実験から展開へ MLflow 101 | パート01
実験から展開へ MLflow 101 | パート01
StreamlitとMLflowを使用してスパムフィルタを作成してMLOpsの旅を向上させよう

なぜ❓
イメージしてみてください:素晴らしいビジネスアイデアがあり、必要なデータがすぐそこにあります。素晴らしい機械学習モデルを作成するための準備が整っています🤖。しかし、実際のところ、この旅は簡単ではありません!大胆な実験、データ前処理、アルゴリズムの選択、ハイパーパラメータの調整など、目が回るほどの作業が待っています 😵💫。プロジェクトが難しくなるにつれて、それは煙を捕まえるようなものです – 途中で行ったすべての大胆な実験や素晴らしいアイデアを見失います。そして、それを覚えておくことは猫を羊飼いするよりも難しいです 😹
でも待ってください、それだけではありません!一度モデルを手に入れたら、それを一流のように展開する必要があります!常に変化するデータと顧客のニーズに対応するため、モデルを再トレーニングする回数は靴下を履き替える回数よりも多いでしょう!これは終わりのないジェットコースターのようなものであり、それをまとめるための堅牢なソリューションが必要です🔗。それがMLOpsです!これはカオスに秩序をもたらす秘密のソースです⚡
さて、皆さん、Whyの背後にある理由を理解したところで、このブログでのWhatとジューシーなHowに飛び込んでみましょう。
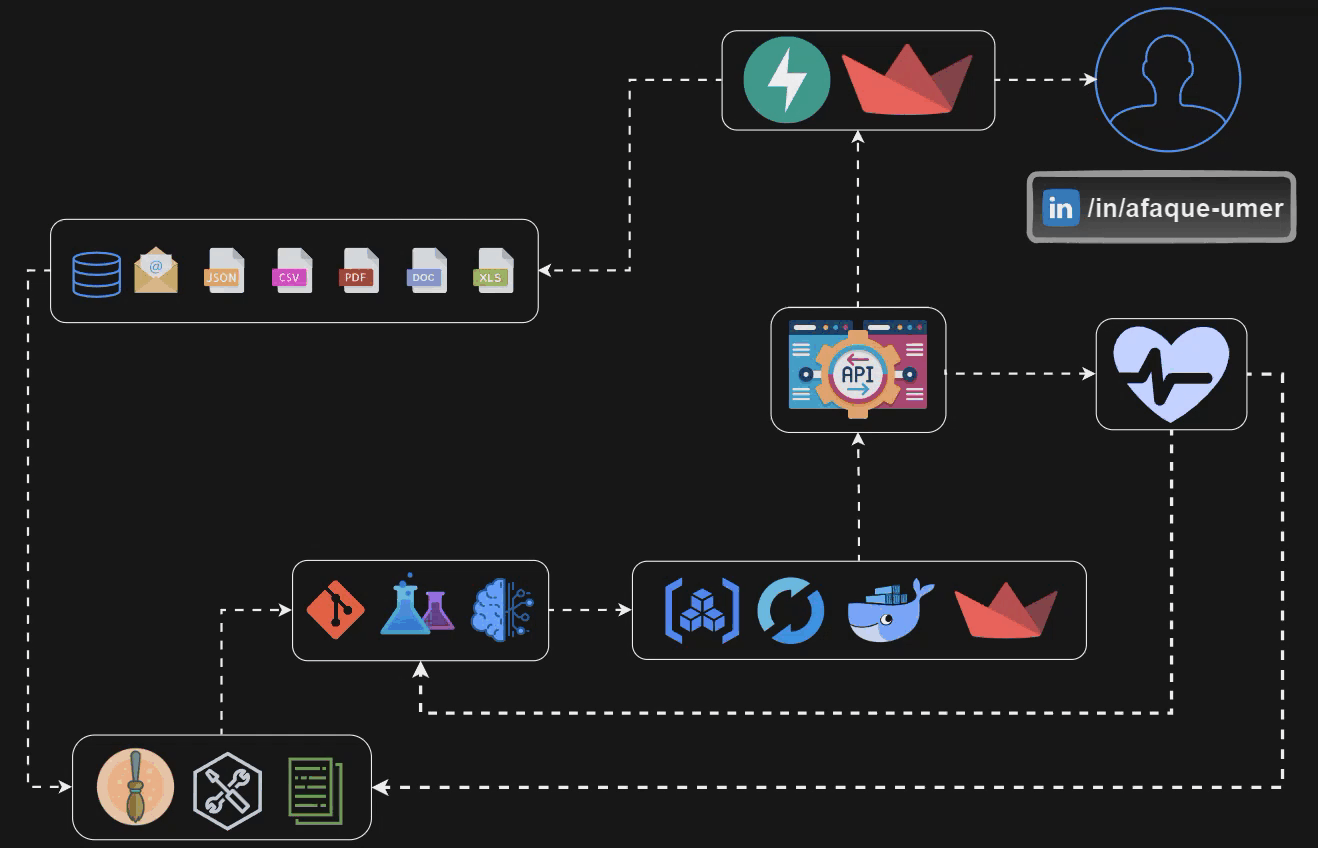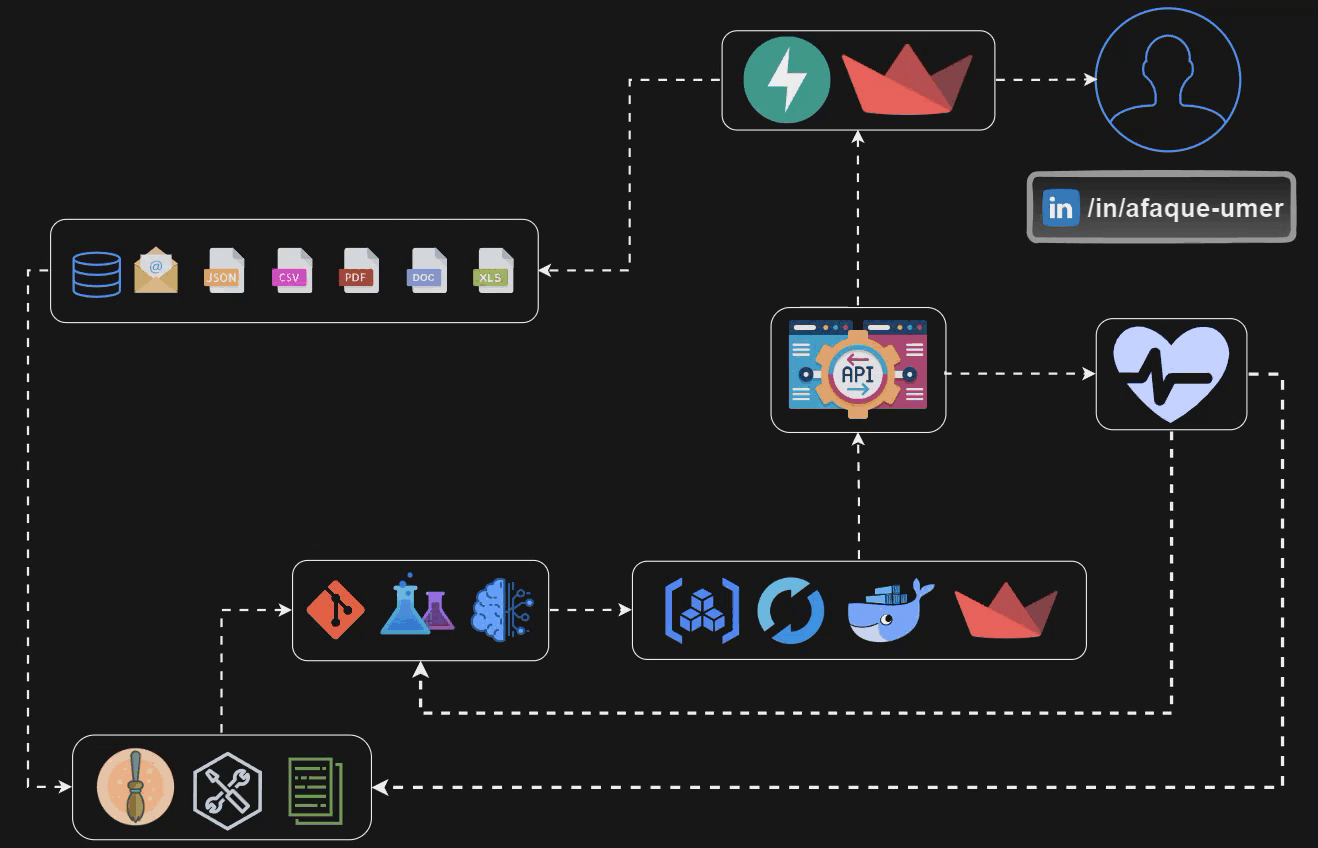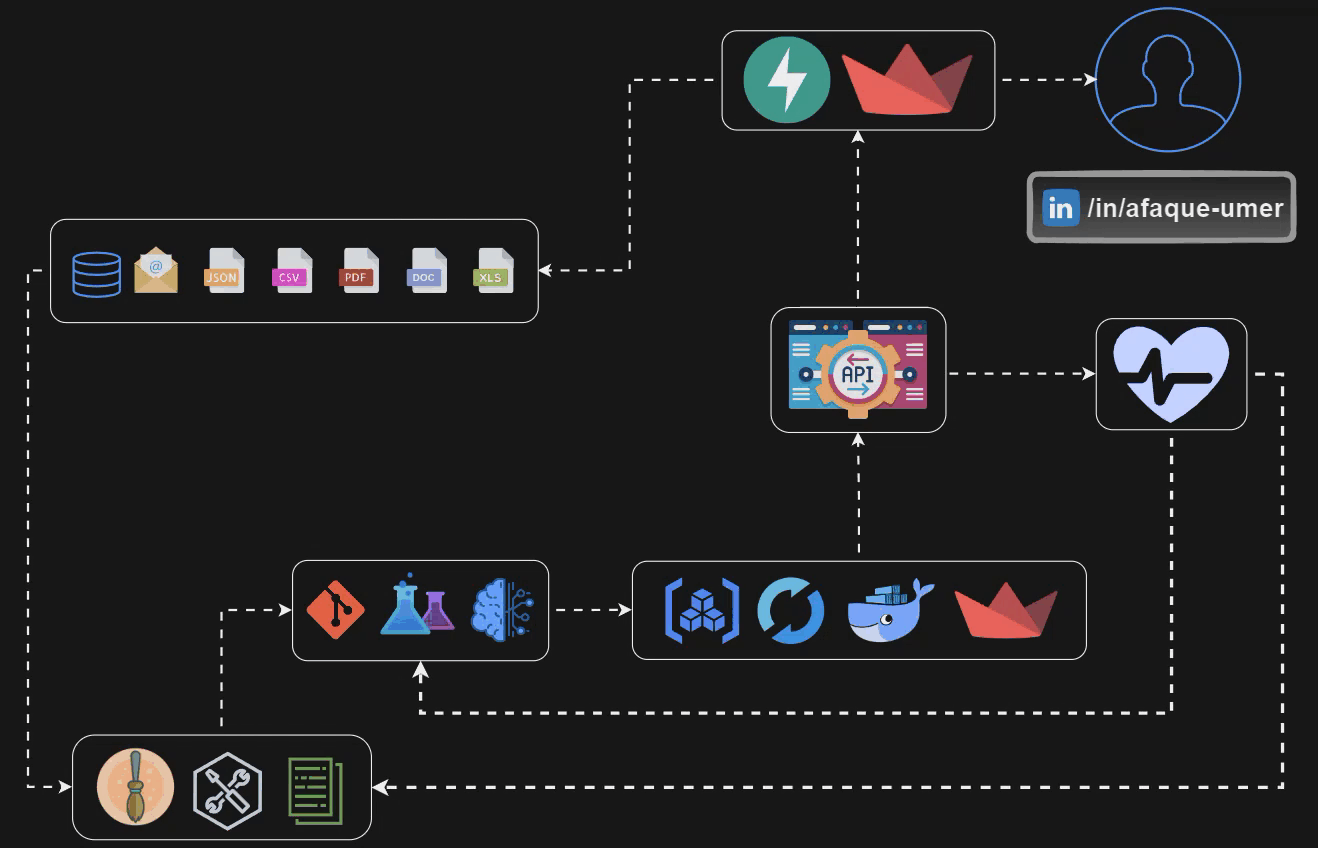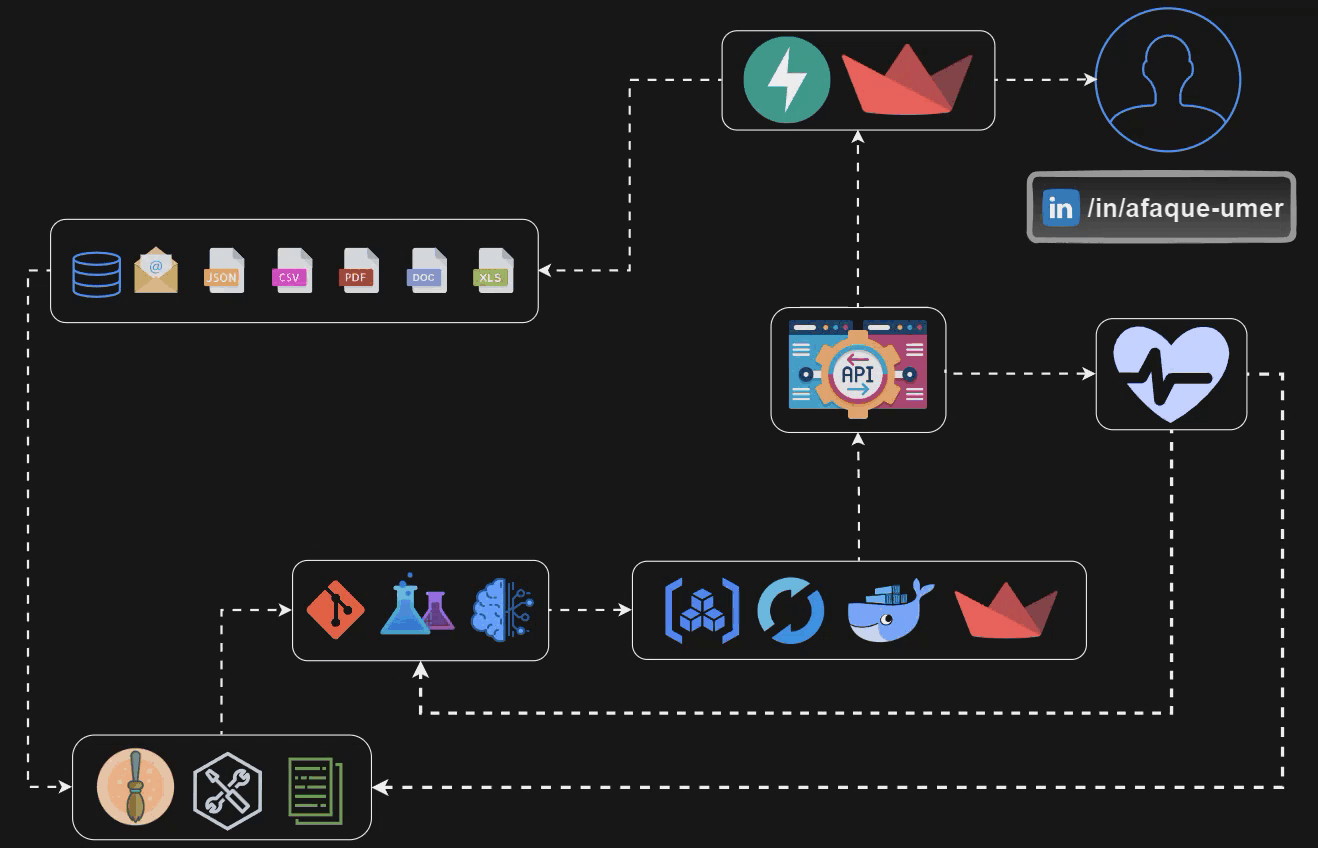
このブログの最後までに構築するパイプラインを見てみましょう👆
- 「3D MRIとCTスキャンに使用するディープラーニングモデルは何ですか?」
- タイムシリーズ分析:PythonにおけるARIMAモデル
- 「MetaGPTと出会ってください:GPTをエンジニア、建築家、マネージャに変えるオープンソースAIフレームワーク」
しっかりとつかまってください、これは素早い読み物ではありません!要点を押さえるためには重要な詳細が抜けてしまうでしょう。私たちはエンドツーエンドのMLOpsソリューションを作成しているため、3つのセクションに分ける必要がありますが、特定の出版ガイドラインのため、2つのブログ記事のシリーズとして分割することになります。
セクション1:基礎と理論を説明します📜
セクション2:ここがアクションの場所です!スパムフィルタを作成し、MLflowですべての大胆な実験を追跡します🥼🧪
セクション3:本当の取引に焦点を当てます – チャンピオンモデルの展開と監視、製品準備化を行います🚀
MLOpsでしっかりと進めましょう!
セクション1:基本事項 🌱
MLOpsとは❔
MLOpsは、データサイエンティストが大規模なプロダクション環境内でモデルのトレーニング、展開、管理ライフサイクルを簡素化し自動化するための方法論と業界のベストプラクティスの集合を表します。
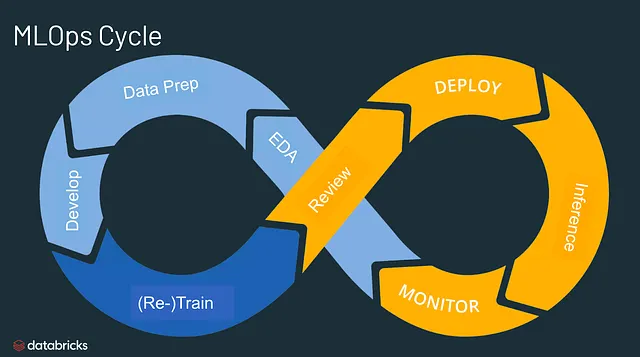
これは徐々に独自のアプローチとして浮かび上がり、マシンラーニング全体のライフサイクルを管理するための独立したアプローチとしての地位を確立しています。MLOpsプロセスの基本的なステージには、次のものが含まれます:
- データ収集:分析のために異なるソースから関連するデータを収集する。
- データ分析:収集したデータを探索し、洞察を得る。
- データ変換/準備:データをクリーニングし、変換し、モデルのトレーニングのために準備する。
- モデルのトレーニングと開発:準備したデータを使用して機械学習モデルを設計および開発する。
- モデルの検証:モデルのパフォーマンスを評価し、正確性を確保する。
- モデルのサービング:トレーニングしたモデルを実際の予測のために展開する。
- モデルの監視:プロダクションでモデルのパフォーマンスを継続的に監視し、効果を維持する。
- モデルの再トレーニング:新しいデータでモデルを定期的に再トレーニングして最新かつ精度を保つ。
どのように実装するのか? Neptune、Comet、Kubeflowなど複数のオプションがありますが、私たちはMLflowを使います。それでは、MLflowについて詳しく説明していきましょう。
MLflow 101
MLflowは、機械学習のスイスアーミーナイフのようなものです。とても多機能でオープンソースであり、ボスのようにあなたのMLの全体的な旅を管理するのに役立ちます。TensorFlow、PyTorch、Scikit-learn、spaCy、Fastai、Statsmodelsなどの主要なMLライブラリとも相性が良いです。それだけでなく、他のライブラリ、アルゴリズム、またはデプロイメントツールとも使用できます。さらに、カスタムプラグインを使用して新しいワークフロー、ライブラリ、ツールを簡単に追加できるように設計されています。

MLflowは、モジュール化されたAPIベースのデザイン思想に従い、その機能を4つの異なるパートに分けています。

それでは、これらのパートを1つずつ見ていきましょう!
MLflow Tracking:これは、機械学習の実行中にパラメータ、コードバージョン、メトリクス、アーティファクトを記録し、後で結果を視覚化するためのAPIとUIです。任意の環境で動作し、ローカルファイルまたはサーバーにログインして複数の実行を比較することができます。チームは、異なるユーザーの結果を比較するためにもそれを利用することができます。Mlflow Projects:これは、データサイエンスのコードを簡単にパッケージ化して再利用する方法です。各プロジェクトは、コードまたはGitリポジトリと、依存関係と実行命令を指定する記述子ファイルで構成されています。MLflowは、Tracking APIを使用するとプロジェクトのバージョンとパラメータを自動的に追跡し、GitHubやGitリポジトリからプロジェクトを実行し、それらをマルチステップのワークフローに連結するのが簡単になります。Mlflow Models:これは、さまざまなフレーバーで機械学習モデルをパッケージ化し、デプロイするための機能を提供します。各モデルは、サポートされるフレーバーがリストアップされた記述子ファイルを含むディレクトリとして保存されます。MLflowは、DockerベースのRESTサーバー、Azure ML、AWS SageMaker、およびバッチおよびストリーミング推論のためのApache Sparkなど、一般的なモデルタイプをさまざまなプラットフォームに展開するためのツールを提供します。MLflow ModelsをTracking APIを使用して出力すると、MLflowはそれらの出所、プロジェクトや実行元なども自動的に追跡します。Mlflow Registry:これは、MLflowモデルのライフサイクル全体を共同で管理するためのAPIとUIを備えた中央集権型のモデルストアです。モデルのラインナップ、バージョン管理、ステージの移行、および効果的なモデル管理のための注釈などが含まれています。
これで、MLflowの提供する基本的な理解について説明しました。さらなる詳細については、公式ドキュメントを参照してください👉📄。これらの知識を武器にして、次のセクションに進みましょう。まずは、シンプルなスパムフィルターアプリを作成し、それからユニークな実行でさまざまな実験を追跡してみましょう!
セクション2:実験🧪と観察🔍
さあ、みなさん、エキサイティングな旅に備えましょう!実験に没頭して手を汚す前に、私たちが何を構築しているのかを明確にするための攻略計画を立てましょう。まず最初に、ランダムフォレスト分類器を使用してスパム分類器を作成します(ドキュメント分類にはMultinomial NBの方が良いとわかっていますが、ランダムフォレストのハイパーパラメータで遊びたいのです)。最初はあえてあまり良くないものにしますが、そのスリルのために。そして、Bag of WordsやTfidfなどのクールなものを使ってハイパーパラメータを調整し、さまざまな実験を追跡します。そして、なんと?すべてのトラッキングアクションにMLflow UIをボスのように使用し、次のセクションに備えます。準備はいいですか?楽しい時間を過ごしましょう!🧪💥
データとの一体化 🗃️
このタスクでは、Kaggleで利用可能なSpam Collectionデータセットを使用します。このデータセットには、ハム(正規)またはスパムとしてタグ付けされた5,574件の英語のSMSメッセージが含まれています。ただし、データセットには約4,825件のハムラベルの偏りがあります。逸脱を避け、簡潔にするために、私はいくつかのハムサンプルを削除し、約3,000件に減らし、モデルとテキストの前処理でのさらなる使用のために結果のCSVを保存しました。必要に応じてアプローチを選択してください-これは簡潔さのためだけのものです。これが私がこれを達成した方法を示すコードの一部です。
基本的なスパム分類器の構築 🤖
さあ、データが準備できましたので、さっそく基本的な分類器を構築しましょう。テキスト言語をコンピュータが理解できないという古い決まり文句で退屈させるつもりはありませんので、テキスト表現のためにベクトル化する必要があります。それが完了したら、それをML/DLアルゴリズムにフィードし、リフレッシャーが必要か疑問がある場合は心配しないでください-参照するために以前のブログのいずれかでカバーしています。もう知っていますよね? 🤗
回帰モデルのマスタリング:予測分析の包括的なガイド
イントロダクション
levelup.gitconnected.com
さて、本題に入りましょう!データを読み込み、メッセージを前処理してストップワードや句読点などを削除します。さらに、ステミングやレンマ化なども行います。そして、興奮のパートがやってきます-データをベクトル化して素晴らしい特徴を得ることです。次に、トレーニングとテストのためにデータを分割し、ランダムフォレスト分類器に適合させ、テストセットで素晴らしい予測を行います。最後に、モデルのパフォーマンスを確認する評価の時間です!ウォーク・ザ・トークしてみましょう ⚡
このコードでは、ストップワードの有無、レンマ化、ステミングなどの前処理についての実験のためのコメントとしていくつかのオプションを提供しています。同様に、ベクトル化にはBag of Words、TF-IDF、埋め込みのいずれかを選択できます。さて、楽しい部分に入りましょう!これらの関数を順番に呼び出し、ハイパーパラメータを渡すことで最初のモデルをトレーニングします。
そうですね、完全に同意します。このモデルはほとんど役に立たないですね。適合率がほぼゼロなので、F1スコアもほぼ0になります。わずかなクラスの不均衡があるため、F1スコアは精度よりも重要となり、適合率と再現率の総合的な尺度を提供します-それがその魔法です!では、これが私たちの最初のひどく無意味で役に立たないモデルです。でもね、心配することはありません、それは学習の旅の一部です 🪜。
さあ、MLflowを起動して、さまざまなオプションとハイパーパラメータで実験を始めましょう。ものごとを微調整すると、すべてが意味を持ち始めます。進捗状況をプロのように視覚化し、分析することができるようになります!
MLflowのはじめ方 ♾️
まず第一に、MLflowを起動しましょう。整理された状態を保つために、仮想環境をセットアップすることをおすすめします。単純に、pipを使用してMLflowをインストールできます 👉pip install mlflow
インストールが完了したら、ターミナルで 👉mlflow ui を実行してMLflow UIを起動します(インストールしたMLflowの仮想環境内で実行していることを確認してください)。これにより、MLflowサーバーがローカルブラウザでhttp://localhost:5000にホストされるMLflowサーバーが起動します。次のようなページが表示されます 👇

まだ何も記録していないので、UI上で確認するものはあまりありません。MLflowには、ローカル、データベース付きのローカル、サーバー上、またはクラウド上など、いくつかのトラッキングオプションがあります。このプロジェクトでは、今のところすべてをローカルにしておきます。ローカルセットアップの使い方を把握したら、トラッキングサーバーURIを渡したり、いくつかのパラメータを設定することは後でできます-基本原則は同じままです。
さあ、楽しい部分に入っていきましょう — メトリクス、パラメータ、さらにはモデル、視覚化、または他のオブジェクト(アーティファクトとも呼ばれます)を保存することです。
MLflowのトラッキング機能は、機械学習開発の文脈における従来のログ記録の進化または置き換えと見なすことができます。従来のログ記録では、ハイパーパラメータ、メトリクス、およびその他の関連する詳細などの情報をモデルのトレーニングと評価中に記録するために、通常はカスタムの文字列フォーマットを使用します。このログ記録のアプローチは、大量の実験や複雑な機械学習パイプラインを扱う際に煩雑でエラーが発生しやすくなることがあります。それに対して、Mlflowはこの情報の記録と整理のプロセスを自動化し、実験の管理と比較を容易にし、より効率的で再現可能な機械学習ワークフローを実現します。
Mlflow トラッキング 📈
Mlflow トラッキングは、パラメータを記録するためのlog_param、メトリクスを記録するためのlog_metric、およびアーティファクト(モデルファイルや視覚化など)を記録するためのlog_artifactという3つの主要な機能を中心にしています。これらの機能は、機械学習開発プロセス中の実験に関連するデータの整理と標準化されたトラッキングを容易にします。
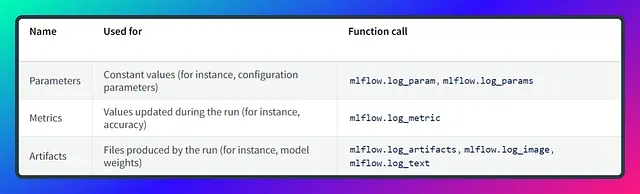
単一のパラメータをログ記録する場合、キーと値のペアをタプル内に記録します。一方、複数のパラメータを扱う場合は、キーと値のペアを持つ辞書を使用します。メトリクスのログ記録にも同じコンセプトが適用されます。以下は、このプロセスを示すコードのスニペットです。
# パラメータをログ記録する(キーと値のペア)
log_param("config_value", randint(0, 100))
# パラメータの辞書をログ記録する
log_params({"param1": randint(0, 100), "param2": randint(0, 100)})実験 🧪 とラン 🏃♀️ の理解
実験は、共通の目的を持つ関連する機械学習ランのグループを表すコンテナとして機能し、ランに対して論理的なグループ化を提供します。各実験には固有の実験IDがあり、使いやすい名前を割り当てることができます。
一方、ランは実験内での機械学習コードの実行に対応します。単一の実験内で異なる設定を持つ複数のランを持つことができ、各ランには固有のランIDが割り当てられます。パラメータ、メトリクス、およびアーティファクトなどのトラッキング情報は、ローカルファイルシステム、データベース(SQLiteやMySQLなど)、またはリモートクラウドストレージ(AWS S3やAzure Blob Storageなど)などのバックエンドストアに保存されます。
MLflowは、使用しているバックエンドストアに関係なく、これらの実験の詳細情報をログ記録して追跡するための統一されたAPIを提供しています。この統合アプローチにより、実験結果の簡単な取得と比較が可能となり、機械学習開発プロセスの透明性と管理性が向上します。
はじめに、mlflow.create_experiment()またはより簡単なメソッドであるmlflow.set_experiment("your_exp_name")を使用して実験を作成することができます。名前が指定されている場合は既存の実験を使用し、それ以外の場合は新しい実験が作成されてランの記録に使用されます。
次に、mlflow.start_run()を呼び出して現在のアクティブなランを初期化し、ログ記録を開始します。必要な情報をログ記録した後は、mlflow.end_run()を使用してランを閉じます。
以下は、このプロセスを示す基本的なスニペットです。
import mlflow# 実験を作成する(または既存の実験名を使用する)
mlflow.set_experiment("your_exp_name")# ランを開始し、ログ記録を開始する
with mlflow.start_run(): # ここでパラメータ、メトリクス、アーティファクトをログ記録する mlflow.log_param("param_name", param_value) mlflow.log_metric("metric_name", metric_value) mlflow.log_artifact("path_to_artifact")# 'with'ブロックの終わりでランは自動的に閉じられるStreamlitを使用したハイパーパラメータ調整のためのUIの作成🔥
シェルを介してスクリプトを実行し、そこでパラメータを指定する代わりに、ユーザーフレンドリーなアプローチを選択します。実験名または特定のハイパーパラメータ値を入力できる基本的なUIを作成します。トレーニングボタンがクリックされると、指定された入力でトレーニング関数が呼び出されます。さらに、保存されたランが多くなった場合に実験とランをクエリする方法も探ります。
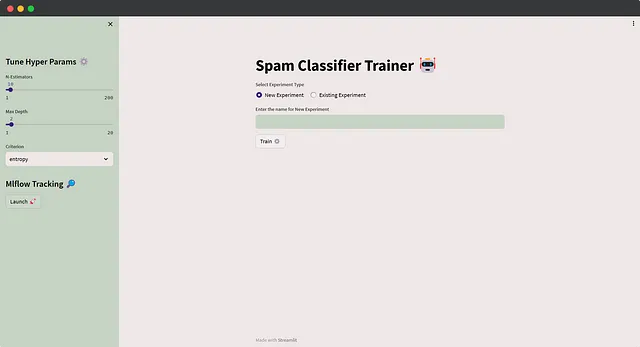
このインタラクティブなUIを使用すると、ユーザーは簡単に異なる設定を試して、より効率的な機械学習の開発を追跡することができます。コードは直感的なので、Streamlitの詳細には触れません。MLflowのログ記録のために以前のトレーニング関数にわずかな調整を加え、カスタムのテーマ設定も実装しました。実験を実行する前に、ユーザーは新しい実験名を入力するか(その実験の実行を記録する)、またはドロップダウンメニューから既存の実験を選択するように求められます。このドロップダウンメニューは、mlflow.search_experiments()を使用して生成されます。さらに、ユーザーは必要に応じて簡単にハイパーパラメータを微調整することができます。以下はアプリケーションのコードです👇
そして、アプリケーションの見た目は以下のようになります🚀
さて、一時的なお別れの時です👋、でも心配しないでください – 次回のブログシリーズのインストールメントで再会しましょう🤝。次のパートでは、実験に飛び込んでモデルをケージファイトに投入し、最高のものだけがMLflow Trackingのコロシアムで栄えるでしょう🦾。一旦流れに乗れば、一時停止したくなくなること間違いなしですので、コーヒーを飲んで🍵、充電して🔋、次のエキサイティングなチャプターに参加してください⚡。以下はPart 02へのリンクです👇
VoAGI
説明を編集する
pub.towardsai.net
そこでお会いしましょう👀
読んでいただきありがとうございます🙏最高のパフォーマンスを続けましょう🤘学び続けましょう🧠情報を共有し続けましょう🤝そして何より実験を続けましょう!🧪🔥✨😆
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






