Falcon-7Bの本番環境への展開
展開する
ステップバイステップのチュートリアル
Falcon-7Bをマイクロサービスとしてクラウドで実行する

背景
今までに、ChatGPTの機能と提供するものを見てきました。しかし、企業利用において、ChatGPTのようなクローズドソースのモデルは、企業がデータを制御できないというリスクをもたらすことがあります。OpenAIは、ユーザーデータは保存されず、モデルのトレーニングに使用されないと主張していますが、データが何らかの形で漏洩する可能性はないとは保証されていません。
クローズドソースのモデルに関連する問題のいくつかに対処するために、研究者たちはChatGPTのようなモデルと匹敵するオープンソースのLLMを構築するために急いでいます。オープンソースのモデルを使用することで、企業はデータ漏洩のリスクを軽減しながら、モデル自体を安全なクラウド環境にホストすることができます。さらに、モデルの内部の動作に対して完全な透明性を得ることができるため、AIに対する信頼をより高めるのに役立ちます。
オープンソースのLLMの最近の進歩により、新しいモデルを試して、ChatGPTなどのクローズドソースのモデルと比較してみるのは魅力的です。
しかし、現在のオープンソースのモデルを実行することは、重要な障壁があります。ChatGPTのAPIを呼び出す方が、オープンソースのLLMを実行する方法を理解するよりも簡単です。
- 物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
- OpenAIのモデレーションAPIを使用してコンテンツのモデレーションを強化する
- 50以上の機械学習面接(インタビュアーとして)から学んだこと
この記事では、Falcon-7Bモデルのようなオープンソースのモデルをクラウド上で本番のような環境で実行する方法を紹介することで、これらの障壁を取り除くことを目指します。ChatGPTと同様のAPIエンドポイントを介してこれらのモデルにアクセスできるようになります。
課題
オープンソースのモデルを実行する際の大きな課題の1つは、計算リソースの不足です。Falcon 7Bのような「小規模」なモデルでも、GPUが必要です。
この問題を解決するために、クラウドのGPUを活用することができます。しかし、これには別の課題があります。LLMをコンテナ化する方法はどうすればよいのでしょうか?GPUサポートを有効にするにはどうすればよいのでしょうか?GPUサポートを有効にするには、CUDAの知識が必要であり、CUDAとの作業は適切なCUDAの依存関係のインストール方法や互換性のあるバージョンを把握する必要があるため、面倒です。
そのため、CUDAのデス・トラップを回避するために、多くの企業がモデルを簡単にコンテナ化し、GPUサポートを有効にするためのソリューションを作成しています。このブログ記事では、Trussというオープンソースのツールを使用して、煩雑な手間をかけずにLLMをコンテナ化する方法を紹介します。
Trussは、どのフレームワークを使用して構築されたモデルでも簡単にコンテナ化することができる開発者向けのツールです。
なぜTrussを使用するのですか?
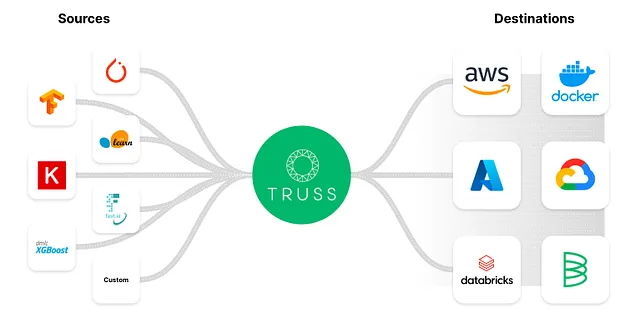
Trussには、以下のような便利な機能が最初から備わっています:
- Pythonモデルを本番用のAPIエンドポイントを持つマイクロサービスに変換すること
- Dockerを介した依存関係の固定
- GPUでの推論のサポート
- モデルの簡単な前処理および後処理
- 簡単かつ安全なシークレットの管理
私は以前にTrussを使用して機械学習モデルを展開したことがあり、プロセスは非常にスムーズで簡単でした。Trussは自動的にdockerfileを作成し、Pythonの依存関係を管理します。私たちがやることは、モデルのコードを提供するだけです。
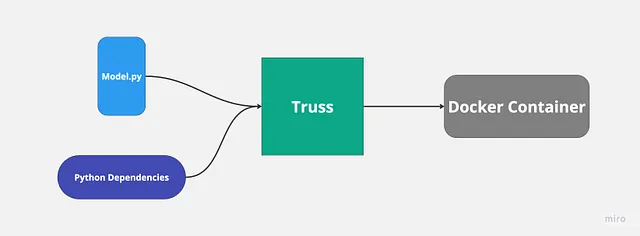
Trussのようなツールを使用する主な理由は、GPUサポートを備えたモデルを簡単に展開できるようになるからです。
注: Basetenからのスポンサーシップを受けたわけでも、彼らと関連しているわけでもありません。私はBasetenやTrussからの影響を受けてこの記事を書いているわけではありません。ただ、彼らのオープンソースのプロジェクトがクールで役に立つと思っただけです。
計画
このブログ投稿では、以下の内容をカバーします:
- Trussを使用してローカルでFalcon 7Bをセットアップする
- GPUを持っている場合はローカルでモデルを実行する(私はRTX 3080を使用しています)
- モデルをコンテナ化し、Dockerを使用して実行する
- モデルを実行するためにGoogle CloudでGPUを有効にしたKubernetesクラスタを作成する
ステップ2でGPUを持っていない場合でも、クラウドでモデルを実行することができますので、心配しないでください。
以下は、コードを確認したい場合に使用することができるGitHubリポジトリです:
GitHub – htrivedi99/falcon-7b-truss
GitHubでhtrivedi99/falcon-7b-trussの開発に貢献するには、GitHubでアカウントを作成してください。
github.com
さあ、始めましょう!
ステップ1:Trussを使用してFalcon 7Bのローカルセットアップ
まず、Pythonバージョン≥ 3.8のプロジェクトを作成する必要があります。
次に、Hugging FaceからモデルをダウンロードしてTrussを使用してパッケージ化します。以下の依存関係をインストールする必要があります:
pip install trussPythonプロジェクト内にmain.pyというスクリプトを作成します。これは、Trussと一緒に作業するための一時的なスクリプトです。
次に、ターミナルで次のコマンドを実行してTrussパッケージをセットアップします:
truss init falcon_7b_truss新しいTrussを作成するかどうかを求められた場合は、’y’を押します。完了すると、falcon_7b_trussという新しいディレクトリが表示されます。そのディレクトリ内には、いくつかの自動生成されたファイルとフォルダがあります。埋める必要があるいくつかのファイルがあります:model.py(modelパッケージの下にネストされています)とconfig.yamlです。
├── falcon_7b_truss│ ├── config.yaml│ ├── data│ ├── examples.yaml│ ├── model│ │ ├── __init__.py│ │ └── model.py│ └── packages└── main.py先に述べたように、Trussはモデルのコードだけを必要とし、他のすべてのことを自動的に処理します。コードはmodel.py内に書かれる必要がありますが、特定の形式で書かれている必要があります。
Trussは、各モデルが少なくとも3つの関数(__init__、load、predict)をサポートすることを期待しています。
__init__は、主にクラス変数の作成に使用されますloadは、Hugging Faceからモデルをダウンロードする場所ですpredictは、モデルを呼び出す場所です
以下は、model.pyの完全なコードです:
import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, pipelinefrom typing import DictMODEL_NAME = "tiiuae/falcon-7b-instruct"DEFAULT_MAX_LENGTH = 128class Model: def __init__(self, data_dir: str, config: Dict, **kwargs) -> None: self._data_dir = data_dir self._config = config self.device = "cuda" if torch.cuda.is_available() else "cpu" print("THE DEVICE INFERENCE IS RUNNING ON IS: ", self.device) self.tokenizer = None self.pipeline = None def load(self): self.tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) model_8bit = AutoModelForCausalLM.from_pretrained( MODEL_NAME, device_map="auto", load_in_8bit=True, trust_remote_code=True) self.pipeline = pipeline( "text-generation", model=model_8bit, tokenizer=self.tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", ) def predict(self, request: Dict) -> Dict: with torch.no_grad(): try: prompt = request.pop("prompt") data = self.pipeline( prompt, eos_token_id=self.tokenizer.eos_token_id, max_length=DEFAULT_MAX_LENGTH, **request )[0] return {"data": data} except Exception as exc: return {"status": "error", "data": None, "message": str(exc)}ここで何が起こっているか:
MODEL_NAMEは使用するモデルであり、私たちの場合はfalcon-7b-instructモデルです。load内では、モデルをHugging Faceから8ビットでダウンロードします。8ビットを使用する理由は、量子化された場合、モデルがGPU上でのメモリ使用量が大幅に少なくなるためです。- また、モデルを8ビットでロードすることは、13GBのVRAMを持たないGPU上でモデルをローカルで実行する場合に必要です。
predict関数はJSONリクエストをパラメータとして受け取り、self.pipelineを使用してモデルを呼び出します。torch.no_gradはPytorchに推論モードであることを伝えるため、トレーニングモードではないことを示します。
素敵です!これでモデルのセットアップが完了しました。
ステップ2:モデルをローカルで実行する(オプション)
Nvidia GPUで8GB以上のVRAMを持っている場合、このモデルをローカルで実行することができます。
そうでない場合は、次のステップに進んでも構いません。
モデルをローカルで実行するためには、いくつかの依存関係をダウンロードする必要があります。依存関係をダウンロードする前に、CUDAと適切なCUDAドライバがインストールされていることを確認してください。
モデルをローカルで実行しようとしているため、CUDAの混乱を管理するためにTrussは役に立ちません。
pip install transformerspip install torchpip install peftpip install bitsandbytespip install einopspip install scipy 次に、main.py内に、falcon_7b_trussディレクトリの外部に作成したスクリプトをロードする必要があります。
以下は、main.pyのコードです:
import trussfrom pathlib import Pathimport requeststr = truss.load("./falcon_7b_truss")output = tr.predict({"prompt": "Hi there how are you?"})print(output)ここで何が起こっているか:
- 思い出せば、
falcon_7b_trussディレクトリはtrussによって作成されました。truss.loadを使用して、モデルや依存関係を含むパッケージ全体をロードできます。 - パッケージをロードしたら、単に
predictメソッドを呼び出してモデルの出力を取得できます。
main.pyを実行してモデルから出力を取得します。
このモデルファイルは約15GBのサイズであるため、モデルのダウンロードに5〜10分かかる場合があります。スクリプトを実行した後、次のような出力が表示されるはずです:
{'data': {'generated_text': "Hi there how are you?\nI'm doing well. I'm in the middle of a move, so I'm a bit tired. I'm also a bit overwhelmed. I'm not sure how to get started. I'm not sure what I'm doing. I'm not sure if I'm doing it right. I'm not sure if I'm doing it wrong. I'm not sure if I'm doing it at all.\nI'm not sure if I'm doing it right. I'm not sure if I'm doing it wrong. I"}}ステップ3:Dockerを使用してモデルをコンテナ化する
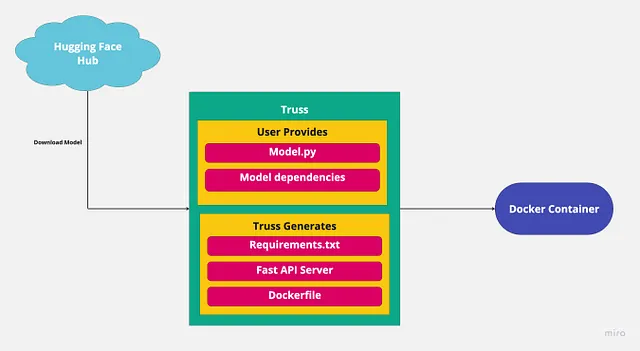
通常、モデルをコンテナ化する際には、モデルバイナリとPythonの依存関係を取り、FlaskやFast APIサーバーを使用してそれらをすべてラップします。
これには多くの定型作業が含まれており、自分で行う必要はありません。Trussがそれを処理します。すでにモデルを提供しているので、Trussがサーバーを作成します。したがって、残りの作業はPythonの依存関係を提供することだけです。
config.yamlはモデルの設定を保持します。ここではモデルの依存関係を追加できます。設定ファイルには必要なもののほとんどが含まれていますが、いくつか追加する必要があります。
以下に、config.yamlに追加する内容を示します:
apply_library_patches: truebundled_packages_dir: packagesdata_dir: datadescription: nullenvironment_variables: {}examples_filename: examples.yamlexternal_package_dirs: []input_type: Anylive_reload: falsemodel_class_filename: model.pymodel_class_name: Modelmodel_framework: custommodel_metadata: {}model_module_dir: modelmodel_name: Falcon-7Bmodel_type: custompython_version: py39requirements:- torch- peft- sentencepiece- accelerate- bitsandbytes- einops- scipy- git+https://github.com/huggingface/transformers.gitresources: use_gpu: true cpu: "3" memory: 14Gisecrets: {}spec_version: '2.0'system_packages: []追加したメインの要素はrequirementsです。リストされたすべての依存関係は、モデルのダウンロードと実行に必要です。
もう1つ追加した重要な要素はresourcesです。 use_gpu: trueは必須です。これは、GPUサポートが有効になっているDockerfileをTrussに作成するためです。
これで構成は完了です。
次に、モデルをコンテナ化します。Dockerを使用してモデルをコンテナ化する方法がわからない場合は心配しないでください。Trussがサポートしています。
main.pyファイルの中に、すべてを一緒にパッケージするようにTrussに指示します。以下に必要なコードを示します:
import trussfrom pathlib import Pathimport requeststr = truss.load("./falcon_7b_truss")command = tr.docker_build_setup(build_dir=Path("./falcon_7b_truss"))print(command)起こっていること:
- まず、
falcon_7b_trussをロードします - 次に、
docker_build_setup関数は、Dockerfileの作成やFast APIサーバーのセットアップなど、複雑な処理をすべて処理します。 falcon_7b_trussディレクトリを見ると、多くのファイルが生成されていることがわかります。これらのファイルの動作については心配する必要はありません。すべてが裏で管理されます。- 実行の最後に、ドッカーイメージをビルドするためのdockerコマンドを取得します:
docker build falcon_7b_truss -t falcon-7b-model:latest
ドッカーイメージをビルドしたい場合は、ビルドコマンドを実行してください。イメージのサイズは約9 GBですので、ビルドには時間がかかるかもしれません。ビルドすることなく、ただ追跡するだけであれば、私のイメージを使用できます:htrivedi05/truss-falcon-7b:latest。
イメージを自分でビルドする場合は、イメージにタグを付けてdocker hubにプッシュする必要があります。イメージをプルできるようにするためです。イメージのビルド後に実行する必要があるコマンドは次のとおりです:
docker tag falcon-7b-model <docker_user_id>/falcon-7b-model
docker push <docker_user_id>/falcon-7b-model素晴らしい!クラウドでモデルを実行する準備ができました!
(GPUを使用してローカルでイメージを実行するためのオプションの手順)
Nvidia GPUを持っており、GPUサポートを使用してローカルでコンテナ化されたモデルを実行したい場合は、dockerがGPUを使用するように設定する必要があります。
ターミナルを開き、次のコマンドを実行してください:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) && curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - && curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt-get updateapt-get install -y nvidia-docker2
sudo systemctl restart dockerdockerがGPUにアクセスできるように設定されたので、コンテナを実行する方法は次のとおりです:
docker run --gpus all -d -p 8080:8080 falcon-7b-model再度、モデルのダウンロードには時間がかかります。正しく動作していることを確認するために、コンテナのログを確認し、「THE DEVICE INFERENCE IS RUNNING ON IS: cuda」と表示されるはずです。
次のようにAPIエンドポイントを介してモデルを呼び出すことができます:
import requestsdata = {"prompt": "Hi there, how's it going?"}res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", json=data)print(res.json())ステップ4:モデルの本番環境への展開
ここでは「本番」という言葉をかなり広義に使っています。モデルをKubernetesで実行し、簡単にスケーリングして可変トラフィックを処理します。
それと共に、Kubernetesにはネットワークポリシー、ストレージ、構成マップ、負荷分散、シークレット管理など、非常に多くの設定があります。
Kubernetesは「スケール」して「本番」のワークロードを実行するために構築されていますが、必要な本番レベルの設定がデフォルトで用意されているわけではありません。この記事の範囲を超える高度なKubernetesのトピックについて説明することは、今回の目標から逸れます。したがって、このブログ記事では、ベルやホイッスルのない最小のクラスタを作成します。
それでは、さっそくクラスタを作成しましょう!
前提条件:
- Google Cloudのプロジェクトを持っていること
- マシンにgcloud CLIがインストールされていること
- GPUを有効にしたマシンを実行するために十分なクオータがあること。クオータはIAM&Adminで確認できます。
GKEクラスタの作成
GoogleのKubernetesエンジンを使用してクラスタを作成および管理します。それでは、重要な情報の時間です:
GoogleのKubernetesエンジンは無料ではありません。強力なGPUを無料で使用することはできません。したがって、より弱いGPUを搭載したシングルノードクラスタを作成します。この実験には$1から$2かかるはずです。
以下は実行するKubernetesクラスタの設定です:
- 1つのノード、標準のKubernetesクラスタ(オートパイロットではない)
- Nvidia T4 GPU 1つ
- n1-standard-4マシン(4つのvCPU、15 GBのメモリ)
- すべてをスポットインスタンスで実行します
注意:異なるリージョンにいて、同じリソースにアクセスできない場合は、自由に変更してください。
クラスタの作成手順:
- Google Cloudコンソールに移動し、Kubernetes Engineというサービスを検索します
2. CREATEボタンをクリックします
- 標準のクラスタを作成していることを確認してください。一番上に「Kubernetesクラスタの作成」と表示されているはずです。
3. クラスタの基本設定
- クラスタの基本設定タブ内では、あまり変更する必要はありません。クラスタに名前を付けるだけで十分です。ゾーンやコントロールプレーンを変更する必要はありません。
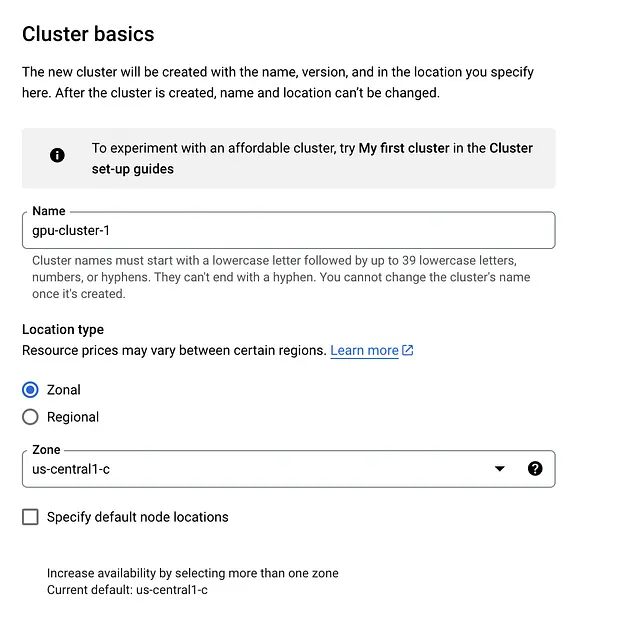
4. default-poolタブをクリックし、ノードの数を1に変更します
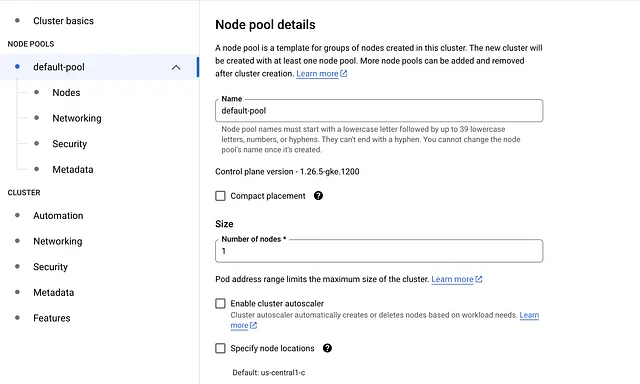
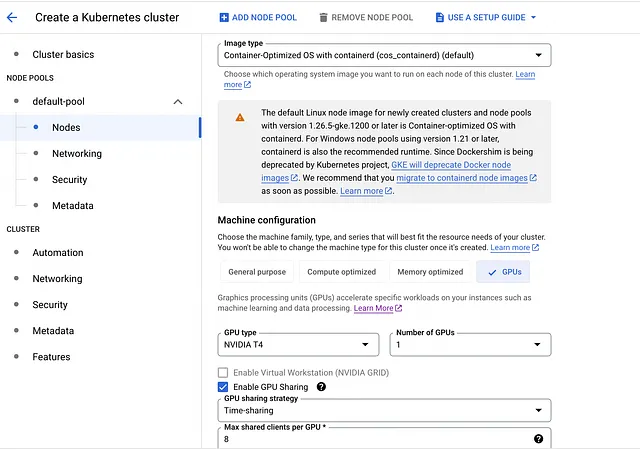
5. default-poolの左側のサイドバーでNodesタブをクリックします
- Machine ConfigurationをGeneral PurposeからGPUに変更します
- GPUの種類としてNvidia T4を選択し、数量に1を設定します
- GPUのタイムシェアを有効にします(この機能は使用しませんが)
- Max shared clients per GPUを8に設定します
- Machine Typeとしてn1-standard-4(4つのvCPU、15 GBのメモリ)を選択します
- Boot disk sizeを50に変更します
- 一番下までスクロールし、Enable nodes on spot VMsにチェックマークを入れます
![]()
このクラスターの推定価格のスクリーンショットを以下に示します:
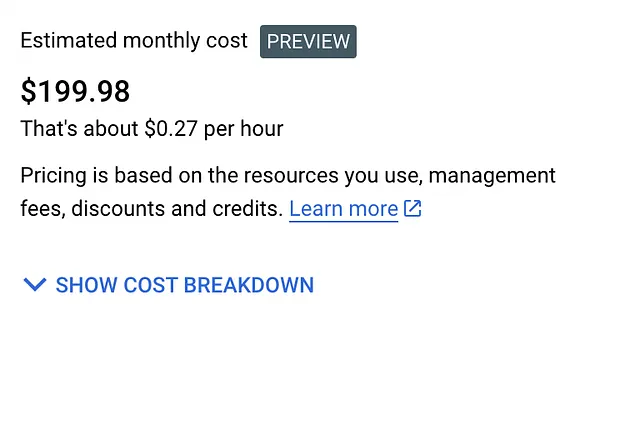
クラスターを設定したら、作成してください。
Googleがすべてをセットアップするには数分かかります。クラスターが起動して実行されたら、それに接続する必要があります。ターミナルを開き、次のコマンドを実行してください:
gcloud config set compute/zone us-central1-c
gcloud container clusters get-credentials gpu-cluster-1異なるゾーンのクラスター名を使用した場合は、それに応じて更新してください。接続されているかどうかを確認するには、次のコマンドを実行してください:
kubectl get nodesターミナルに1つのノードが表示されるはずです。クラスターにはGPUがありますが、いくつかのNvidiaドライバが不足しています。幸いにも、それらをインストールするのは簡単です。ドライバをインストールするには、次のコマンドを実行してください:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yamlすごい!ついにモデルをデプロイする準備が整いました。
モデルのデプロイ
モデルをクラスターにデプロイするには、kubernetes deploymentを作成する必要があります。kubernetes deploymentを使用すると、コンテナ化されたモデルのインスタンスを管理できます。kubernetesの詳細やyamlファイルの書き方については、範囲外なので深くは掘り下げません。
truss-falcon-deployment.yamlという名前のファイルを作成する必要があります。そのファイルを開き、以下の内容を貼り付けてください:
apiVersion: apps/v1kind: Deploymentmetadata: name: truss-falcon-7b namespace: defaultspec: replicas: 1 selector: matchLabels: component: truss-falcon-7b-layer template: metadata: labels: component: truss-falcon-7b-layer spec: containers: - name: truss-falcon-7b-container image: <your_docker_id>/falcon-7b-model:latest ports: - containerPort: 8080 resources: limits: nvidia.com/gpu: 1---apiVersion: v1kind: Servicemetadata: name: truss-falcon-7b-service namespace: defaultspec: type: ClusterIP selector: component: truss-falcon-7b-layer ports: - port: 8080 protocol: TCP targetPort: 8080何が起こっているのか:
- kubernetesに、
falcon-7b-modelのイメージでポッドを作成したいと伝えています。実際のIDには<your_docker_id>を置換してください。独自のDockerイメージを作成せずに私のものを使用したい場合は、次のものに置換してください:htrivedi05/truss-falcon-7b:latest - コンテナに対してGPUアクセスを有効にしています。これにより、コンテナに対して1つのGPUのみを要求するようにkubernetesに指示しています
- モデルとのインタラクションのために、ポート8080で実行されるkubernetesサービスを作成する必要があります
ターミナルで次のコマンドを実行してデプロイメントを作成してください:
kubectl create -f truss-falcon-deployment.yaml次のコマンドを実行すると:
kubectl get deployments次のような結果が表示されるはずです:
NAME READY UP-TO-DATE AVAILABLE AGE
truss-falcon-7b 0/1 1 0 8sデプロイメントが準備完了の状態に変わるまで数分かかることがあります。モデルはコンテナが再起動するたびにHugging Faceからダウンロードする必要がありますので、コンテナの進捗状況は次のコマンドを実行して確認できます:
kubectl get pods
kubectl logs truss-falcon-7b-8fbb476f4-bggtsポッド名を適宜変更してください。
ログで確認するべき項目がいくつかあります:
- printステートメントTHE DEVICE INFERENCE IS RUNNING ON IS: cudaが表示されているかどうか確認してください。これにより、コンテナが正しくGPUに接続されていることが確認されます。
- 次に、モデルファイルのダウンロードに関するいくつかのprintステートメントが表示されるはずです。
Downloading (…)model.bin.index.json: 100%|██████████| 16.9k/16.9k [00:00<00:00, 1.92MB/s]Downloading (…)l-00001-of-00002.bin: 100%|██████████| 9.95G/9.95G [02:37<00:00, 63.1MB/s]Downloading (…)l-00002-of-00002.bin: 100%|██████████| 4.48G/4.48G [01:04<00:00, 69.2MB/s]Downloading shards: 100%|██████████| 2/2 [03:42<00:00, 111.31s/it][01:04<00:00, 71.3MB/s]- モデルがダウンロードされ、Trussがマイクロサービスを作成したら、ログの最後に次の出力が表示されます:
{"asctime": "2023-06-29 21:40:40,646", "levelname": "INFO", "message": "Completed model.load() execution in 330588 ms"}このメッセージから、モデルがロードされ、推論に使用する準備ができていることが確認できます。
モデルの推論
モデルを直接呼び出すことはできません。代わりに、モデルのサービスを呼び出す必要があります。
次のコマンドを実行して、サービスの名前を取得します:
kubectl get svc出力:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.80.0.1 <none> 443/TCP 46m
truss-falcon-7b-service ClusterIP 10.80.1.96 <none> 8080/TCP 6m19struss-falcon-7b-serviceが呼び出したいサービスです。サービスにアクセスできるようにするには、次のコマンドを使用してポートフォワードする必要があります:
kubectl port-forward svc/truss-falcon-7b-service 8080出力:
Forwarding from 127.0.0.1:8080 -> 8080
Forwarding from [::1]:8080 -> 8080よし、モデルはREST APIエンドポイントとして127.0.0.1:8080で利用できます。任意のPythonスクリプト(例: main.py)を開き、次のコードを実行してください:
import requests
data = {"prompt": "Whats the most interesting thing about a falcon?"}
res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", json=data)
print(res.json())出力:
{'data': {'generated_text': 'Whats the most interesting thing about a falcon?\nFalcons are known for their incredible speed and agility in the air, as well as their impressive hunting skills. They are also known for their distinctive feathering, which can vary greatly depending on the species.'}}やったね!Falcon 7Bモデルを正常にコンテナ化し、本番環境でマイクロサービスとしてデプロイしました!
様々なプロンプトで遊んでみて、モデルが返す結果を自由に見てください。
クラスタの停止
Falcon 7Bをいじるのが楽しかったら、次のコマンドを実行してデプロイメントを削除できます:
kubectl delete -f truss-falcon-deployment.yaml次に、Google CloudのKubernetesエンジンに移動して、Kubernetesクラスタを削除してください。
注意:特に記載がない限り、すべての画像は著者によるものです
結論
ChatGPTのような本番向けモデルの実行と管理は簡単ではありません。しかし、時間の経過とともに、開発者が独自のモデルをクラウドにデプロイするためのツールが改善されていくでしょう。
このブログ記事では、LLMを基本的なレベルで本番環境にデプロイするために必要なすべての要素に触れました。モデルをTrussを使ってパッケージ化し、Dockerを使ってコンテナ化し、Kubernetesを使ってクラウド上にデプロイしました。理解するのに多くの内容があり、世界で一番簡単なことではありませんでしたが、それでもやり遂げました。
このブログ記事から何か面白いことを学んでいただけたら幸いです。読んでいただきありがとうございました!
それでは、ごきげんよう。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






