大規模言語モデルの探索-パート2
大規模言語モデルの探索-パート2
効果的にLLMを使用する:情報検索、個人アシスタント、因果推論エージェント、説明可能性、階層的な制御に基づく展開。
この記事は主に自己学習のために書かれています。したがって、広く深く話を進めています。興味のある部分をスキップしたり、自分に関心のある領域を探したりすることは自由です。
以下は、LLMを微調整しようとしている間に私が興味を持ったり浮かんできたりしたいくつかの質問です。この記事はこれらの質問に答え、他の好奇心を持つ人々と情報を共有しようとする試みです。
LLMはニューラルネットワークと損失関数に基づいているので、LLMのすべてのトレーニングは監督トレーニングではないのですか?なぜそれが通常非監督トレーニングと呼ばれるのですか?LLMのトレーニングが実際にどのように機能するかを説明するために、短い文章でLLMをトレーニングできますか?マスクされたLMと因果LMとは何ですか?Transformerアーキテクチャの直感を1枚の図で説明できますか?LLMの非監督トレーニングとは具体的に何を意味していますか?ChatGPTの主な設計者であるIlya Suverskarは、なぜ非監督トレーニングを機械学習の聖杯と考えているのですか?LLMの出現/理解とは何ですか?
LLMの使用例は何ですか?なぜLLMが生産性アシスタントとして最適なのですか?情報検索のためのベクトルDB/埋め込みパターンとは何ですか?LLMはテキスト以外のタスクにも使用できますか?因果推論とは何ですか?LLMの問題は何ですか?Yan LeCunのような専門家はなぜ現在のLLMが絶望的だと考えているのですか?LLMは説明可能ですか?説明できない場合、効果的に使用する方法はありますか?
- 「大規模な言語モデルの探索-パート3」
- 強化学習:SARSAとQ-Learning – 第3部
- 「完璧なコンビ:adidasとCovision MediaがAIとNVIDIA RTXを使用して写真のようなリアルな3Dコンテンツを作成」
なぜLLMを微調整/再トレーニングする必要があるのですか?LLMのトレーニングが困難な理由は何ですか?QuantisationとLoRAは大規模なLLMのトレーニングにどのように役立ちますか?QuantisationとLoRAはどのように機能しますか?事前トレーニングされたLLMを効果的に微調整する方法は何ですか?Instruct Tuningとは何ですか?Self Instructとは何ですか?Instruct Tuningの高品質なトレーニングデータセットをどのように生成できますか?
まだ回答していませんLLMの能力の異なるLLMがどのように階層的に構成され、因果推論を持つ複雑な自動化を作成できるかを示すことはできますか?なぜLLMやニューラルネットから人間のような知能を作り出そうとしているのですか?これは固定翼機の発明前の鳥のような飛行を作り出すことに不気味なほど似ているように思えますか?
記事がかなり長いため、読みやすさを向上させるために3つのパートに分けて構成しました。
パート1では、LLMのトレーニングの進化について説明します。モデルのサイズがあるしきい値を超え、巨大なデータでトレーニングされた場合に起こる魔法、またはより技術的には出現を理解するための文脈を設定することが意図されています。深堀りセクションでは、これらの概念をより詳細かつ深く説明しますが、ほとんどのプログラマーにとっても理解しやすいです。
パート2では、LLMの人気のある使用例、個人アシスタント、チャットボット、カスタムデータを介した情報検索パターン(LLMの補完を伴うベクトル空間検索)について簡単に説明します。また、モデルのメンタルモデルとNLUがより強力な使用例になる可能性についてのヒントも探ります。この文脈では、監督トレーニングの強みとLLMモデルの弱点である説明可能性の欠如や事実と妄想の判断の難しさとの対比を通じて、LLMモデルの1つの主な制限についても探ります。また、制御の階層によって信頼性の低いシステムを信頼性の高いシステムにするコンピュータシステムでの効果的な使用方法(例えば、ChatGPTの日常的な使用など)と他の使用例にどのように拡張できるかについても探ります。
パート3では、カスタムドメインでのLLMのトレーニングに関連するいくつかの概念について説明します。特に、それが単純なベクトル空間情報検索パターンよりもはるかに強力である方法と、実際のデータでは非常に簡単ではないことに焦点を当てています。Quantisation技術が非常に大規模なLLMを世界に開放し、これに加えてトレーニングパラメータを削減する概念がLLMの微調整を民主化した方法について探ります。効果的な微調整の主な技術であるInstruct tuningと、これまでに学んだすべての概念を備えた高品質のInstruct tuningトレーニングデータセットの入手困難さという最大の実践的な問題を解決する方法についても探ります。
将来のセクションでは、LLMの理解部分を活用し、制御の階層を使用してこれらの強力なシステムをAI/MLシステムの補完に活用するコンセプトについて議論します。
主な使用例の1つは、生産性向上 — スマートアシスタントです。
これは重要で広く使われるLLMのパターンです。McKinsey & Companyによる「Generative AIの経済的潜在力 – 次世代の生産性フロンティア(2023年6月)」という論文では、さまざまな形式で適用されたLLMのこの側面が現在のさまざまな業界の仕事を変え、世界経済に数兆ドルをもたらすと予測されています。
具体的な内容に入る前に、最近のトークにおいて著者が「より信頼性の高いシステムは、より信頼性の低いシステムから構築できる」と述べていることがあります。有名なTCP/IPスタックデザインから引用しています。IPレイヤーのような信頼性の低い/パケットロスのあるレイヤーは、TCPレイヤーの伝送制御および再送信ロジック(パケットロスを検出した場合)によって信頼性が確保されるという、階層的な設計があります。
アシスタントタイプのユースケースも階層的であり、LLMの幻覚のような弱点は、通常人間による高度で優れた制御によって克服されます
これは、より認知的なモデルがより少ないモデルに対しても適用されます。これがこのユースケースが広範かつ堅牢な理由です。Github Co-pilotを使用するソフトウェアエンジニアは、典型的な例です。モデルの推論は、出力を効果的に使用し、良い点を取り入れたり、ネガティブな点(エラーや幻覚)を微調整したり、破棄したりすることができるより良い制御とペアリングされます。人間のスキルが高ければ高いほど、これらのモデルをより効率的に使用できます。このアプローチの高い効率の向上は、導入以来非常に短い時間でプログラミングやドメインアシスタントとしての評価が高まっています。同様のことは、他の分野のためにこれらのアシスタントが開発される場合も真であり、最近の例としてGoogleによるMed-Palm2が挙げられます。Med-Palm2は、医療分野で医師の助けになる驚くほどの能力を持っています。
このより良い制御のニーズは、暗黙的に説明可能性の概念と結びついています。
説明可能性とその影響
ここでは、アシスタントのユースケース、階層的なアプローチ、およびMed_Palm2を述べました。これには説明可能性という概念が暗黙的に含まれています。
説明可能性は現在のLLMの弱点です。
以下はYann LeCunのコメントです。彼はそれをかなり率直に述べています。
自己回帰型LLMは駄目です!アシスタントとしては優れていますが、事実に基づいた一貫した回答を提供するのは得意ではありません(幻覚のため)、最新の情報を考慮に入れることもできません(常に時代遅れのトレーニング)
自己回帰型LLMは絶望的です。事実にすることはできず、(大規模な再設計なしに)修正することはできません…
説明不能性の欠如により、より高いレベルの制御とより少ない自動化が強制されます。この前に、このより高いレベルの制御のドメインアシスタントのユースケースを探求しました。また、ChatGPTを通じて、私たち人間がより高いレベルの制御を行うユースケースを日々経験しています。
しかし、AI/MLについて話すとき、私たちはコンピュータベースの自動化を目指しています。LLMではないシナリオでの例を挙げて、考えるためのヒントを提供しましょう。畳み込みニューラルネットワークがコンピュータビジョンを革新し、説明不能性の問題を効果的に克服している方法を探ってみましょう。
最高のコンピュータビジョンモデルでも画像の理解はありません。そのため、これらのモデルは敵対的な画像で他の予測を行うように簡単に騙されます。医療画像から疾患を検出するためにトレーニングされたモデルは、操作されたかどうかや敵対的な画像に類似したものを画像から検出するかどうかを信頼できません。(カメラに依存する自動運転車も、境界の場合に誤解釈することがあり、致命的な結果を招くことがあります)
より良い制御 – ここでは医師がこれを確認する必要があります。しかし、医師が画像の細部を詳細に確認するならば、まず自動化の意味がありません。これが、コンピュータビジョンにおいてこのようなユースケースの視覚的な説明可能性が役立つ理由です。医師は、モデルがなぜそのような予測をしたのかについての説明が必要です。コンピュータビジョンでは、これはGrad-CAMのアルゴリズムを使用して視覚的に表現することができます。以下の図では、モデルが実際にフレンチホルンを含むと予測するために関連する特徴を抽出していることが確認できます。症例が明確でない医療分野では、これにより効果的な制御を持つ迅速な診断が可能となります。

データに基づく他のDLモデルにおいて、説明可能性とはモデルが予測のために選択した特徴の組み合わせを指します。説明可能性は、ML全体で難しい問題であり、特にDLはルールベースのエンジンや人間が関連付けるには特徴があまりにも多い場合に使用されます。しかし、教師あり学習のMLシステムでは、特徴を削除してモデルの出力にどのように影響するかを確認したり、他の類似した手法を使用することで、ある程度まで可能です。
このようなテクニックがLLMで開発されるまで、幻覚を特定する方法はないため、厳しい制御が必要です。もう一つの選択肢は、一部の間違いがあまり重要でないシナリオで使用することです。セクション3では、LLMを使用してLLMをトレーニングするためのトレーニングデータを作成するユースケースを見ていきます。製品の推奨エンジンなど、間違いが少なくても問題ないユースケースは他にもあります。
LLMを検索エンジンとして使用する(LLM拡張情報検索)
これは非常に人気があり、頻繁に新しいプレーヤーが登場するユースケースです。なぜこれがキーワードインデックス技術に基づく従来のエンタープライズ検索よりも優れているのか不思議に思うでしょう。
ここでの主な技術的な直感は、ベクトル埋め込みと類似性検索です。他のエンタープライズ検索(例:ElasticSearch)と比較して、このアプローチは文脈に基づく単語埋め込み/文埋め込みの概念を活用しています。
従来の検索エンジンでは、各単語(またはESの逆インデックスの概念)をインデックスしますが、LLMでは各文が他の文とどれだけ似ているかでグループ化されます。これにより、理論的には情報検索エージェントとしてはるかに優れています。これをより深く理解するために、TransformersがどのようにAttentionメカニズムを使用してこれを行うのか、Part 1に戻って調べる必要があります。また、この論文の最初の部分では、GPT2について詳しく説明しています。
実際には、事前学習済みモデル(人気のあるSentenceTransformersなど)とFAISS(Facebook AI Similarity Search)などのライブラリを使用して、データの高次元埋め込みまたは意味的埋め込みを計算し、ユーザーのクエリに対する同様に計算されたベクトルに関する高速な類似性検索ベースの検索を行います。埋め込みまたは類似する技術を使用せずに、FAISSや同様のテクノロジーはますます拡大するベクトルデータベース(Pinecone、Weviate、Milvusなど)です。このForbesの記事をご覧ください。
DeepDive – すべてのドキュメントはまずコンポーネント(文、段落、URLを含むドキュメント、メタデータ付き)に分割され、Sentence Transformersのようなモデルを使用してベクトル埋め込みに変換されます(N次元空間に浮かんでいると考えてください(Nは非常に大きな数)このベクトル空間内で類似したベクトルは一緒にまとめられます)。
こちらは、ローカルストレージのみを使用してSentenceTransformerとFAISSを使用したこのパターンのColabノートブックです:https://colab.research.google.com/drive/1PU-KEHq-vUpUUhjbMbrJip6MP7zGBFk2?usp=sharing。Langchainには、多くのライブラリに対するシンプルなラッパーがあり、それを使用しています。直接の方法はもう少し複雑ですが、このcolab-notebookをご覧ください。
チャンクの意味的埋め込みがベクトル埋め込みとして使用されます。たとえば、LamaCPPEmbeddingを使用している場合、モデルの評価から取得されたログットは、文を表すために最後の単語の埋め込みとして選択されているように見えます。langchain -> lmacpp(python) -> lamacpp(c++)
このアプローチの利点は、ベクトル埋め込みを計算し、データを格納し、このデータを使用することが、モデルの微調整よりも簡単であることです。欠点は、データの選択がユーザーのクエリを理解するのではなく、クエリの単語に基づいて分割され、注意力/意味的埋め込みの複雑さであることです。モデルは、前述のように、ドメインを「理解」していません。事前学習済みモデルが使用されているため、クエリを理解し、類似性検索からのコンテキストを使用して意味のある回答を生成できます。
通常、これで十分な場合がほとんどです。ただし、ChatGPTやBardのような出力の洗練度と同じ量を得ることが、この方法では難しいと感じる場合は、カスタムドメインでモデルの微調整を行うオプションがあります。
LMMを因果推論エージェントとして使用する
以前に発見した説明可能性に関連するのは、MLの因果関係の概念です(SHAP、LIME、The Book of Why – Judea Pearlがこの概念をより詳しく説明しており、ここでは範囲外です)。
平易な言葉で言えば、因果関係の理論です。初期の人間が因果関係を関連付ける方法を想像してみてください。彼らはある夜、儀式的な踊りをしていて、翌日には雨が降っていました。

これは何度か繰り返され、彼らはこの2つの事実を結びつけました。結びつけは因果思考のはしごの最初のステップですが、唯一のステップではありません。
Judea P.によると、私たちのすべてのAIシステムはこのステップにいます。 (おそらく私たち人間の多くもまだ重く存在しています)。シンプルな人々は次回も雨のために踊り続けるでしょう。さて、私たちの祖先の例では、彼らが雨が降るたびに踊ったと仮定すると、それ以外の誰かが彼らを説得するのはほとんど不可能でしょう。
ただし、「踊らなかった」のにそれでも雨が降った場合、または踊ったのに雨が降らなかった場合は除きます。最初のステップ、「結びつけ」として表現することもできます。次は「行動」、3番目は「想像」です(本に記載されているように)。
これによって、因果推論には理解が必要で、単語間の結びつけだけではないことに気づかせてくれます。
Microsoft Researchによる興味深い論文があります。それはLLMsを因果関係の発見に使用しています。
LLMベースの手法は、複数の因果関係のベンチマークで新たな最高精度を確立していることがわかりました。
私はChatGPT 4で同じプロンプトを論文と照らし合わせましたが、同じモデルで以前よりも良い結果が出ました。それはあまり意味がないかもしれませんが、それでも彼らのモデルの因果推論能力を示しています。
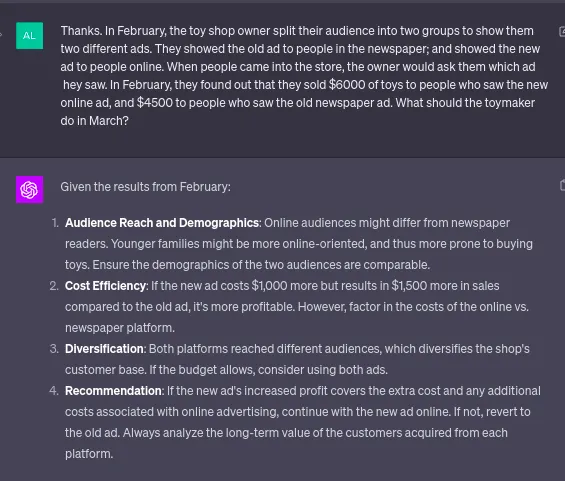
ここで注目すべきは、オンラインとオフラインの人口統計などの言及がなかったことです。GPT4モデルは、交絡因子を選び出し、データだけでなく自身の世界観に基づいて推論しています。著者によれば、LLMsはこれに完璧ではなく、間違いも起こします。
再び、私には今簡単なユースケースでこれを示すことは難しいですが、これは研究するのに興味深い分野です。特に、次の論文からの引用が好きです。それによって、彼らがミミックなのかどうかの議論を証明または反証することを回避し、能力を実用的に使用することができます。
LLMsが真に因果推論を行っているのかどうかに関係なく、彼らが特定の因果関係のタスクを実行することについての経験的に観察された能力は、人間だけに頼っている現在の因果推論の一部に有用な補完を提供するに十分な強さがあります。
つまり、これらのシステム自体を説明することは難しいですが、データセット内の変数間の因果関係を発見するためのツールとして使用することができます。 これは、高度な推論タスクにおける彼らの潜在的な可能性を示しています。
第3部では、モデルをFineTuneする方法と、モデル自体をデータ生成に活用してカスタムドメインアプリケーションでそれらを活用する方法について探究します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles