大規模言語モデルの探索 -Part 1
大規模言語モデルの探索 -Part 1
機械学習の聖杯 – 教師なし学習、理解の出現、LLMトレーニングの理解
この記事は主に自己学習のために書かれています。そのため、広く深く掘り下げています。興味のあるセクションをスキップしたり、自分の関心のある領域を探したりしてください。
以下は、LLMの微調整を試みながら私が興味を持ったり浮かんできたりしたいくつかの質問です。この記事はこれらの質問に答える試みであり、他の好奇心を持つ人々とこの情報を共有するためのものです。
LLMはLoss関数を持つNeuralNetに基づいているため、LLMのトレーニングはすべて教師ありトレーニングではありませんか?なぜ通常は教師なしトレーニングと呼ばれるのですか?LLMのトレーニングが実際にどのように機能するかを説明するために、LLMを非常に短い文でトレーニングできますか?マスクされたLMと因果関係のあるLMとは何ですか?Transformerアーキテクチャの直感的な理解を1枚の図で説明できますか?LLMの教師なしトレーニングとは具体的に何を意味するのですか?ChatGPTの主要な設計者であるIlya Suverskarは、教師なしトレーニングを機械学習の聖杯と考えているのですか?LLMの出現/理解とは何を意味するのですか?
LLMの使用例は何ですか?なぜLLMが生産性アシスタントとして最適であると考えられていますか?情報検索のためのベクトルDB/埋め込みパターンとは何ですか?LLMはテキスト以外のタスクにも使用できますか?因果推論とは何ですか?LLMの問題点は何ですか?Yan LeCunのような人々はなぜ現在のLLMは絶望的だと考えているのですか?LLMは説明可能ですか?説明できない場合、効果的に使用する方法はありますか?
なぜLLMを微調整/再トレーニングする必要がありますか?LLMのトレーニングが困難なのはなぜですか?量子化とLoRAは大規模なLLMのトレーニングにどのように役立ちますか?量子化とLoRAはどのように機能するのですか?事前にトレーニングされたLLMを効果的に微調整する方法は何ですか?Instruct Tuningとは何ですか?Self Instructとは何ですか?Instruct Tuningのための高品質なトレーニングデータセットをどのように生成できますか?
まだ回答していません。LLMの能力の異なるLLMを階層的に構造化して、因果関係を持つ複雑な自動化を作成する方法を示すことはできますか?なぜLLMやニューラルネットから人間のような知能を作り出そうとしているのですか?これは、固定翼飛行機の発明以前の時代に鳥のような飛行を作り出すことと不気味に似ているように思われるのはなぜですか?
記事がかなり長いため、読みやすさのために3つのパートに分けています。
パート1では、LLMのトレーニングの進化について説明します。モデルサイズがある閾値を超え、大量のデータでトレーニングされたときに起こり始めるマジック、またはより技術的には出現が起こる理解するための文脈を設定することが意図されています。詳細な説明は、これらのコンセプトをより詳しく深く掘り下げたものですが、ほとんどのプログラマーにとっても理解しやすいです。
パート2では、LLMの人気のある使用例、個人アシスタント、および情報検索パターン(LLMの補完を使用したベクトル空間検索)を通じたカスタムデータを持つチャットボットについて簡単に説明します。モデルのメンタルモデルとNLUが最終的により強力な使用例になる可能性についても探求します。この文脈では、監督トレーニングの強みとLLMモデルの弱点である説明可能性の欠如または事実と幻覚の判断の難しさを対比することによって、LLMモデルの主な制約を探求します。私たちは、階層的な制御による信頼性のないシステムの信頼性向上というより高いレベルの制御によって信頼性のないシステムを信頼性のあるものにすること、例えばChatGPTの日常的な使用など、このようなシステムがコンピューターシステムで非常に効果的に使用されてきた方法と、他の使用例に拡張できる方法を探求します。
パート3では、カスタムドメインでのLLMのトレーニングに関連するいくつかの概念について説明します。これにより、より単純なベクトル空間情報検索パターンよりもはるかに強力なドメインの理解が可能になります。おもちゃの例では簡単ですが、実際のデータでは非常に簡単ではありません。量子化技術が非常に大規模なLLMを世界に開放し、これがトレーニングパラメータを減らす概念と組み合わさることでLLMの微調整が民主化された方法について探求します。効果的な微調整の主な技術であるInstruct Tuningと、これまでに進んだ概念すべてを備えた高品質なInstructionトレーニングデータセットが利用できないというInstruct Tuningの最大の実用的な問題を解決する方法について探求します。
将来のセクションでは、LLMの理解部分を活用し、これらの強力なシステムをAI/MLシステムを補完するための階層的な制御の概念を探る予定です。
紹介
大規模言語モデル(LLM)には2つの明らかな能力があります。モデルとの自然言語インターフェースと、モデル内に非常に効率的に保存されている膨大な知識-インターネットのテキストデータ全体です。モデルが大きければ大きいほど、これらの能力が向上します。
もう一つの非常に明白ではない能力がありますが、これが最も強力かもしれません。これは第一の能力に含まれており、技術的にはNLU(自然言語理解)と呼ばれます。何かを理解するには、それのモデルが必要です。人間にとっては、心のモデルです。言語を理解するには、言語の構文と意味のモデルが必要です。ユーザーの質問を理解し、効果的にそれに答えるためには、モデルに内部の世界モデルが必要です。この分野の指導者たちの間では、これらのLLMが学習した内部の世界モデルがあるのか、またはそれが存在するかのように見えるのかについて議論があります。
しかし、彼らの自然言語理解は非常に優れており、彼らの内部の世界モデルには十分な情報があるため、彼らはチューリングテスト(https://www.nature.com/articles/d41586-023-02361-7)と、現在のAIの最も有名な批評家であるJudea Pearlによって提案された因果推論に基づくミニチューリングテストに合格しています。このトピックには後で戻ります。
ある意味では、誰もが知っていると思っているものは、ある意味では誰もが知らない。ロバート・J・スターンバーグ、出典
それでも、これは彼らが本当の意味で知能を持っているわけではないということを意味するものではありませんが、自然言語の理解においては、より安全に知的ですと言えるでしょう。これはこれらのモデルを他のものとは異なる特性にする重要な要素です。
LLMはダムなオートマトンとして始まりますが、トレーニングのどこかで、明示的にトレーニングされていないタスクにもトレーニングを一般化するほど賢くなります。これが私たちが「理解」とより自由に言うことができるものです。前述したように、これは非常に議論のあるテーマであり、私たちの目標は議論に深く入ることではなく、学ぼうとすることです。
LLMのトレーニングと理解の出現
いくつかの有名なAI/MLシステムの歴史をたどることで、このトピックをもっと楽しく理解することができます。
ルールエンジン/ツリーサーチ
まず、IBM DeepBlue(チェスをプレイするスーパーコンピュータ)から始めましょう。スーパーコンピュータのパワーとカスタムチップを使用して、1997年にチェスのグランドマスターであるゲイリー・カスパロフに勝利しました。しかし、当時はAIやニューラルネットは関与していませんでした。ツリーサーチでした。これを少し抽象化して、ルールベースのエンジンと言えます。トレーニングデータは、ドメインの専門知識を手作業でコーディングし、ルールセットにまとめたものでした。アルゴリズムは、現在の状態に基づいて広大なが計算可能な結果セットから次の手の選択を最適化しました。ただし、より広範なドメインに対してこのルールベースのプログラミングを行うことは不可能であることが明らかでした。
教師ありトレーニング
10年後の2011年、IBM Watson –はクイズQAのために設計され、チャンピオンに勝利しました。これには大きなハイプがあり、すべてを革新する次世代の知識システムとして注目されました。システムの主なトレーニング方法は、教師ありトレーニングのようです。つまり、システムが正しい回答またはこの場合は正しい質問を選択するためにトレーニングされたデータにはラベルが付いています。
教師あり学習はうまく機能します。これは、現在のほとんどの本番で使用されている機械学習の基盤です。十分なラベル付きデータがあれば、AI/MLシステムは複雑な多変数関数を近似学習することができます。彼らは優れた汎用関数近似器です。
「ディープラーニングのすべての印象的な成果は、単なる曲線のフィットに過ぎない…」。AI/MLシステムの批判で有名なトゥーリング賞受賞者Judea Pearl
教師あり学習の問題は、膨大なデータセットにラベルを付けることが、巨大なモデルのトレーニングには多額の費用と時間を要するということです。
最も大きなラベル付きデータセットの例とその影響は、ImageNetです。これは、ImageNetプロジェクトの一環として収集された膨大な数のラベル付き画像データで、2012年に導入されたAlexNet(Ilya Sutskever、Alex Krizhevsky、Geoffrey Hinton)がコンピュータビジョンを革新するのに役立ちましたが、1998年にはYann LeCunなどが文字認識用のLeNetベースの畳み込みニューラルネットワークを導入していました。
注意:Ilya SutskeverはOpenAIの創設者の一人であり、後にGPTモデルのトレーニングに重要な役割を果たしました。
話を戻します。IBM Watsonに対するハイプは、システムの制限が明らかになるにつれて年々薄れていきました。NY Timesの記事では、IBMが期待したように他の分野にも十分に一般化することができなかった理由のいくつかについて洞察を与えています。適切にラベル付けされたデータの不足がその主な理由でした。
強化学習
2016年、Google DeepMind AlphaGoは、チャンピオンの囲碁プレイヤーに勝利することで非常に人気となりました。このゲームは、チェスよりもはるかに広いドメイン/戦略を持っています(ルールエンジン/木検索型のアルゴリズムでは不可能です)。ここでキーポイントとなったのが強化学習(RL)です。
ここでは、トレーニングはランダムな手を打つことに抽象化され、もし手が勝利に近づくようなら(一部の損失計算を通じて)そのような手をより多く打ち、逆もまた然りです。そして、彼らはエージェントを作成し、エージェント同士を対戦させることで、おそらく数千年分のゲームをプレイし、ゲームに長けるようになりました。
囲碁よりも複雑なゲームはDotaですが、2019年には、当時の小さな会社であったOpenAIが現在のDota 2のチャンピオンに勝利しました
このイベントに関連する興味深いスニペットがあります。最後の”scale”という言葉は、彼らが将来のGPTモデルの作業にどのようにこのコンセプトを使用したかを示唆しているかもしれません
OpenAI Fiveを始めたのは、既存のディープ強化学習の範疇外の問題に取り組むためでした…私たちは階層的な強化学習などの洗練されたアルゴリズムのアイデアが必要になると予想していましたが、私たちが見つけたのは驚きでした:この問題に必要な基本的な改善は、スケールでした。
DeepDive – Tough RLはすべてに使用できるように見えます(たとえば、これは赤ちゃんが歩く方法やほとんどの生物が学ぶ方法です)、制限されたまたは制御された状態空間を持つゲームのようなドメイン以外では、非常に難しいです。たとえば、自動運転車では、前のステップでのわずかな状態の変化が後でプラスまたはマイナスに影響を与える可能性があります。これは一時的に保存して作業できる損失関数の実装にまで帰結します。(https://stanford.edu/~ashlearn/RLForFinanceBook/book.pdf、なぜRLには逆伝播近似が必要かhttps://stats.stackexchange.com/a/340657/191675)
これで、AI / MLアルゴリズムの基本である教師あり学習と強化学習をカバーしました-主にビデオゲームなどでの強化学習。
教師なし学習-すべての学習の至宝?
OpenAIでの…希望は、次の単語を予測できるニューラルネットワークが教師なし学習を解決するということでした。ですので、GPTの前には、教師なし学習は機械学習の至宝と考えられていました….
しかし、私たちのニューラルネットワークはその課題には対応できませんでした。私たちは再帰ニューラルネットワークを使用していました。トランスフォーマーが出てきたとき、論文が出た次の日には、それが私たちにとって再帰ニューラルネットワークの制限、長期依存関係の学習の問題を解決していることが明らかになりました…
そして、それが最終的にGPT-3につながり、本質的に私たちが今日に至るまでの進展につながったのです。-Ilya Sutskever インタビュー
ここで”至宝”という言葉が何を意味するのかを探る前に、文脈を明確にするために一歩後退し、エンジニアが通常教師なし学習と言った時に何を意味するのか、ここでの意味するところを探ってみましょう。ここで言っていることは、実装そのものではなく、より高いレベルの学習の抽象化を指しています。まだ、トークンの次を予測するためにトレーニングされたネットワークが、LLMのように一般化する方法は謎です。つまり、彼らは教師ありの次のトークン予測のトレーニングを通じて教師なしの方法で一般化することを学びます。
教師なし学習についての通常の考え方
通常、MLで教師なし学習を話す場合、クラスタリングに関連するいくつかのアルゴリズム、例えばk-meansクラスタリング、次元削減、主成分分析、または時系列フィッティングなどがあります。これらは数学や行列の特性に基づいています。これらは非常に複雑ですが、数学が得意であれば、または十分な努力をすることで、明確に理解できるものです。
深層学習の場合、下位レベルの例としてはオートエンコーダーがあります。オートエンコーダーは、LLMの文脈で興味深いのは、内部の圧縮表現のための構造を学習する方法です。オートエンコーダーでは、ターゲットは入力と同じです。つまり、複雑なデータ(例えば、非常に詳細な画像)が与えられた場合、浅いネットワークをトレーニングして類似の出力を生成する必要があります。これには、ネットワークがデータの中のいくつかのパターンを学習し、これを十分に圧縮するためのものが必要です。詳細はこちらをご覧ください:http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/
この記事では、私たちは古典的なMLやDLのユースケースではなく、LLMsのための教師なし学習に焦点を当てています。
DeepDive: 現在のすべての深層ニューラルネットベースの機械学習は、最適化とバックプロパゲーションのために損失関数が必要であり、損失には計算するためのいくつかのターゲットが必要です。LLMの文脈では、ターゲットはトークンのセット(トークンは単語に近似)の次のトークンです。このようにして、私たちはインターネットのテキスト全体(クリーン)を巨大なラベル付きトレーニングデータセットとして使用することができます。
では、事前にトレーニングされたモデルを微調整または再トレーニングして、例えば「I love New York」という文の前に「City」の代わりに「Zoo」を予測する方法を見てみましょう。これにより、LLMのトレーニングと損失の直感を得ることができます。
例のトレーニング文は「I love New York Zoo」です。モデルは最初の単語「I」を入力として受け取り、何かを出力します。しかし、ターゲットは「love」として与えられ、CrossEntropy Lossはそのターゲットとの差を計算し、トレーニングによって最小化されます。最後に、「York」の後にターゲット「Zoo」があります。ラベルまたはターゲットは基本的に次のトークンです。
これは単なる教師ありトレーニングです。モデルが小さく、データセットも小さいため、ここでは教師なし学習は行われません。
小さなおもちゃのモデルNanoGPTであろうと、LLAMA2モデルであろうと、使用される損失は基本的に交差エントロピー損失です。
ソフトマックス関数は、ニューラルネットワークの最終層として使用され、クラス全体の確率分布を生成します。私たちの場合、クラスは語彙中のすべての単語です。
したがって、生成された確率分布と真のクラスラベルとの間の差を計算するために損失関数が必要です。その後、この確率分布に対してクロスエントロピー損失が適用され、予測された確率と真のクラスラベルとの間のエラーを測定します。
よりよく理解するためには、Transformerアーキテクチャに少し深く入る必要があります。LLMモデルは一般的に因果言語モデルまたはマスク言語モデル(MLM)として設計されており、文の中の特定の単語をマスキングして(ただしモデルは文のすべてのトークンを見ることができる)ノイズを導入します。これらはそれぞれユニバーサルモデルとバイダイレクショナルモデルとも呼ばれます。
第三のオプションは、プレフィックスの因果またはマスク言語モデリングと呼ばれるもので、トレーニングデータにタスクのプレフィックス文字列が存在します(例:「フランス語に翻訳する:」)。最後のオプションはT5タイプのモデル(FlanT5 — テキストからテキストへのトランスフォーマーのためのファインチューン言語モデル)によって有名になりました。(他にもさまざまなバリエーションがあります)
これらのモデルのトレーニングには違いがあります。因果LMの場合、ターゲットは入力と同じで、右に1つシフトしたものです。マスクLMの場合、マスクの実際の値がターゲットであるノイズ除去トレーニングを作成する必要があります。
因果言語モデルは因果関係に基づいて操作されるため、前のトークンに基づいて予測し、おそらくそれらのトークンの因果関係に基づいて予測します。この関係がどのように見つかるかは、Transformerモデルと「Attention」という役割の全体的なストーリーです。「Attention is all you need」という有名な論文がTransformerネットワークを紹介しました。
この概念を簡単な方法で説明するのは簡単ではありません。以下の説明ビデオを複数回視聴することを強くお勧めします。Intuition Behind Self-Attention Mechanism in Transformer Networks — YouTube。
次に、予測するために正しい「次の」トークンを学習する過程で、トークンごとに3つの重みセットが損失を逆伝播することで学習されます。キー、クエリ、および値の重みです。これらは「Attention」メカニズムの基礎となります。上記のビデオでは、この場所でこれを美しく説明しています。
値ベクトルを計算するためにベクトルの内積の概念が使用されます。これは、クエリとキーのベクトルの内積の寄与の合計です。
直感的には、ベクトル埋め込み空間内の「類似のベクトル」はより大きな内積値と高い寄与を持つとされます。これは、文のトークン/単語の因果関連性を捉えるトリックです。
次に、バックプロパゲーションによって重みが調整されます。これは、学習された重みが文のための新しいより良いコンテキストベクトル埋め込み空間を表すことを意味します(キーとクエリの重みは多次元であり、複数の注意ヘッドがありますので、1つのベクトル空間ではありませんが、多数あります)。
Transformerでは、複数の注意ヘッドがありますので、どの注意ヘッドをより重視するかも重みを調整することで調整できます。Transformerネットワークは、トークン間の因果関係の直感を線形ニューラルネットワーク層の学習可能な重みとしてエンコードするこのアーキテクチャです。
以下に簡単なイメージで説明しました。
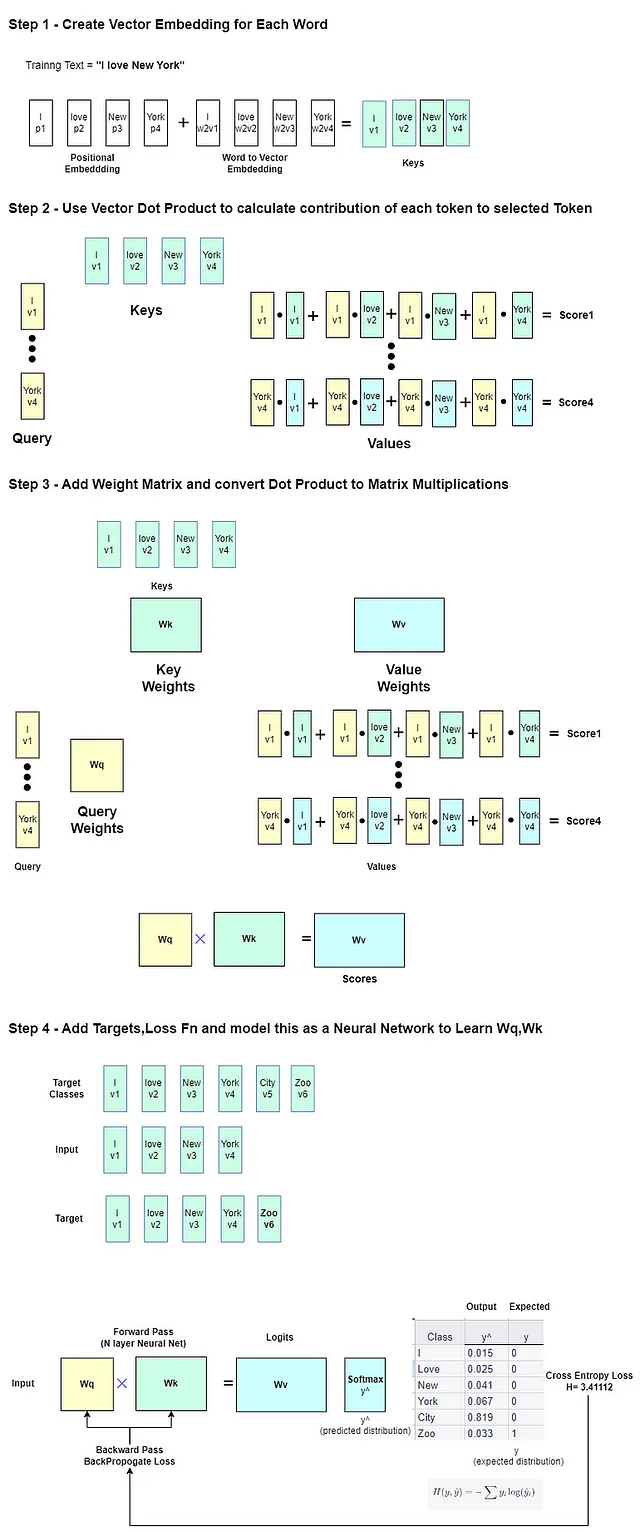
ここでは、小さな事前学習モデルの詳細を見ることができます。このモデルは、「I love New York」の後に「Ciy」を生成する最も高い確率をもつことができ、損失を減らすために「Zoo」を生成するために微調整されることができます。https://github.com/alexcpn/tranformer_learn/blob/main/LLM_Loss_Understanding.ipynb
そのような意味では、ここには何の特別なこともありません。私たちは、通常の教師なし学習(LLMの文脈で)を見てきました。損失関数、トレーニング(通常の勾配降下法と逆伝播に基づく)
ただし、ネットワークが大きくなり、トレーニングデータが膨大な(10億から1兆のトークン)場合、他の「曲線へのフィッティング」以外の現象が起こることがあります。それは、明示的にそのようにトレーニングされていなくても、トレーニングデータの固有の構造(人間の言語、プログラミング言語など)を「理解」するためにトレーニングを一般化できるということです。これが教師なし学習の究極の目標です。
Ilya Sutskeverは、これについて説明しています。https://youtu.be/AKMuA_TVz3A?t=490
したがって、謙虚な教師ありトレーニングから、神秘的な教師なし学習へと進化します
理解の出現
論文Language Models are Unsupervised Multitask Learnersは、Transformerアーキテクチャに基づいて世界にGPT-2を紹介しました。それは非常に特別なことをしました。
実験的に証明されました。十分に大規模なLLMが、十分に大きなデータセット(CommomCrawl / WebText- きれいなインターネットデータ)でトレーニングされると、言語の構造を「理解」し始めることができます。私は、より広範な意味を伝えるために、「一般化」の代わりに「理解」という用語を使用しているわけではありません。
このトピックについて読みやすいGoogle/DeepMindの研究論文があります。https://arxiv.org/pdf/2206.07682.pdf
彼らは8つのモデルを示し、ショットプロンプトタスクの正確性をランダムな選択に対して測定した場合、モデルのスケールの増加に伴い、出現する振る舞いが大幅に増加することを示しています。
同じ著者は、より良いビジュアルでこれについて議論しています(以下参照)
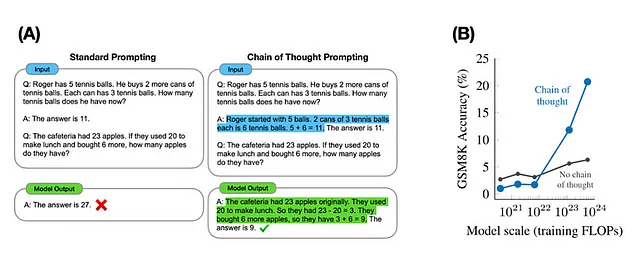
これに反論する他の研究もあり、この議論は始まったばかりです。論文は、LLMの数学における能力の欠如にリンクしていますが、これはもちろん、その得意分野ではありません。
確率分布ジェネレーターになるだけでなく、本当に何かを理解するためには、学習済みの内部世界モデルが必要です- Ilya Sutskeverによると。これにより、他の形式の機械学習やAIとは全く異なるものになります。
これを明確にするために、ChatGpt4モデルのサンプル入力と出力を示します。モデルは明示的に自動車運転のトレーニングを受けていません。しかし、トレーニングデータから世界観やワールドモデルを形成し、包括的な返答ができることがわかります。
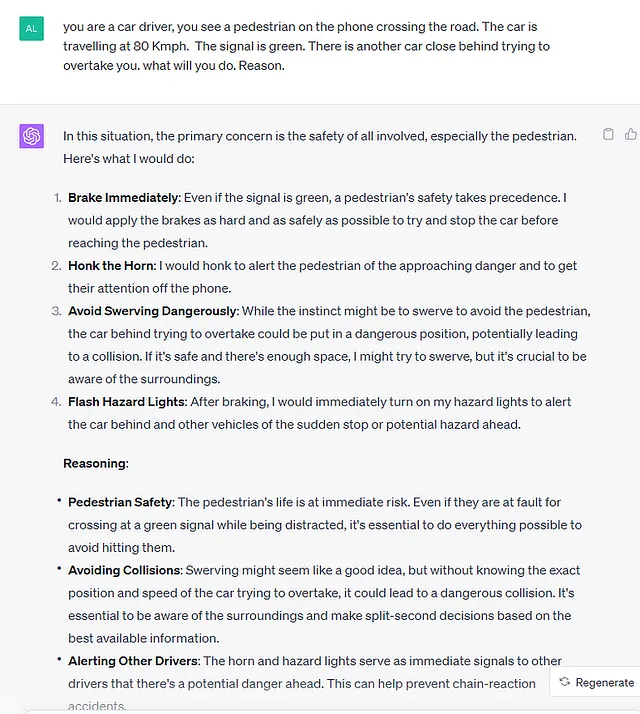
トレーニングとモデルパラメータのスケールが増えると、理解の出現がどのように起こるのかは明確ではありません。確率分布関数ジェネレーターとして単純化したり、確率的なオウム返しとして無視したりするものが、将来の研究でさらなる発見をもたらす可能性があります。進化や量子レベルの物理学に関連する、複雑なインターフェースシステムにおけるランダム性やその研究/測定-確率などの役割は、それらを説明するための確率分布関数以外の方法があるのかと考えさせられます。これについては、より明確に説明するために、さらなる研究と構造が必要です。
例えば、私はエントロピーとLLMを検索して、この論文「LLMにおける相転移の可能性の研究」と、Wolfarmの創設者で科学者のStephen Wolfarmによる関連するトークを見つけました。そのため、これらの方向性で考えることは無理からぬことです。
言語のこの性質に従う他のシグナルも、LLMのトレーニングにおいて有効な候補となる可能性があります。単語の代わりに、信号をトークン化することができます。例えば、音楽が挙げられます https://ai.googleblog.com/2022/10/audiolm-language-modeling-approach-to.html。同様に、DNAのようにこのモデルに従わない構造は、この種のモデルには適していないかもしれません。
ポイントに戻りますが、LLMの潜在能力を各分野でどのように活用するかに競争があります。私たちはよりシンプルなものから始め、後にモデルの推論能力をアプリケーションで利用できるより拡張された形式に移ります。この詳細はシリーズの第2部で取り上げます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






