実験から展開へ:MLflow 101 | パート02
実験から展開へ:MLflow 101 | パート02
StreamlitとMLflowを使用してスパムフィルターを作成してMLOpsの旅を向上させよう

こんにちは👋、このブログの第2セグメントへようこそ!最初から一緒にいた場合、前回はハイパーパラメータチューニングを簡素化するためのユーザーインターフェースを作成しました。では、前回の続きから始めましょう ⛔ ただし、ここに初めて来たばかりの場合は心配しないでください!このブログの第01部をここでチェックアウトすることで追いつくことができます👇
実験から展開まで:MLflow 101
StreamlitとMLflowを使用してスパムフィルターを作成してMLOpsの旅を向上させよう
pub.towardsai.net
セクション2:実験と観察 [続行…]
MLflowを使用した実験トラッキング📊
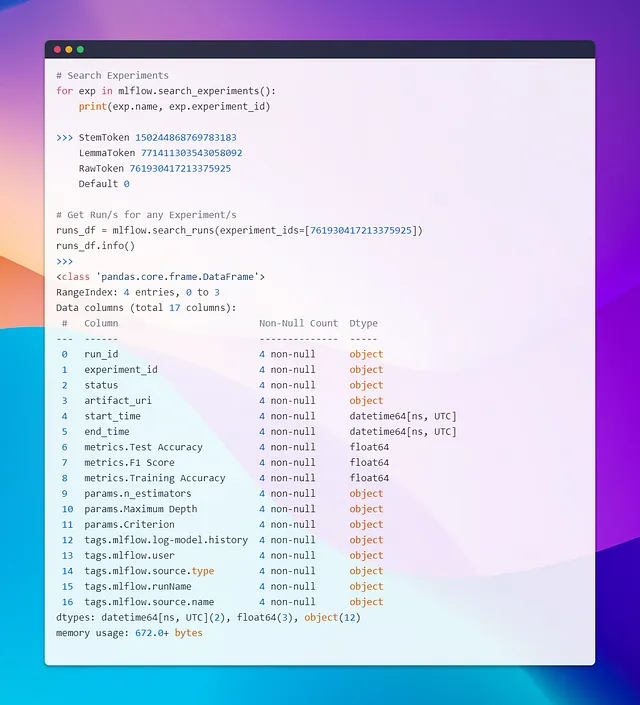
アプリが準備できたので、実験に進みましょう。最初の実験では、ステミングやレンマ化せずに単語をそのまま使用し、ストップワードと句読点の除去にのみ焦点を当て、テキストデータのテキスト表現にBag of Words(BOW)を適用します。次に、連続した実行でいくつかのハイパーパラメータを微調整します。この実験をRawTokenと名付けます。
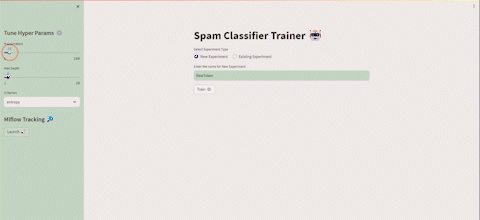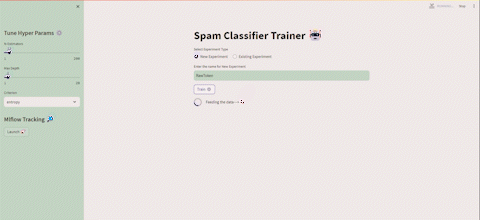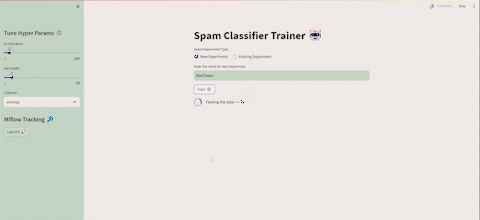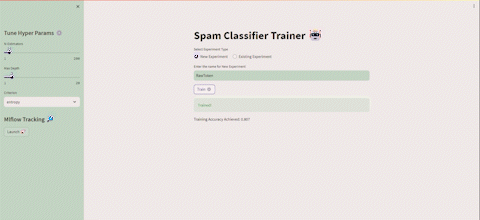
いくつかの実行を実行した後、Streamlit UIからMLflowを起動することができ、次のように表示されます👇
- OpenAIは、GPTBotを導入しましたこれは、インターネット全体からデータを自動的にスクレイピングするために設計されたウェブクローラです
- トランスフォーマーによるOCRフリーの文書データ抽出(2/2)
- 「データサイエンスの観点からFCバルセロナのディフェンスを分析する」
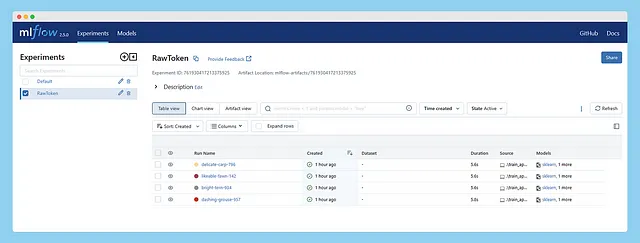
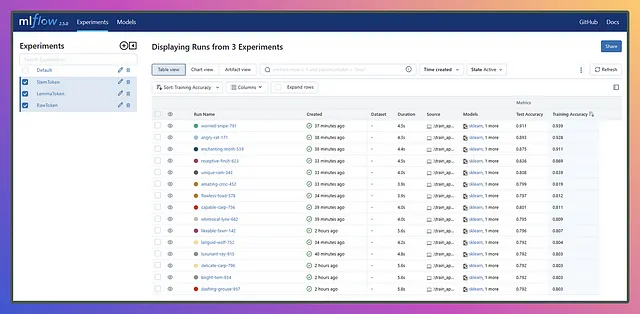
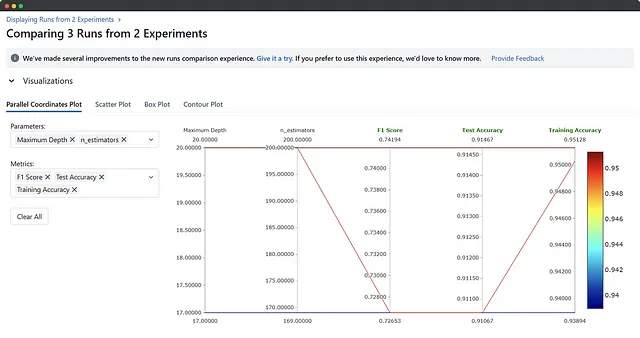
よし、今はExperimentsの下にRawToken実験がリストされ、Run列の下に一連の実行があります。実行のいくつか、複数、またはすべてを選択し、比較ボタンを押して結果を並べて表示できます。比較セクションに入ると、比較または視覚化したいメトリックやパラメータを選択できます。
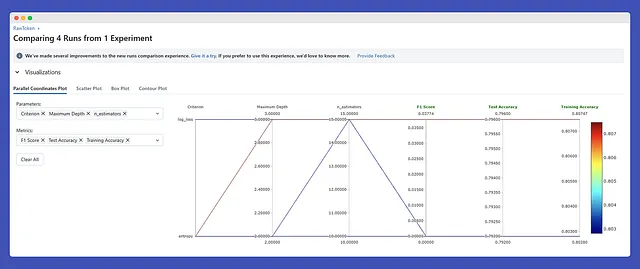
思った以上に探索する項目があり、何を探しているのか、なぜそれを探しているのかがわかれば、最善のアプローチがわかります!

よし、1つの実験が完了しましたが、思ったような結果になりませんでしたが、それは大丈夫です!今度は少なくともいくつかのF1スコアを持つ結果を得るためにいくつかの実験を行う必要があります。生のトークンを使用し、ツリーの数と深さをかなり低く保ちましたので、このようなことが起こることは分かっていました。したがって、ステミングを使用した実験とレンマ化を使用した実験の2つに取り組みましょう。これらの実験では、さまざまなテキスト表現技術と組み合わせたさまざまなハイパーパラメータを試してみます。
ここではフルプロモードにはなりません。私たちの目的は異なるため、Gitの統合は実装していませんので、友好的な注意としてお知らせします。Gitを使用して実験を追跡することは理想的ですが、コードの変更が必要になります。既にコメントアウトしています。MLflowはGitも追跡できますが、それを追加すると余分なスクリーンショットが発生します。Gitにはあなたがウィザードであることを知っているので、その部分はあなたに任せます!
さて、これで新しい実験を追加し、それら内のいくつかの実行を記録するためにコードを手動でコメントアウトして解除しましょう。私が言ったことをすべて実行した後、以下が実験とその結果です。どうなるか見てみましょう!🚀🔥
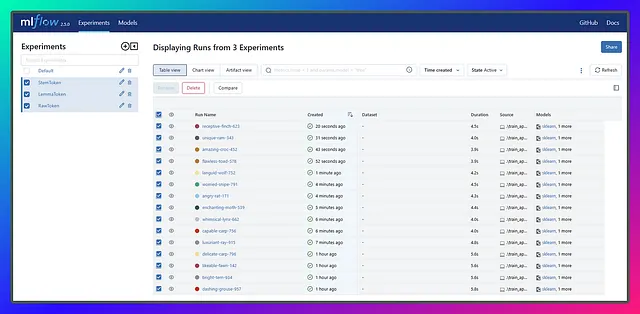
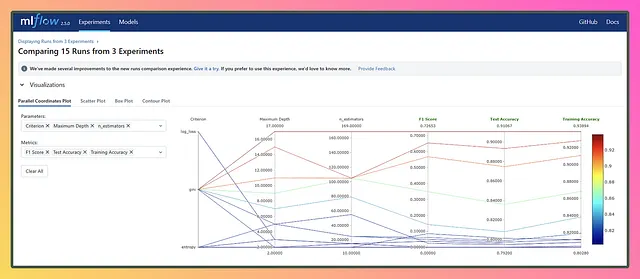
さて、実験が終わったので、実行結果は少し乱雑で混沌としているかもしれません。まるで現実のユースケースのようですね。これを手動で行うことを想像してみてください。悪夢であり、付箋が枯渇するか、絶え間ない量の鎮痛剤が必要になるかもしれません!しかし、MLflowのおかげで、私たちはカバーされ、乱れた実験からきれいで整理されたソリューションを得ることができます。MLflowの魔法を評価しましょう!🧙♀️✨
実験→RunIDをクエリでモデルを選択する🎯
さて、いくつかの実験が完了し、特定の実験と実行からモデルをロードする必要があるとしましょう。目的は、run_idを取得し、そのrun idに関連付けられたアーティファクト(モデルとベクトル化器)をロードすることです。これを達成するための1つの方法は、実験を検索し、そのIDを取得し、それらの実験内で実行を検索することです。精度などのメトリックに基づいて結果をフィルタリングし、必要なrun idを選択することができます。その後、MLflowの関数を使用してアーティファクトを読み込むことができます。
簡単なオプションとして、MLflowのUIを直接使用することもできます。結果を降順で比較し、最も上位の結果からrun idを取得し、プロセスを繰り返すことができます。
もう1つの簡単で標準的な方法は、モデルを本番環境に展開することです。これについては、ブログの最後のセクションで説明します。
最初のアプローチの意図は、MLflowの組み込み機能ではなく、カスタムのダッシュボードやプロットが必要な場合に、実験クエリに慣れさせることです。MLflowのUIを使用すると、特定のニーズに合わせて簡単にカスタムの可視化を作成することができます。MLflowの旅をさらに効率的かつ効果的にするためのさまざまなオプションを探索することが重要です!
run_idを取得したので、モデルをロードし、さまざまなAPIを使用して予測を実行することができます。MLflowは、異なるライブラリ用にflavorsと呼ばれる特定の形式を利用しています。独自のカスタムフレーバーを作成することもできますが、それは別のトピックです。いずれにせよ、MLflowでモデルをクリックすると、ロード方法に関する手順が表示されます。
さて、モデルの1つをロードしてクイック予測を実行し、実際に動作するかどうかを見てみましょう!
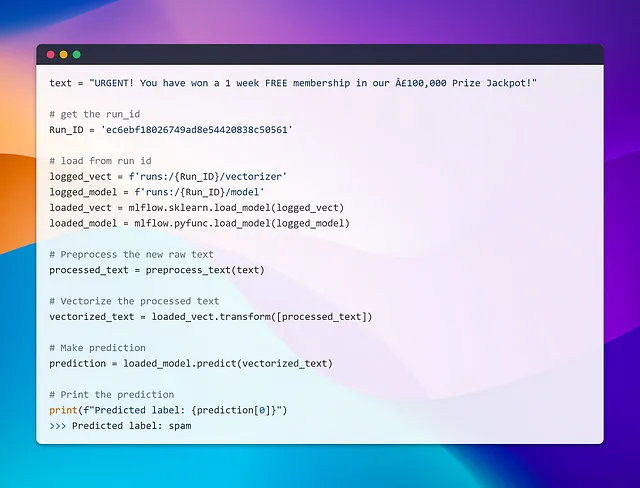
おおっ!それはスムーズでした!15回の異なるランからモデルをロードするのは簡単でした。ランIDを提供するだけで、複雑なパスを覚える必要もありませんでした。でも待ってください、それだけですか?モデルをサーブしたりデプロイする方法はどうなるのでしょうか?次のセクションでモデルのデプロイとサービス提供の世界に飛び込んでみましょう。
セクション3: モデルの本番デプロイ 🚀
最後のセクションへようこそ!時間を無駄にすることなく、すぐに始めましょう。使用するモデルを決めたら、残りは単に選択してユニークなモデル名で登録するだけです。以前のMLflowのバージョンでは、モデルの登録にはデータベースが必要でしたが、もはや必要ありません。今ではそれよりも簡単で、私はそれについて少し書くだけで済みます。
最良のモデルの登録 🎖️
重要なポイントは、モデル名をシンプルでユニークに保つことです。この名前は、再学習やモデルの更新などの将来のタスクにとって重要です。良いメトリクスを持つ成功した実験から得られた新しいモデルがある場合は、同じ名前で登録します。MLflowは自動的に新しいバージョンでモデルをログに記録し、更新し続けます。
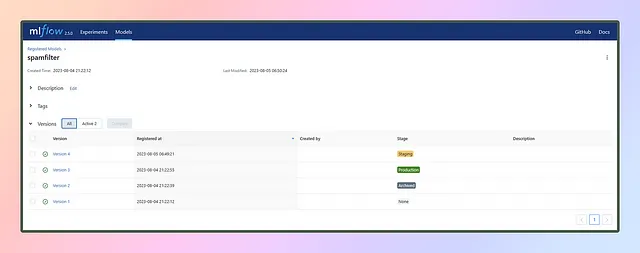
このセクションでは、テスト精度のチャートに基づいて3つのモデルを登録します:一つは一番下に、もう一つは中央に、そして最後の一つは一番上に。モデル名はspamfilterとします。
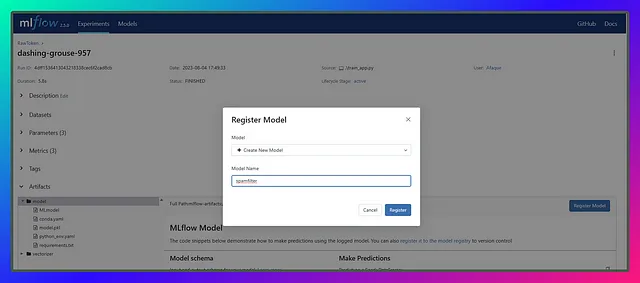
異なるランのモデルを同じモデル名の下で登録すると、以下のようにバージョンが追加されます👇
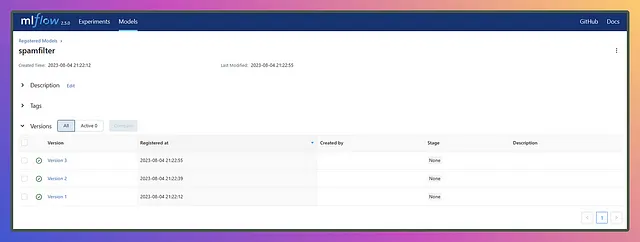
では、モデルを登録したら終わりなのでしょうか?答えはノーです!モデルの登録は機械学習ライフサイクルの一部であり、それからMLOps、具体的にはCI/CDパイプラインが登場します。

MLflowにモデルを登録した後、次のステップは通常次のようなものです:⚠️理論が先に進みます⚠️
- ステージングと検証 🟨: デプロイメントの前に行われ、登録されたモデルはテストと検証を経ます。このステップでは、モデルが期待通りに動作し、必要な品質基準を満たすことを確認します。
- デプロイメント 🟩: 成功した検証の後、モデルは本番環境またはサービングインフラストラクチャにデプロイされます。モデルはエンドユーザーやアプリケーションからアクセス可能となり、リアルタイムの予測を提供します。
- モニタリングとメンテナンス ⛑️: モデルが本番環境にある場合、そのパフォーマンスを定期的にモニタリングすることが重要です。モニタリングにより、モデルのパフォーマンスの変化やデータ分布の変化、または実際の使用時に発生する可能性のある問題を検出することができます。モデルの定期的なメンテナンスと更新が必要な場合もあり、これにより正確な結果を提供し続けることができます。
- 再学習 ⚙️: 新しいデータが利用可能になると、定期的なモデルの再学習が重要になります。これにより、モデルを最新の状態に保ち、パフォーマンスを向上させることができます。最近の例として、GPT-4は時間の経過と共にパフォーマンスが低下し始めました。このようなシナリオでは、MLflowのトラッキング機能が役立ちます。様々なモデルバージョンを追跡することで、モデルの更新と再学習が簡素化され、データが進化するにつれて効率的で正確なモデルを保つことができます。
- モデルのバージョニング 🔢: 以前に見たように、新しいモデルを登録すると、MLflowは自動的にバージョン管理します。再学習または新たに学習されたモデルの場合、バージョン管理が行われ、ステージングステージを経ます。モデルが必要なすべてのチェックをパスすれば、本番用にステージングされます。ただし、モデルのパフォーマンスが低下した場合、MLflowのモデルバージョニングと履歴の追跡が助けになります。必要に応じて以前のモデルバージョンに簡単に戻ることができ、より信頼性の高い正確なモデルに戻すことができます。この機能により、モデルのパフォーマンスを維持し、ユーザーやアプリケーションに最良の結果を提供するための調整が容易に行えます。
- フィードバックループと改善: ユーザーフィードバックとパフォーマンスモニタリングデータを活用することで、モデルの継続的な改善が可能です。実世界での使用から得られる洞察により、反復的な洗練と最適化が行われ、モデルが時間と共により良い結果を提供するように進化します。
さて、それではいいですね!チャットや理論の専門用語はもう終わりです!それに退屈はこのパーティーには招待されていません。コードを解き放ちましょう⚡ さあ、手を汚して本当の楽しみをしましょう! 🚀💻。ここでは一人で作業しているので、品質やテストチームの制約に縛られることはありません 😉。イエローステージ(検証のためのステージ)の重要性を完全に理解していないため、私はリスクを冒して直接グリーンステージに移動します。実際のシナリオではこのアプローチは危険かもしれませんが、私の実験的な世界では、チャンスを取る覚悟があります。
それでわずかなクリックで、バージョン3モデルのステージを本番に設定し、本番モデルをクエリする方法を探ってみましょう。
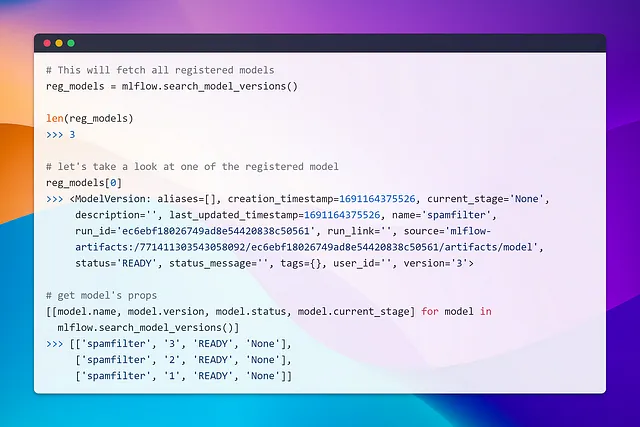
同様に、クエリを実行し、条件current_stage == ‘Production’でフィルタリングすることでモデルを取得できます。前のセクションで行ったように、model.run_idを使用して進めることができます。学んだことを活用することが重要です! 💡
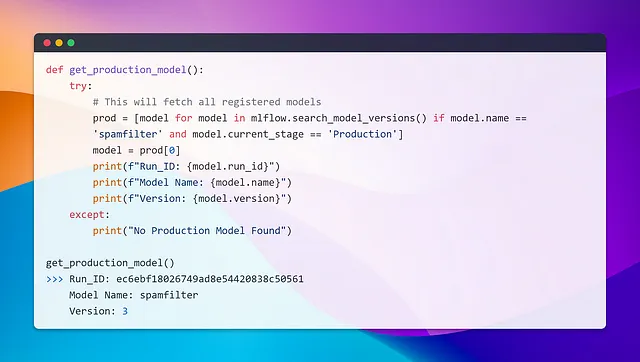
また、次のスニペットを使用して本番モデルをロードすることもできます。
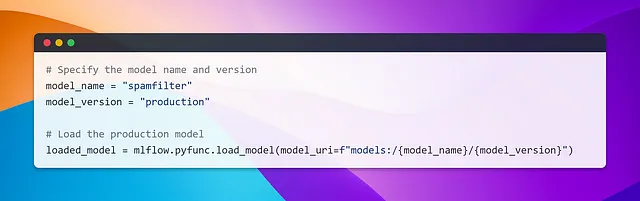
ユーザ予測のためのStreamlit UIの構築
本番モデルが展開されたので、次のステップはAPIを介してそれを提供することです。MLflowは、ログされたモデルを使用して予測を行うためのデフォルトのREST APIを提供していますが、カスタマイズオプションは限られています。より制御と柔軟性を持つために、FastAPIやFlaskなどのウェブフレームワークを使用してカスタムエンドポイントを構築することができます。
デモンストレーションのために、再びStreamlitを使用して、本番モデルに関する情報をいくつか紹介します。さらに、実験からの新しいモデルが以前のモデルよりも優れたパフォーマンスを発揮した場合、前のモデルを置き換える可能性があります。以下は、user_app.pyという名前のユーザアプリケーションのコードです。

アプリのUIはこんな感じになります 😎
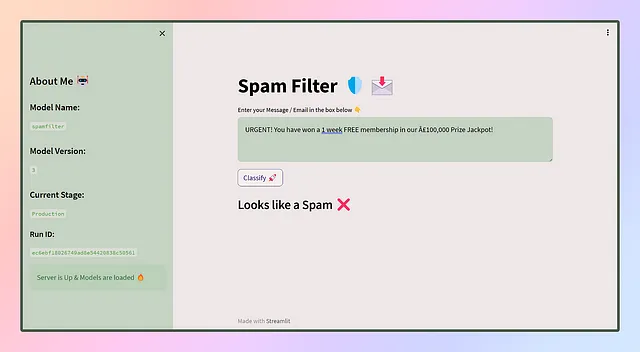
わあ、最初のアプリを成功裏に展開しました!しかし、待ってください、旅はここで終わりません。アプリがユーザに提供されると、彼らはさまざまなデータを使用してそれとやり取りし、さまざまな予測結果が得られます。これらの予測結果は、フィードバック、評価などのさまざまな手段で記録されます。ただし、時間の経過とともに、モデルの効果が低下することがあります。その場合は再トレーニングの時が来たのです。
再トレーニングでは、初期段階に戻り、新しいデータやアルゴリズムを使用してモデルのパフォーマンスを向上させることがあります。
再トレーニングした後、新しいモデルを本番モデルと比較テストし、大幅な改善が見られれば、検証と品質チェックのためにステージング🟨エリアに並べられます。
承認が得られ次第、本番🟩ステージに移行し、現在のモデルと置き換えます。前の本番モデルは⬛でアーカイブされます。
注意: 私たちは本番環境で複数のモデルを同時にデプロイする柔軟性を持っています。これは、特定のサブスクリプションや要件に合わせて品質と機能が異なるさまざまなモデルを提供することができることを意味します。ユーザーエクスペリエンスを完璧にカスタマイズすることが重要です!
さあ、最新の実行を本番ステージに移動し、アプリを更新しましょう🔄️
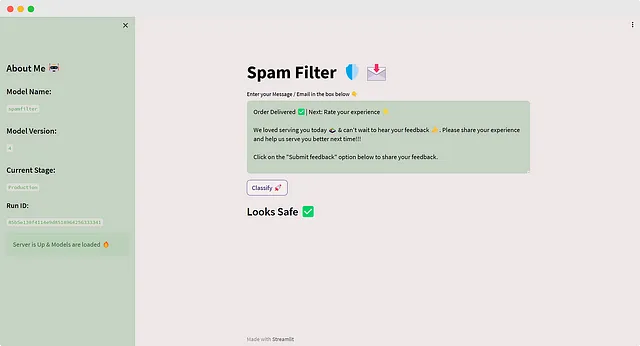
これにより、最新の変更が反映されます。これが実際の世界でモデルが提供される方法です。これがCI/CD(継続的インテグレーションと継続的デプロイメント)の基本です。これがMLOpsです。最初から最後まで完璧にやり遂げました!🎉
それでは、この詳細なブログは以上です!しかし、覚えておいてください、これはMLOpsの広大な世界でのほんの一歩に過ぎません。先に進む旅は、アプリをクラウド上でホスティングし、他の人々と協力し、APIを介してモデルを提供することを含みます。このブログではStreamlitだけを使用しましたが、エンドポイントを構築するためのFastAPIやFlaskのような他のオプションを自由に探索することができます。StreamlitをFastAPIと組み合わせて、好みのパイプラインとの切り離しと結合を行うこともできます。復習が必要な場合は、以前のブログの一つでその方法を紹介しています!
Streamlit🔥+ FastAPI⚡️- 次のデータサイエンスレシピに必要な要素
Streamlitは、インタラクティブなダッシュボードやWebアプリを迅速に構築して共有するためのオープンソースで無料のPythonフレームワークです…
VoAGI.com
ねえ、ねえ、ねえ!読み終わりましたよ、みなさん!このプロジェクト全体のGitHubリポジトリはこちらです👇
GitHub – afaqueumer/mlflow101
GitHubでアカウントを作成して、afaqueumer/mlflow101の開発に貢献してください。
github.com
このブログが皆さんに笑顔と知識をもたらしたことを願っています。読んで楽しんで役に立った場合は、ぜひ私、Afaque Umerをフォローして、さらにスリリングな記事をご覧ください。
機械学習とデータサイエンスの世界でのエキサイティングな冒険をもっと楽しみにしてください。難しそうな用語を簡単な概念にわかりやすく解説します。
さて、さようならの時間です👋
読んでくれてありがとう 🙏ロックし続けてください🤘学び続けてください🧠共有し続けてください🤝そして何より実験し続けてください!🧪🔥✨😆
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
