられたアクションを試みます。エージェントは報酬を最大化するように行動を調整し、最終的な目標を達成するための最適な行動を学習します。
具体例を通じてRLのキーコンセプトを紹介しましょう。簡易的なアーケードゲームを想像してみてください。ここでは、猫が迷路を進みながら宝物(ミルクのグラスと毛糸のボール)を集め、同時に工事現場を避けるというゲームです:
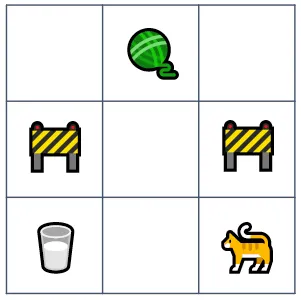
- エージェントはアクションの進行方向を選択する役割を持ちます。この例では、エージェントは猫の次の動きを決定するジョイスティックを操作するプレーヤーです。
- 環境は…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




