大規模なネアデデュープリケーション:BigCodeの背後に
大規模ネアデデュープリケーション:BigCodeの背後に
対象読者
大規模な文書レベルの近似除去に興味があり、ハッシュ、グラフ、テキスト処理のいくつかの理解を持つ人々。
動機
モデルにデータを供給する前にデータをきちんと扱うことは重要です。古い格言にあるように、ゴミを入れればゴミが出てきます。データ品質があまり重要ではないという幻想を作り出す見出しをつかんでいるモデル(またはAPIと言うべきか)が増えるにつれて、それがますます難しくなっています。
BigScienceとBigCodeの両方で直面する問題の1つは、ベンチマークの汚染を含む重複です。多くの重複がある場合、モデルはトレーニングデータをそのまま出力する傾向があることが示されています[1](ただし、他のドメインではそれほど明確ではありません[2])。また、重複はモデルをプライバシー攻撃に対しても脆弱にする要因となります[1]。さらに、重複除去の典型的な利点には以下があります:
- 効率的なトレーニング:トレーニングステップを少なくして、同じかそれ以上のパフォーマンスを達成できます[3][4]。
- データ漏洩とベンチマークの汚染を防ぐ:ゼロでない重複は評価を信用できなくし、改善という主張が偽りになる可能性があります。
- アクセシビリティ:私たちのほとんどは、何千ギガバイトものテキストを繰り返しダウンロードまたは転送する余裕がありません。固定サイズのデータセットに対して、重複除去は研究、転送、共同作業を容易にします。
BigScienceからBigCodeへ
近似除去のクエストに参加した経緯、結果の進展、そして途中で得た教訓について最初に共有させてください。
- Instruction-tuning Stable Diffusion with InstructPix2PixのHTMLを日本語に翻訳してください
- 🐶セーフテンソルは、本当に安全であり、デフォルトの選択肢として採用されました
- Hugging FaceとIBMは、AIビルダー向けの次世代エンタープライズスタジオであるwatsonx.aiにおいてパートナーシップを結成しました
すべてはBigScienceがすでに数ヶ月前に始まっていたLinkedIn上の会話から始まりました。Huu Nguyenは、私のGitHubの個人プロジェクトに気付き、BigScienceのための重複除去に取り組むことに興味があるかどうか私に声をかけました。もちろん、私の答えは「はい」となりましたが、データの膨大さから単独でどれだけの努力が必要になるかは全く無知でした。
それは楽しくも挑戦的な経験でした。その大規模なデータの研究経験はほとんどなく、みんながまだ信じていたにもかかわらず、何千ドルものクラウドコンピュート予算を任せられるという意味で挑戦的でした。はい、数回マシンをオフにしたかどうかを確認するために寝床から起きなければならなかったのです。その結果、試行錯誤を通じて仕事を学びましたが、それによってBigScienceがなければ絶対に得られなかった新しい視点が開かれました。
さらに、1年後、私は学んだことをBigCodeに戻して、さらに大きなデータセットで作業をしています。英語向けにトレーニングされたLLMに加えて、重複除去がコードモデルの改善につながることも確認しました[4]。さらに、はるかに小さなデータセットを使用しています。そして今、私は学んだことを、親愛なる読者の皆さんと共有し、重複除去の視点を通じてBigCodeの裏側で何が起こっているかを感じていただければと思います。
興味がある場合、BigScienceで始めた重複除去の比較の最新バージョンをここで紹介します:
これはBigCodeのために作成したコードデータセット用のものです。データセット名が利用できない場合はモデル名が使用されます。
MinHash + LSHパラメータ( P , T , K , B , R )(P, T, K, B, R) ( P , T , K , B , R ) :
- P P P パーミュテーション/ハッシュの数
- T T T Jaccard類似度の閾値
- K K K n-gram/shingleサイズ
- B B B バンドの数
- R R R 行の数
これらのパラメータが結果にどのように影響するかを理解するために、計算を数学的に説明する簡単なデモを以下に示します:MinHash Math Demo .
MinHashウォークスルー
このセクションでは、BigCodeで使用されているMinHashの各ステップ、スケーリングの問題、および解決策について説明します。英語の3つの文書の例を使用して、ワークフローを実演します:
MinHashの典型的なワークフローは次のとおりです:
- シングリング(トークン化)およびフィンガープリント(MinHashing):各ドキュメントをハッシュのセットにマッピングします。
- ローカリティセンシティブハッシング(LSH):このステップは、類似したバンドを持つドキュメントをグループ化することで比較の数を減らすためのものです。
- 重複の削除:このステップでは、重複したドキュメントを保持するか削除するかを決定します。
シングルズ
テキストを含むほとんどのアプリケーションと同様に、トークン化から始める必要があります。N-グラム、またはシングルズと呼ばれるものがよく使用されます。この例では、句読点を含まない単語レベルのトリグラムを使用します。後のセクションでnグラムのサイズがパフォーマンスにどのように影響するかについて説明します。
この操作の時間複雑度は O ( N M ) \mathcal{O}(NM) O ( N M ) であり、N はドキュメントの数、M はドキュメントの長さです。つまり、データセットのサイズに線形に依存しています。このステップは、マルチプロセッシングや分散計算による並列化で簡単にスケーリングすることができます。
フィンガープリント計算
MinHashでは、各シングルは通常、異なるハッシュ関数で複数回ハッシュ化するか、1つのハッシュ関数で複数回並べ替えることがあります。ここでは、各ハッシュを5回並べ替えることを選択します。MinHashのさまざまなバリエーションについては、MinHash – Wikipedia を参照してください。
各ドキュメント内の各列の最小値を取ることで、このドキュメントの最終的なMinHashを得ることができます。
厳密には、各列の最小値を使用する必要はありませんが、最小値は最も一般的な選択肢です。最大値、k番目に小さい値、またはk番目に大きい値など、他の順序統計量も使用できます。
実装では、これらのステップをnumpyで簡単にベクトル化することができ、時間の複雑度は O ( N M K ) \mathcal{O}(NMK) O ( N M K ) になります。ここで、Kは並べ替えの回数です。コードはDatasketchを基に修正されています。
def embed_func(
content: str,
idx: int,
*,
num_perm: int,
ngram_size: int,
hashranges: List[Tuple[int, int]],
permutations: np.ndarray,
) -> Dict[str, Any]:
a, b = permutations
masks: np.ndarray = np.full(shape=num_perm, dtype=np.uint64, fill_value=MAX_HASH)
tokens: Set[str] = {" ".join(t) for t in ngrams(NON_ALPHA.split(content), ngram_size)}
hashvalues: np.ndarray = np.array([sha1_hash(token.encode("utf-8")) for token in tokens], dtype=np.uint64)
permuted_hashvalues = np.bitwise_and(
((hashvalues * np.tile(a, (len(hashvalues), 1)).T).T + b) % MERSENNE_PRIME, MAX_HASH
)
hashvalues = np.vstack([permuted_hashvalues, masks]).min(axis=0)
Hs = [bytes(hashvalues[start:end].byteswap().data) for start, end in hashranges]
return {"__signatures__": Hs, "__id__": idx}Datasketchに詳しい方ならば、なぜライブラリが提供する便利な高レベルの関数をすべて削除する必要があるのか疑問に思うかもしれません。それは、依存関係の追加を避けたいわけではなく、並列化中に可能な限り多くのCPU計算を行いたいためです。いくつかのステップを1つの関数呼び出しに統合することで、計算リソースをより効果的に利用することができます。
1つのドキュメントの計算は他に依存していないため、良い並列化の選択肢は、datasetsライブラリのmap関数を使用することです。
embedded = ds.map(
function=embed_func,
fn_kwargs={
"num_perm": args.num_perm,
"hashranges": HASH_RANGES,
"ngram_size": args.ngram,
"permutations": PERMUTATIONS,
},
input_columns=[args.column],
remove_columns=ds.column_names,
num_proc=os.cpu_count(),
with_indices=True,
desc="Fingerprinting...",
)フィンガープリントの計算後、特定のドキュメントは整数値の配列にマッピングされます。ドキュメント間の類似性を判断するためには、このようなフィンガープリントに基づいてドキュメントをグループ化する必要があります。この段階で、局所敏感ハッシング(LSH)が登場します。
局所敏感ハッシング
LSHは、フィンガープリントの配列をバンドに分割し、各バンドには同じ数の行が含まれます。余ったハッシュ値がある場合は無視されます。ここでは、b = 2、r = 2のバンドと行を使用してドキュメントをグループ化します。
特定の位置(バンドインデックス)で2つのドキュメントが同じハッシュを共有している場合、それらは同じバケットにクラスタリングされ、候補として考慮されます。
doc_ids列の各行について、それらの2つをペアリングすることで候補ペアを生成することができます。上記のテーブルから、1つの候補ペア(0, 1)を生成することができます。
重複ペアを超えて
論文やチュートリアルでの重複排除の説明はここで終わることが多いです。しかし、それらに対してどのように対処するかという問題は残っています。一般的に、2つのオプションを選ぶことができます:
- MinHashの推定性質のため、実際のJaccard類似度を計算してシングルの重複を確認することで、実際のJaccard類似度を二重チェックすることができます。2つの集合のJaccard類似度は、共通部分のサイズを和集合のサイズで割ったものです。そして、これはすべてのペアの類似度を計算する必要がないため、クラスタ内のドキュメントにのみ焦点を当てることができます。これはBigCodeでは最初に行った方法で、かなりうまくいきました。
- それらを真陽性として扱う。ここで問題があることにすでに気づいたかもしれません:Jaccard類似度は推移的ではないため、A A AはB B Bに似ていて、B B BはC C Cに似ているが、A A AとC C Cは必ずしも類似性を共有しないということです。しかし、The Stackの実験から、すべてを重複として扱うことがモデルのパフォーマンスを最も向上させるという結果が得られました。そして、私たちは徐々にこの方法に移行しています。そして、これには時間もかかりません。ただし、データセットにこれを適用するには、データセットを調べて重複を確認し、データに基づいた判断を行うことをお勧めします。
これらのペアから、検証済みであるかどうかに関係なく、これらのペアをエッジとするグラフを構築することができます。そして、重複はコミュニティや連結成分にクラスタリングされます。実装の観点では、残念ながら、ここでdatasetsはあまり役に立ちません。なぜなら、バンドオフセットとバンド値に基づいてドキュメントをクラスタリングするgroupbyのようなものが必要になるからです。以下に試したいくつかのオプションがあります:
オプション1:伝統的な方法でデータセットを反復処理し、エッジを収集します。その後、グラフライブラリを使用してコミュニティ検出または連結成分検出を行います。
これは私たちのテストではスケールしなかったので、理由は多岐にわたります。まず、データセット全体を反復処理することは、大規模なスケールでは遅く、メモリを消費します。さらに、graphtoolやnetworkxなどの一般的なグラフライブラリは、グラフの作成に多くのオーバーヘッドがあります。
オプション2:より効率的なgroupby操作を許すために、daskなどの人気のあるPythonフレームワークを使用する。
しかし、まだ反復処理とグラフの作成の遅さの問題があります。
オプション3:データセットを反復処理し、Union-Findデータ構造を使用してドキュメントをクラスタリングします。
これは反復処理にほとんどオーバーヘッドを追加しませんし、VoAGIデータセットでは比較的うまく動作します。
for table in tqdm(HASH_TABLES, dynamic_ncols=True, desc="クラスタリング..."):
for cluster in table.values():
if len(cluster) <= 1:
continue
idx = min(cluster)
for x in cluster:
uf.union(x, idx)オプション4:大規模なデータセットの場合、Sparkを使用します。
LSHまでのステップは並列化できることをすでに知っていますが、それはSparkでも実現可能です。さらに、Sparkは分散groupByをデフォルトでサポートしており、[18]などの連結成分検出のアルゴリズムも簡単に実装できます。SparkのMinHashの実装を使用しなかった理由は、これまでのすべての実験がDatasketchから派生しており、Sparkとは異なる実装方法を使用しているためです。そして、削除実験の別のウサギの穴に入らずに、そこから学んだ教訓と洞察を継続することを確実にしたいからです。
edges = (
records.flatMap(
lambda x: generate_hash_values(
content=x[1],
idx=x[0],
num_perm=args.num_perm,
ngram_size=args.ngram_size,
hashranges=HASH_RANGES,
permutations=PERMUTATIONS,
)
)
.groupBy(lambda x: (x[0], x[1]))
.flatMap(lambda x: generate_edges([i[2] for i in x[1]]))
.distinct()
.cache()
)[18]を基に実装されたSparkによるシンプルな連結成分アルゴリズムです。
a = edges
while True:
b = a.flatMap(large_star_map).groupByKey().flatMap(large_star_reduce).distinct().cache()
a = b.map(small_star_map).groupByKey().flatMap(small_star_reduce).distinct().cache()
changes = a.subtract(b).union(b.subtract(a)).collect()
if len(changes) == 0:
break
results = a.collect()また、クラウドプロバイダーのおかげで、GCP DataProcなどのサービスを使用して、簡単にSparkクラスターをセットアップすることができます。最終的には、1.4 TBのデータを4時間未満で$15の予算で重複排除するプログラムを快適に実行できます。
品質が重要です
はしごを登ることは月にはたどり着けません。それがなぜ正しい方向であり、正しく使用しているかを確認する必要があります。
初めに、私たちのパラメータは主にCodeParrotの実験から継承され、私たちの削除実験ではそれらの設定がモデルの下流パフォーマンスを改善することが示されました[16]。その後、このパスをさらに探索し、次のことを確認しました[4]:
- 近似重複排除は、より小さなデータセット(6 TB対3 TB)でモデルの下流パフォーマンスを向上させます
- まだ限界はわかっていませんが、より積極的な重複排除(6 TB対2.4 TB)はパフォーマンスをさらに向上させることができます:
- 類似度の閾値を下げる
- シングルサイズを増やす(unigram → 5-gram)
- 偽陽性チェックを廃止する(わずかな割合の偽陽性を失うことが許容できるため)
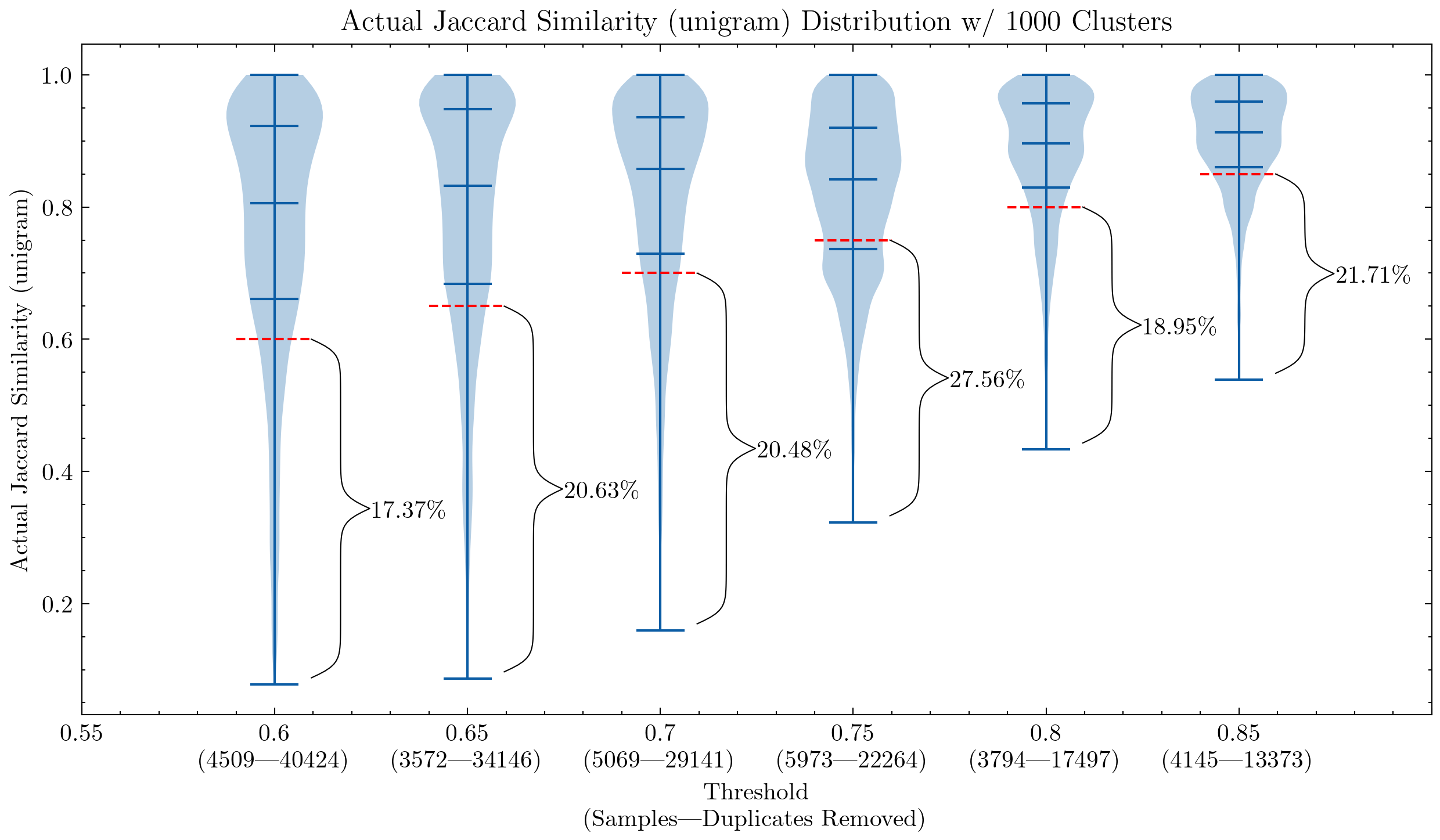
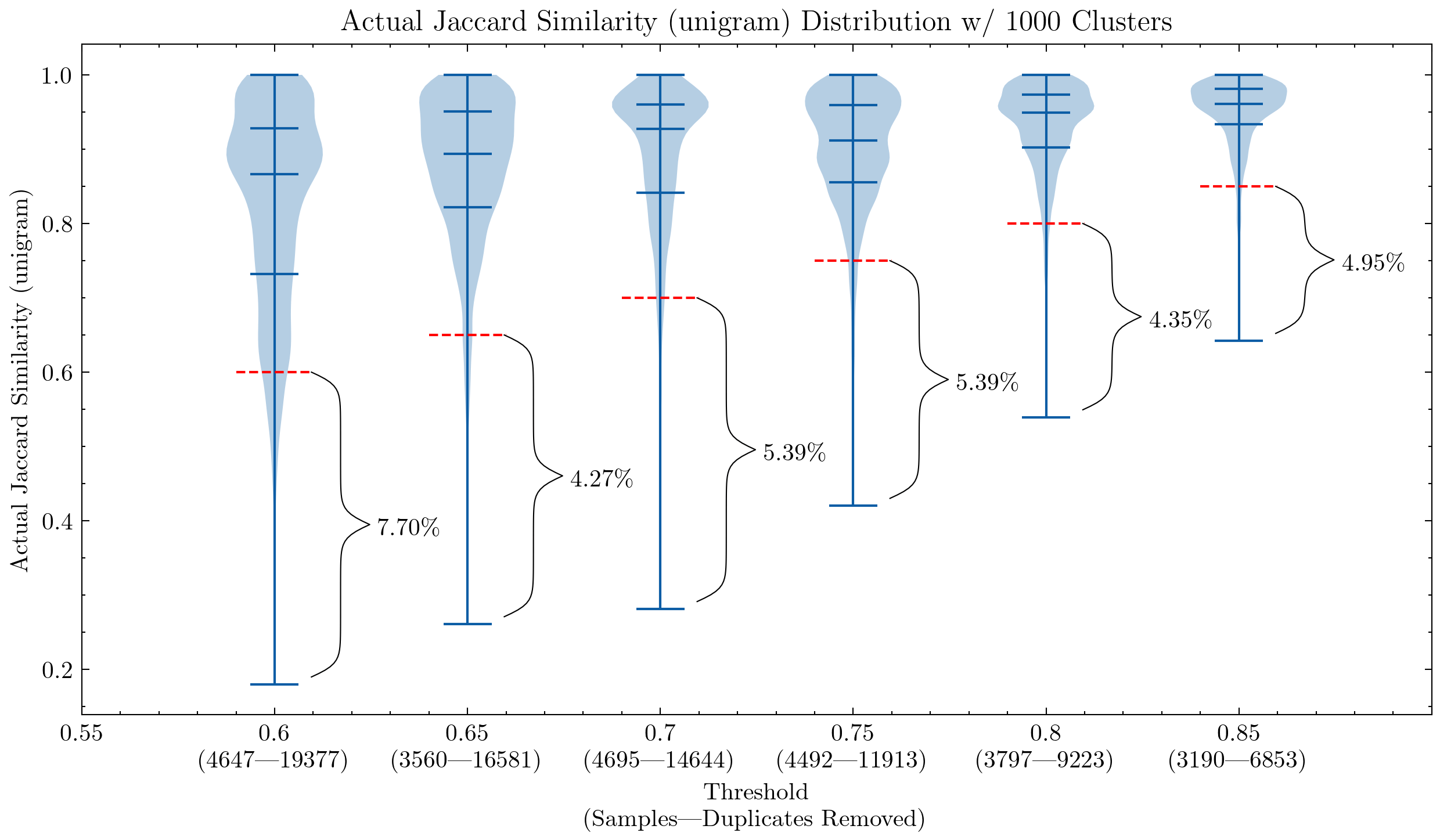
画像:類似度の閾値とシングルサイズの影響を示す2つのグラフ。最初のグラフはunigramを使用し、2番目のグラフは5-gramを使用しています。赤い破線は類似度のカットオフを示しており、このカットオフ以下のドキュメントは偽陽性と見なされます。クラスタ内の他のドキュメントとの類似度が閾値よりも低いためです。
これらのグラフは、CodeParrotやStackの初期バージョンでは偽陽性を再確認する必要がある理由を理解するのに役立ちます。unigramを使用すると、多くの偽陽性が生成されます。また、シングルサイズを5-gramに増やすことで、偽陽性の割合が大幅に減少することも示しています。重複排除の積極性を保つためには、より小さな閾値が望ましいです。
さらに、追加の実験では、閾値を下げることで、最も削除したいセグメントに高い類似性のペアを持つドキュメントがより多く削除されることが示されました。
スケーリング
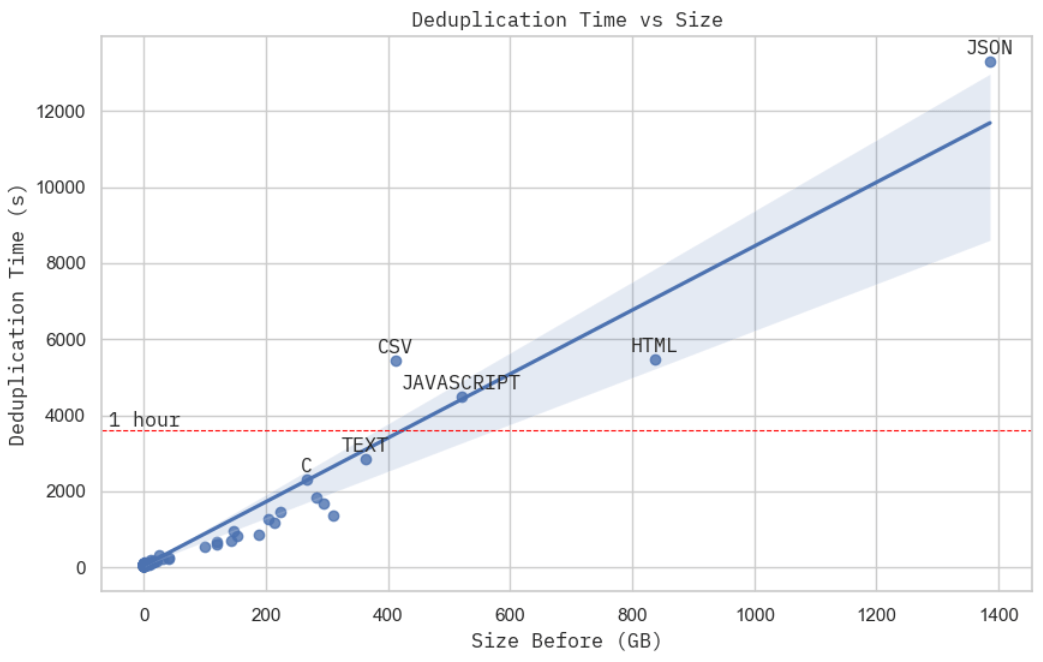
画像:重複排除時間と生データセットサイズの関係。これはGCP上の15台のc2d-standard-16マシンを使用して達成され、それぞれ約$0.7かかりました。

画像:JSONデータセットを処理する際のクラスタのCPU使用率のスクリーンショット。
これは最も厳密なスケーリングの証拠ではありませんが、固定された計算予算での重複排除時間は、データセットの物理的なサイズにほぼ比例しています。JSONデータセットを処理する際のクラスタのリソース使用状況を詳しく見ると、MinHash + LSH(ステージ2)が総実際の計算時間(ステージ2 + 3)を支配していることがわかります。前の分析からわかるように、これはデータセットの物理的なボリュームに比例するO(NM)です。
注意して進んでください
重複排除によってデータの探索と分析が不要になるわけではありません。また、これらの重複排除の発見はStackに対して有効であることを意味しますが、他のデータセットや言語に適用できるわけではありません。これはより良いデータセットを構築するための良い第一歩であり、データの品質フィルタリング(脆弱性、有害性、バイアス、生成されたテンプレート、個人情報など)などのさらなる調査がまだ非常に必要です。
トレーニング前にデータセットで同様の分析を行うことをお勧めします。たとえば、時間と計算予算が厳しい場合、重複排除を行ってもあまり役に立たないかもしれません。@geiping_2022は、部分文字列の重複はモデルの下流パフォーマンスを向上させなかったと述べています。既存のデータセットは使用する前に徹底的に調査する必要があります。たとえば、@gao_2020は、Pile自体とその分割のみが重複排除されており、下流のベンチマークに対して積極的に重複排除は行わず、その決定は読者に任せていると述べています。
データ漏洩とベンチマークの汚染について、まだ多くの研究が必要です。私たちは、HumanEvalがPythonのGitHubリポジトリの1つに公開されたため、コードモデルを再トレーニングする必要がありました。近い重複排除の結果も、MBPP [19]、コーディングの最も人気のあるベンチマークの一つが、多くのLeetcodeの問題と非常に類似していることを示唆しています(例:MBPPのタスク601は基本的にはLeetcode 646、タスク604 ≃ Leetcode 151)。そして、私たちはみんなが知っているように、GitHubはこれらのコーディングの課題と解決策に乏しくありません。もし悪意を持った人がすべてのベンチマークをPythonスクリプトなどの形でアップロードし、トレーニングデータを汚染すると、さらに困難になるでしょう。
今後の方向性
- 部分文字列の重複排除。英語では一部の利点が示されましたが、コードデータにも適用すべきかどうかはまだ明確ではありません。
- 繰り返し:1つのドキュメント内で複数回繰り返される段落。@rae_2021は、これらを検出して削除する方法について興味深いヒューリスティックを共有しました。
- モデルの埋め込みを使用した意味的な重複排除。スケーリング、コスト、消去実験、近くの重複排除とのトレードオフなど、別の研究課題です。これについていくつかの興味深いアプローチがありますが、まだ結論を出すためにはより具体的な証拠が必要です(例:@abbas_2023のテキスト重複排除の参考文献は、主な主張がSOTAであるのではなく、重複排除が役立つという@lee_2022aです)。
- 最適化。常に最適化の余地があります:より良い品質評価、スケーリング、下流のパフォーマンス影響分析など。
- また、別の視点で物事を見る必要があります:近い重複排除がどの程度パフォーマンスに悪影響を与え始めるのか?類似性が冗長性ではなく多様性として必要なのはどの程度ですか?
クレジット
バナー画像には、Noto Emoji(Apache 2.0)の絵文字(ハグフェイス、サンタ、ドキュメント、ウィザード、ワンド)が含まれています。このブログ記事は、ジェネレーティブAPIを使用せずに誇らしげに書かれています。
BigScienceのHuu Nguyen @HuuとHugo Laurençon @HugoLaurenconへの大きな感謝を表します。BigCodeの皆さんも途中での助けに感謝します!もし何かエラーを見つけた場合は、お気軽にご連絡ください:mouchenghao at gmail dot com。
サポートリソース
- Datasketch(MIT)
- simhash-pyとsimhash-cpp(MIT)
- Deduplicating Training Data Makes Language Models Better(Apache 2.0)
- Gaoya(MIT)
- BigScience(Apache 2.0)
- BigCode(Apache 2.0)
参考文献
- [1]:Nikhil Kandpal、Eric Wallace、Colin Raffel、Deduplicating Training Data Mitigates Privacy Risks in Language Models、2022
- [2]:Gowthami Somepalli、他、Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models、2022
- [3]:Katherine Lee、Daphne Ippolito、他、Deduplicating Training Data Makes Language Models Better、2022
- [4]:Loubna Ben Allal、Raymond Li、他、SantaCoder:Don’t reach for the stars!、2023
- [5]:Leo Gao、Stella Biderman、他、The Pile:An 800GB Dataset of Diverse Text for Language Modeling、2020
- [6]:Asier Gutiérrez-Fandiño、Jordi Armengol-Estapé、他、MarIA:Spanish Language Models、2022
- [7]:Jack W. Rae、Sebastian Borgeaud、他、Scaling Language Models:Methods, Analysis & Insights from Training Gopher、2021
- [8]:Xi Victoria Lin、Todor Mihaylov、他、Few-shot Learning with Multilingual Language Models、2021
- [9]:Hugo Laurençon、Lucile Saulnier、他、The BigScience ROOTS Corpus:A 1.6TB Composite Multilingual Dataset、2022
- [10]:Daniel Fried、Armen Aghajanyan、他、InCoder:A Generative Model for Code Infilling and Synthesis、2022
- [11]:Erik Nijkamp、Bo Pang、他、CodeGen:An Open Large Language Model for Code with Multi-Turn Program Synthesis、2023
- [12]:Yujia Li、David Choi、他、Competition-Level Code Generation with AlphaCode、2022
- [13]:Frank F. Xu、Uri Alon、他、A Systematic Evaluation of Large Language Models of Code、2022
- [14]:Aakanksha Chowdhery、Sharan Narang、他、PaLM:Scaling Language Modeling with Pathways、2022
- [15]:Lewis Tunstall、Leandro von Werra、Thomas Wolf、Natural Language Processing with Transformers、Revised Edition、2022
- [16]:Denis Kocetkov、Raymond Li、他、The Stack:3 TB of permissively licensed source code、2022
- [17]:Rocky | Project Hail Mary Wiki | Fandom
- [18]:Raimondas Kiveris、Silvio Lattanzi、他、Connected Components in MapReduce and Beyond、2014
- [19]:Jacob Austin、Augustus Odena、他、Program Synthesis with Large Language Models、2021
- [20]:Amro Abbas、Kushal Tirumala、他、SemDeDup:Data-efficient learning at web-scale through semantic deduplication、2023
- [21]:Edith Cohen、MinHash Sketches:A Brief Survey、2016
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






