安定した拡散:生成AIの基本的な直感
'安定した拡散:生成AIの基本'

イントロダクション
AIの世界は、コンピュータビジョンと自然言語処理の両方で、過去数年間にわたって生成モデリングへと大きくシフトしています。Dalle-2とMidjourneyは人々の注目を集め、生成AIの分野で達成されている優れた業績を認識させています。
現在生成されているほとんどのAI生成画像は、その基礎として拡散モデルに依存しています。本記事の目的は、安定した拡散に関するいくつかの概念を明確にし、使用されている手法の基礎的な理解を提供することです。
簡略化されたアーキテクチャ
このフローチャートは、安定した拡散アーキテクチャの簡略版を示しています。内部の動作をより良く理解するために、ピースごとに進めていきます。トレーニングプロセスについて詳しく説明し、推論ではわずかな変更のみ行います。
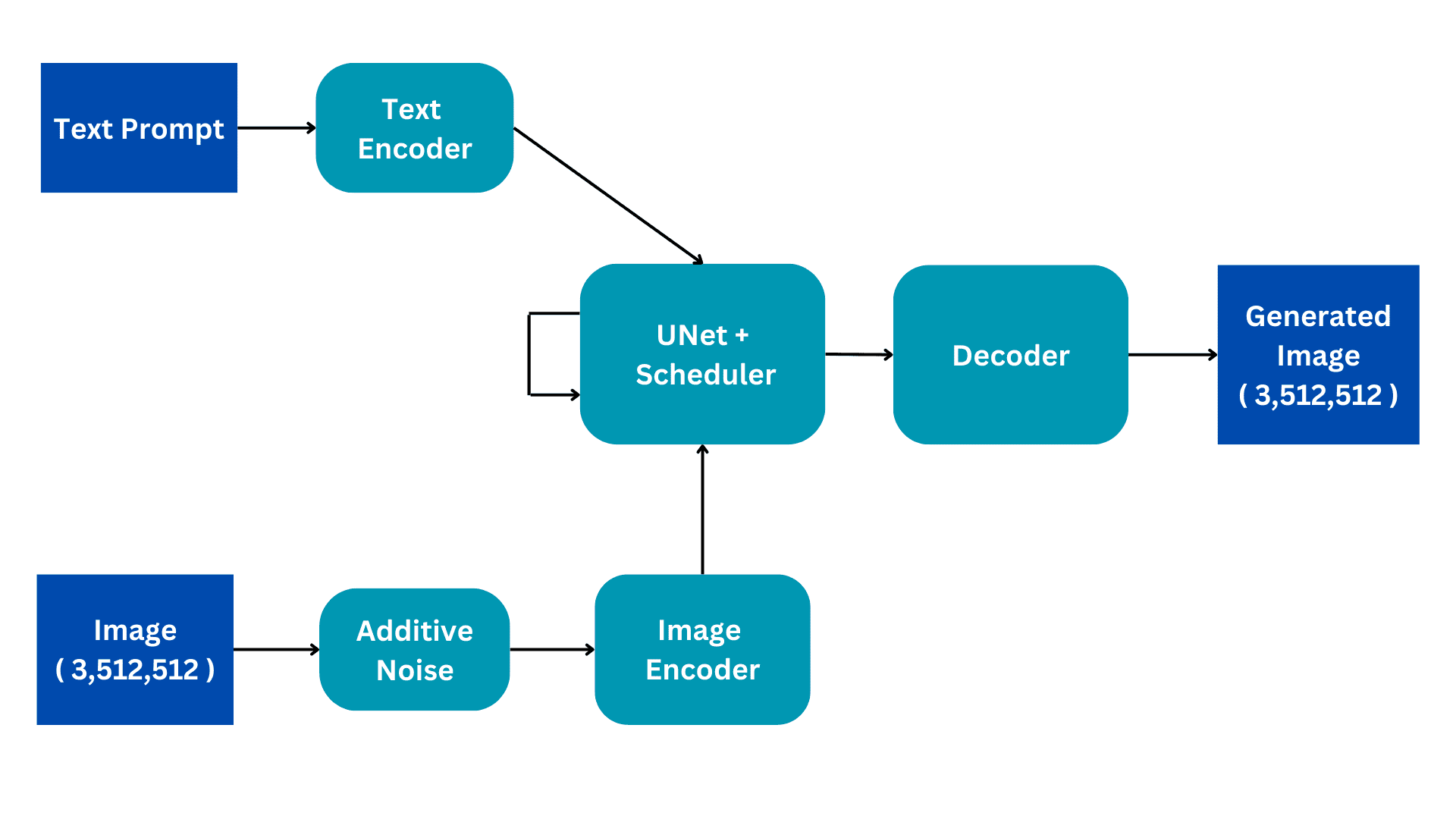
入力
安定した拡散モデルは、画像キャプションのデータセットでトレーニングされます。各画像には、画像を説明するキャプションまたはプロンプトが関連付けられています。したがって、モデルへの入力は2つあります。自然言語のテキストプロンプトと、3色チャンネルとサイズ512の画像(3,512,512)です。
加算ノイズ
元の画像にガウスノイズを追加することで、画像を完全なノイズに変換します。これは連続したステップで行われます。たとえば、画像に連続した50のステップで少量のノイズを追加し、画像を完全にノイズにします。拡散プロセスは、このノイズを除去し、元の画像を再現することを目指します。これがどのように行われるかは、さらに説明します。
画像エンコーダー
画像エンコーダーは、変分オートエンコーダーのコンポーネントとして機能し、画像を「潜在空間」に変換し、より小さい次元(たとえば、(4, 64, 64))にリサイズします。また、追加のバッチ次元も含みます。このプロセスは、計算要件を削減し、パフォーマンスを向上させます。オリジナルの拡散モデルとは異なり、安定した拡散ではエンコーディングステップを潜在次元に組み込んでおり、計算量が減少し、トレーニングと推論の時間が短縮されています。
テキストエンコーダー
自然言語のプロンプトは、テキストエンコーダーによってベクトル化された埋め込みに変換されます。このプロセスでは、BERTやGPTベースのCLIPテキストモデルなどのトランスフォーマーランゲージモデルが使用されます。エンハンストテキストエンコーダーモデルは、生成された画像の品質を大幅に向上させます。テキストエンコーダーの出力は、各単語に対して768次元の埋め込みベクトルの配列です。プロンプトの長さを制御するために、最大制限が77に設定されます。その結果、テキストエンコーダーは(77、768)の次元を持つテンソルを生成します。
UNet
これはアーキテクチャの中で最も計算量の多い部分であり、主な拡散処理が行われます。テキストエンコードとノイズのある潜在画像を入力として受け取ります。このモジュールは、受け取ったノイズのある画像から元の画像を再現することを目指します。これを、ハイパーパラメータとして設定できるいくつかの推論ステップによって行います。通常、50の推論ステップが十分です。
単純なシナリオを考えてみましょう。入力画像が50の連続したステップで徐々にノイズに変換されるとします。このノイズの累積的な追加により、元の画像は完全なノイズに変換されます。UNetの目的は、このプロセスを逆転させ、以前のタイムステップで追加されたノイズを予測することです。ノイズ除去プロセス中、UNetは最初のタイムステップの50番目のタイムステップで追加されたノイズを予測します。次に、この予測されたノイズを入力画像から引き算し、プロセスを繰り返します。各次のタイムステップでは、UNetは前のタイムステップで追加されたノイズを予測し、完全なノイズから元の入力画像を徐々に復元します。このプロセス全体で、UNetは内部的にテキスト埋め込みベクトルを条件付き要素として利用します。
UNetは、(4, 64, 64)のサイズのテンソルを出力し、変分オートエンコーダーのデコーダー部分に渡されます。
デコーダー
デコーダーは、エンコーダーによって行われた潜在表現変換を逆転させます。潜在表現を取り、それを画像空間に変換します。したがって、元の入力空間と同じサイズの(3,512,512)の画像が出力されます。トレーニングでは、元の画像と生成された画像の間の損失を最小限にすることを目指します。そのため、完全にノイズのある画像から、テキストのプロンプトを与えることで関連する画像を生成することができます。
すべてを一つにまとめる
推論中、入力画像はありません。テキストから画像への変換モードのみで作業します。加算ノイズの部分を削除し、代わりに必要なサイズのランダム生成テンソルを使用します。アーキテクチャのその他の部分は変わりません。
UNetは、完全なノイズから画像を生成するためにトレーニングを受けています。テキストプロンプトの埋め込みを活用します。この特定の入力は推論段階で使用され、ノイズから合成画像を成功裏に生成することができます。この一般的な概念は、すべての生成型コンピュータビジョンモデルの基本的な直感として機能します。Muhammad Arhamは、コンピュータビジョンと自然言語処理に取り組むディープラーニングエンジニアです。彼は、Vyro.AIでグローバルトップチャートに到達したいくつかの生成型AIアプリケーションの展開と最適化に取り組んできました。彼は、知的システム向けの機械学習モデルの構築と最適化に興味を持ち、継続的な改善を信じています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Wandaとは:大規模言語モデルに対するシンプルで効果的なプルーニング手法の紹介
- Google MusicLMを使用してテキストから音楽を生成する
- API管理を使用してAIパワードJavaアプリを管理する
- LangFlow | LLMを使用してアプリケーションを開発するためのLangChainのUI
- ProFusion における AI 非正則化フレームワーク テキストから画像合成における詳細保存に向けて
- Amazon SageMaker Canvasを使用して、ノーコードの機械学習を活用して、公衆衛生の洞察をより迅速にキャプチャーしましょう
- フィールドからフォークへ:スタートアップが食品業界にAIのスモーガスボードを提供