大規模言語モデル:SBERT
大規模言語モデル:SBERT
シャイアミーズBERTネットワークが文を埋め込みに正確に変換する方法を学ぶ
イントロダクション
トランスフォーマーがNLPで進化的な進歩を遂げたことは秘密ではありません。トランスフォーマーをベースに、多くの他の機械学習モデルが進化しました。その一つがBERTで、主にいくつかのスタックされたトランスフォーマーのエンコーダーで構成されています。感情分析や質問応答などさまざまな問題に使用されるだけでなく、BERTは単語の意味を表す数値のベクトルである単語の埋め込みの構築においてますます人気が高まっています。
埋め込みの形で単語を表現することは、生のテキストでは機械学習アルゴリズムが動作できないが、ベクトルのベクトルで操作できるという非常に大きな利点があります。これにより、ユークリッド距離やコサイン類似度などの標準的なメトリックを使用して、異なる単語を比較することができます。
しかし、実際のところ、しばしば単語ではなく文全体の埋め込みを作成する必要があります。しかし、基本的なBERTのバージョンは単語レベルでのみ埋め込みを構築します。そのため、この問題を解決するために後にいくつかのBERTのようなアプローチが開発されました。この記事ではそれらについて議論し、最先端のモデルであるSBERTに到達します。
SBERTがどのように機能するかを深く理解するには、事前にBERTについて既に知っていることをお勧めします。そうでない場合、この記事シリーズの前の部分で詳しく説明しています。
大規模言語モデル:BERT
BERTが最先端の埋め込みを構築する方法を理解する
towardsdatascience.com
BERT
まずは、BERTが情報を処理する方法を思い出しましょう。入力として、[CLS]トークンと特別な[SEP]トークンで区切られた2つの文を取ります。モデルの構成に応じて、この情報はマルチヘッドアテンションブロックによって12回または24回処理されます。その出力は集約され、最終的なラベルを取得するために単純な回帰モデルに渡されます。
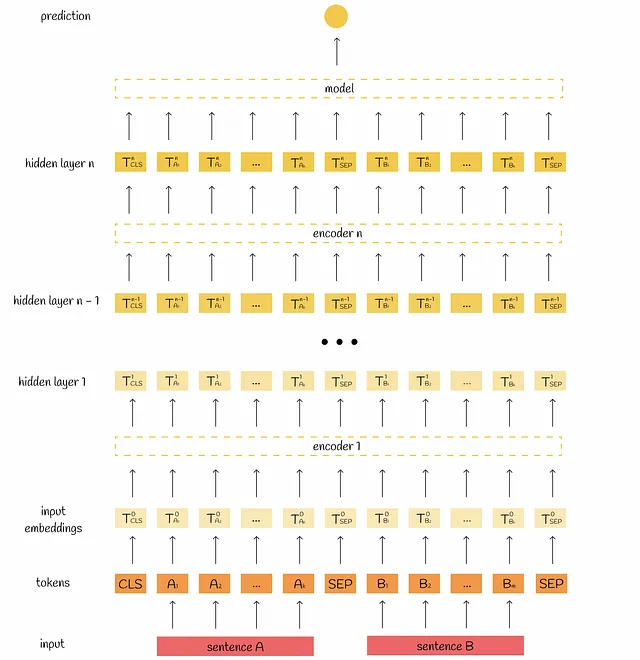
BERTの内部の詳細については、この記事シリーズの前の部分を参照してください:
クロスエンコーダーアーキテクチャ
BERTを使用して2つのドキュメントの類似性を計算することも可能です。大規模なコレクション内で最も類似した文のペアを見つけるという目標を考えてみましょう。この問題を解決するために、各可能なペアをBERTモデルに入れます。これにより、推論時の二次の計算量が発生します。たとえば、n = 10,000の文を扱う場合、n * (n — 1) / 2 = 49,995,000回のBERT推論計算が必要ですが、これは実際にはスケーラブルではありません。
他のアプローチ
クロスエンコーダーアーキテクチャの非効率性を分析すると、各文について埋め込みを事前に独立して計算することが論理的に思えます。その後、ドキュメントのすべてのペアで選択した距離指標を直接計算することができます。これは、文のペアをBERTに供給する2次の数のペアよりもはるかに高速です。
残念ながら、BERTではこのアプローチは不可能です。BERTの核心の問題は、2つの文章が同時に渡されて処理されるため、単一の文を独立して表す埋め込みを取得することが困難であるということです。
研究者たちは、[CLS]トークンの埋め込みの出力を使用して、文を表すのに十分な情報が含まれていると期待してこの問題を解決しようとしました。しかし、[CLS]は単純にBERTで次の文予測のために事前学習されたため、このタスクには全く役に立たないことがわかりました。
別のアプローチは、単一の文をBERTに渡し、出力トークンの埋め込みを平均することでした。しかし、得られた結果は、単にGloVeの埋め込みを平均するよりもさらに悪かったです。
独立した文の埋め込みを生成することは、BERTの主要な問題の一つです。この問題を緩和するために、SBERTが開発されました。
SBERT
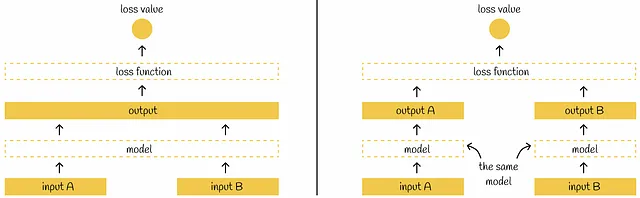
SBERTは、Siameseネットワークの概念を導入しており、各文が独立して同じBERTモデルを通過することを意味します。SBERTのアーキテクチャについて説明する前に、Siameseネットワークについて微妙な注意点を述べましょう。
科学論文では、通常、複数のモデルが多くの入力を受け取るSiameseネットワークアーキテクチャが描かれます。実際には、同じ構成と重みを持つ単一のモデルと考えることができます。単一の入力のモデルの重みが更新されると、他の入力に対しても同様に更新されます。
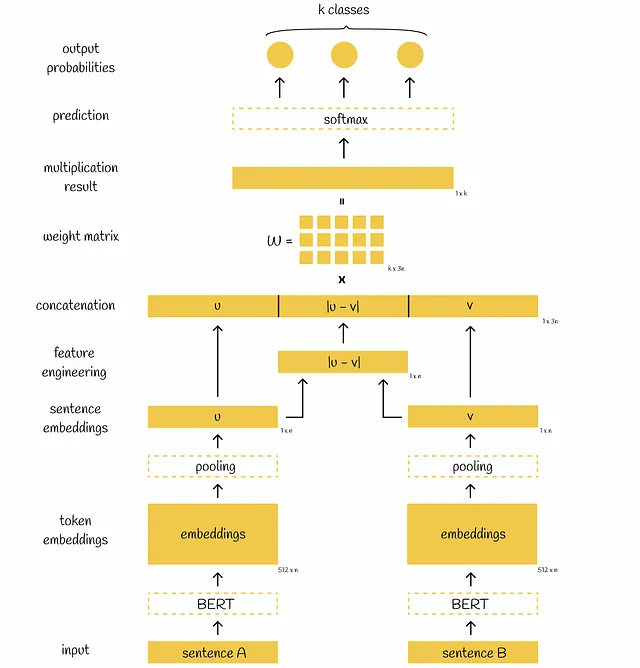
SBERTに戻ると、BERTを通過した後、プーリング層がBERTの埋め込みに適用され、それらの低次元表現を取得します。初期の512個の768次元ベクトルは、単一の768次元ベクトルに変換されます。プーリング層では、SBERTの著者は、デフォルトとして平均プーリング層を選択することを提案していますが、最大プーリング戦略を使用することも可能であり、または単に[CLS]トークンの出力を使用することも可能です。
両方の文がプーリング層を通過すると、2つの768次元ベクトルuとvが得られます。これらの2つのベクトルを使用して、著者は以下で説明される異なる目的の最適化のための3つのアプローチを提案しています。
分類目的関数
この問題の目標は、与えられた文のペアをいくつかのクラスの1つに正しく分類することです。
埋め込みuとvが生成された後、研究者は、これら2つから派生した別のベクトルとして要素ごとの絶対差|u-v|を生成することが有用であると見つけました。他の特徴エンジニアリング手法も試しましたが、この方法が最良の結果を示しました。
最後に、3つのベクトルu、v、および|u-v|が連結され、学習可能な重み行列Wで乗算され、乗算結果がソフトマックス分類器に供給され、異なるクラスに対応する文の正規化された確率が出力されます。クロスエントロピー損失関数を使用してモデルの重みが更新されます。
この目的で解決される最も人気のある既存の問題の1つは、与えられた文AとB(仮説と前提を定義する)のペアに対して、前提を与えた場合に仮説が真(論理関係)、偽(矛盾)または未定義(中立)であるかを予測することです。この問題について、推論プロセスはトレーニングと同じです。
論文によると、SBERTモデルは元々SNLIとMultiNLIという2つのデータセットでトレーニングされており、100万の文のペアと対応するラベル(論理関係、矛盾、中立)が含まれています。その後、著者はSBERTのチューニングパラメータの詳細について言及しています:
「我々は、1エポックの3クラスのソフトマックス分類器目的関数でSBERTを微調整しました。バッチサイズは16、学習率2e−5のAdamオプティマイザーを使用し、トレーニングデータの10%に対して線形学習率ウォームアップを行いました。デフォルトのプーリング戦略は平均です。」
回帰目的関数
この定式化では、ベクトルuとvを取得した後、それらの間の類似度スコアは選択された類似度メトリックによって直接計算されます。予測された類似度スコアは真の値と比較され、モデルはMSE損失関数を使用して更新されます。デフォルトでは、著者は類似度メトリックとしてコサイン類似度を選択します。
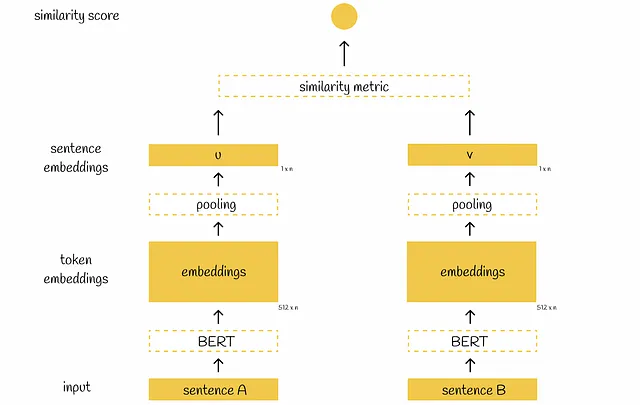
推論中、このアーキテクチャは2つの方法のいずれかで使用できます:
- 与えられた文のペアによって、類似度スコアを計算することが可能です。推論のワークフローはトレーニング時とまったく同じです。
- 与えられた文に対して、後で使用するための文の埋め込みを抽出することが可能です(プーリング層を適用した直後)。これは、大量の文が与えられ、それらの間のペアワイズ類似度スコアを計算することが目的の場合に特に有用です。各文をBERTに一度だけ実行することで、必要なすべての文の埋め込みを抽出します。その後、すべてのベクトル間で選択された類似度メトリックを直接計算することができます(疑いなく、計算には二次の比較が必要ですが、同時に以前のBERTによる二次の推論計算は回避されます)。
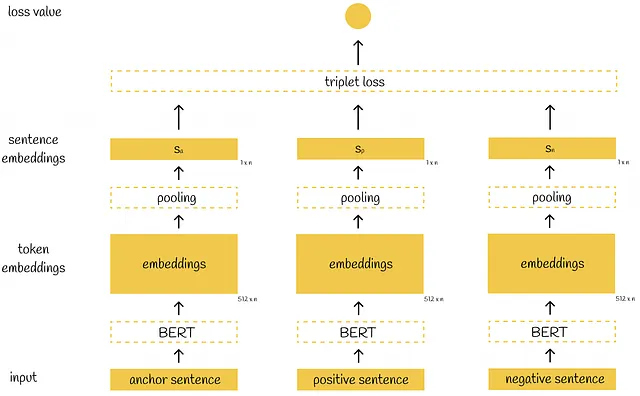
トリプレット目的関数
トリプレット目的関数は、通常アンカー、ポジティブ、ネガティブという3つの文に基づいて計算されるトリプレット損失を導入します。アンカーとポジティブの文は非常に近いと仮定され、アンカーとネガティブの文は非常に異なっていると仮定されます。トレーニングプロセス中、モデルはペア(アンカー、ポジティブ)がペア(アンカー、ネガティブ)に比べてどれだけ近いかを評価します。数学的には、次の損失関数が最小化されます:
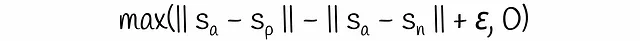
マージンεは、ポジティブな文がアンカーからネガティブな文より少なくともεだけ近いことを保証します。そうでない場合、損失は0より大きくなります。デフォルトでは、この式ではベクトルノルムとしてユークリッド距離が選択され、パラメータεは1に設定されます。
トリプレットSBERTアーキテクチャは、以前の2つとは異なり、モデルが並列して3つの入力文(2つではない)を受け入れるようになっています。
コード
SentenceTransformersは、文の埋め込みを作成するための最先端のPythonライブラリです。さまざまなタスク用にいくつかの事前学習済みモデルが含まれています。SentenceTransformersを使用して埋め込みを構築するのは簡単で、以下のコードスニペットに例が示されています。
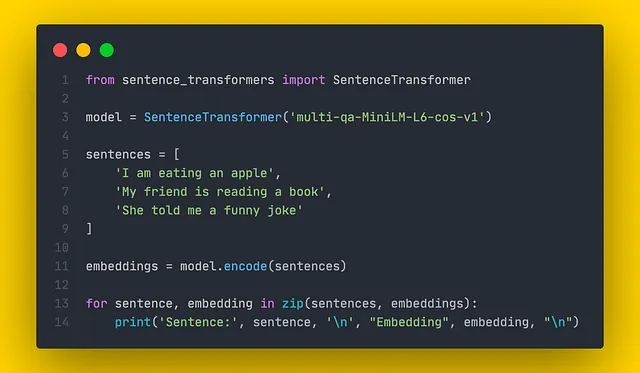
構築された埋め込みは、類似性比較に使用することができます。各モデルは特定のタスクのためにトレーニングされているため、ドキュメントを参照して適切な類似度メトリックを選択することが常に重要です。
結論
私たちは、文の埋め込みを取得するための高度なNLPモデルの1つを見てきました。SBERTは、二次のBERT推論の実行を線形に削減することで、高速性を維持しながら高い精度を実現しています。
この差がどれほど重要かを最終的に理解するには、n = 10000の文の中で最も類似したペアを見つけるために研究者が試みた例を参照するだけで十分です。現代のV100 GPUでは、BERTを使用した場合には約65時間かかりましたが、SBERTを使用した場合にはわずか5秒でした!この例は、SBERTがNLPにおける大きな進歩であることを示しています。
リソース
- Sentence-BERT:Siamese BERT-Networksを使用した文の埋め込み
- SentenceTransformersドキュメンテーション | SBERT.net
- 自然言語推論 | コード付きの論文
特記がない限り、すべての画像は著者によるものです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





