大学フットボールのカンファレンス再編-回帰
大学フットボールのカンファレンス再編-回帰' can be condensed to '大学フットボールカンファレンス再編-回帰
私の会議再編シリーズの第2部へようこそ!去年の夏、会議再編がフルスイングであった時、Tony Altimore氏がTwitterで公表した研究が私にインスピレーションを与え、私自身の会議再編分析を行うことになりました。このシリーズは4つのパートに分かれており(その全体的な目的については第1部に記載されています)、以下のような内容です:
- カレッジフットボールの会議再編 – Pythonによる探索的データ分析
- カレッジフットボールの会議再編 – 回帰
- カレッジフットボールの会議再編 – クラスタリング
- カレッジフットボールの会議再編 – node2vec
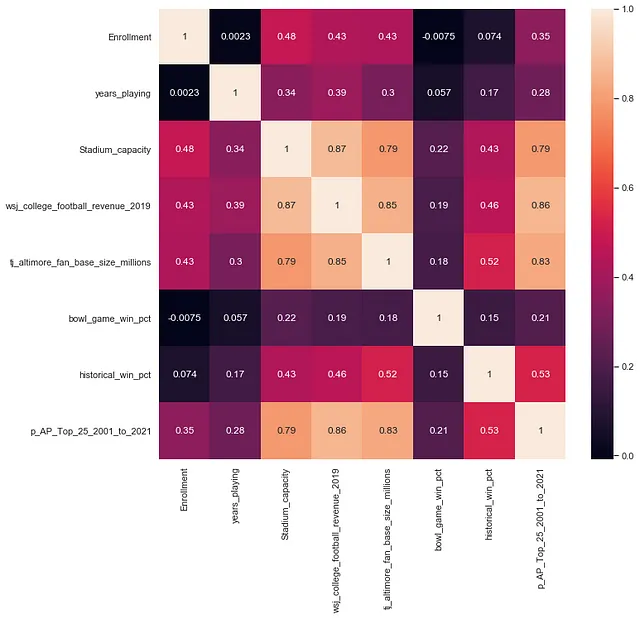
このシリーズの各パートが、大学フットボールという愛されたスポーツの未来に新しい視点を提供することを願っています。第1部を読まれていない方のために簡単な要約をすると、私はウェブ上のさまざまな情報源から独自のデータセットを作成しました。これらのデータには、各FBSプログラムに関する基本情報、すべての大学フットボールのライバルリーの非カノニカルな近似、スタジアムのサイズ、歴史的な実績、APトップ25投票の出場頻度、AAUまたはR1機関であるかどうか(Big TenとPac 12のメンバーシップには歴史的に重要)、NFLドラフトでの選手の数、2017年から2019年のプログラム収益のデータ、最近の大学フットボールのファンベースの推定値が含まれています。実際には、スタジアムの収容人数、2019年の収益、歴史的なAPトップ25の出場頻度と、Tony Altimore氏の分析で推定されたファンベースのサイズとの間には強い相関関係があります:
教師あり学習
では、これが私を考えさせました:単純な回帰モデルを作成して、ファンベースのサイズを推定することはできるでしょうか?
機械学習は大まかに教師あり学習と教師なし学習に分けることができます。教師あり学習では、事前に定義された離散的なクラスまたは連続変数を予測することが目標です。教師なし学習では、データの中に非明示的なトレンドを発見することが目標です。回帰は、予測対象が連続変数である教師あり学習の一種です。ShervineとAfshine Amidiによってまとめられた素晴らしいリファレンスガイドとリソースがあります(日本語訳されています…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「AIは本当に面接に合格するのを助けてくれるのでしょうか?」
- Streamlitの新しいConnections機能とインタラクティブなPlotlyマップでアプリを強化する
- シミュレーション101:伝導熱伝達
- 「ChatGPTを使用して完全な製品を作成するために学んだ7つの教訓」
- ダイナミックAIプロジェクト見積もり’ (Dainamikku AI purojekuto mitsumori)
- 「あなたのLLMアプリを守る必読です!」
- ファイル管理の効率化:サーバーまたはサーバー上で実行されているDockerコンテナーにおけるファイルの接続と変更をSFTPを使用してSublime Textで行うためのガイド





