合成データプラットフォーム:構造化データのための生成AIの力を解き放つ
合成データプラットフォーム:生成AIの力を解き放つ

機械学習や深層学習モデルの作成は非常に簡単です。現在では、モデルの作成プロセス全体を自動化するだけでなく、特定のデータセットに最適なモデルを選択するためのさまざまなツールやプラットフォームが利用できます。
モデルを作成して問題を解決するためには、問題を表す必要な属性を含んだデータセットが必要です。たとえば、患者の糖尿病の経歴を表すデータセットを見てみましょう。年齢、性別、血糖値などの特定の列が重要な属性であり、糖尿病の有無を予測する上で重要な役割を果たします。糖尿病予測モデルを構築するために、公開されている複数のデータセットを見つけることができます。しかし、データがすぐに利用可能でない場合や非常に偏っている場合など、データが利用できない問題を解決するのは困難かもしれません。
合成データとは何ですか?
ディープラーニングアルゴリズムによって生成された合成データは、データへのアクセスがプライバシーの制約によって制限されている場合や、元のデータを特定の目的に合わせて拡張する必要がある場合に、元のデータの代わりに使用されることがよくあります。合成データは、統計的な特性を再現することによって実データを模倣します。実データのトレーニングを受けた後、合成データ生成器は、実データのパターン、分布、依存関係に非常に近いデータを任意の量生成することができます。これにより、類似したデータを生成するだけでなく、新しい分布などのデータに特定の制約を導入するのにも役立ちます。合成データが重要な役割を果たすいくつかのユースケースを探ってみましょう。
- 機密データの生成:銀行、保険、ヘルスケア、さらには通信などのデータは非常に機密性が高い場合があります。このデータにアクセスするには通常、各プロジェクトごとに特別な許可が必要です。合成データ生成はこれらのデータ資産を開放し、特徴量の作成、ユーザーの行動の理解、モデルのテスト、新しいアイデアの探索に使用することができます。
- データの再バランス:極度に偏ったデータは、合成データ生成器を使用して効果的かつ簡単に再バランスすることができます。単純なアップサンプリングよりも優れており、SMOTEのようなより洗練された方法よりも優れている場合もあります。
- 欠損データポイントの補完:データを扱う際には、欠損値が非常に厄介な問題です。これらの空白を意味のある合成データポイントで埋めることで、サンプルの読み取りがより有益なものになります。
合成データはどのように生成されますか?
合成データの生成には、生成型AIモデルが重要です。なぜなら、これらのモデルは元のデータセットで明示的にトレーニングされ、その特性と統計的属性を再現することができるからです。生成型AIモデル(例:生成的敵対ネットワーク(GAN)または変分オートエンコーダ(VAE))は、基になるデータを理解し、現実的で代表的な合成インスタンスを生成します。
数多くのオープンソースおよびクローズドソースの合成データ生成器が存在しており、一部は他よりも優れています。合成データ生成器のパフォーマンスを評価する際には、精度とプライバシーの2つの側面に注目することが重要です。合成データの精度は高くなければならず、元のデータに過適合することなく、元のデータに存在する極値をプライバシーを危険にさらすことなく処理する必要があります。一部の合成データ生成器は、自動的なプライバシーと精度のチェックを提供しています。これらを最初に試すことは良いアイデアです。MOSTLY AIの合成データ生成器は、このサービスを無料で提供しており、メールアドレスだけでアカウントを設定できます。
合成データの利点
合成データは定義上、個人データではありません。そのため、GDPRなどのプライバシー法には適用されず、データサイエンティストは合成データセットのバージョンを自由に探索することができます。合成データは、パターンや相関関係を壊さずに行動データを匿名化するための最良のツールの1つでもあります。これらの2つの特性により、個人データが使用されるすべての状況で特に有用です。シンプルな分析から洗練された機械学習モデルのトレーニングまで。
ただし、プライバシーだけがユースケースではありません。合成データ生成は、次のようなユースケースでも使用できます:
- データの拡張:トレーニングデータを多様化してモデルのパフォーマンスを向上させるプロセスに役立ちます。
- データの補完:欠損したデータポイントを意味のある合成データで補完します。
- データの共有:組織の壁を超えて安全に共有できます。研究の共同作業や実データを使用した製品のデモに適しています。
- 再バランス:クラスのバランスの問題を解決します。
- ダウンサンプリング:元のデータと同じ見た目と意味を持つ大規模なデータセットの小規模バージョンを作成します。初期のデータ探索、計算コストと時間の削減に役立ちます。
最も人気のある合成データ生成ツール
合成データを生成するために、市場で利用可能なさまざまなツールを使用することがあります。これらのツールのいくつかを探索し、それらがどのように機能するかを理解しましょう。
- MOSTLY AI: MOSTLY AIは、構造化された合成データの作成において先駆的なリーダーです。これにより、誰でも高品質な、製品のような合成データをアナリティクス、AI/MLの開発、データの調査に生成できます。データチームは、実際の匿名化されたデータやダミーデータを使用する際の倫理的および実用的な課題を克服する方法でデータセットを作成、修正、共有することができます。
- SDV: 合成データ生成のための最も人気のあるオープンソースのPythonライブラリです。最も洗練されたツールではありませんが、高い精度が必須ではないより単純なユースケースには十分な機能を果たします。
- YData: AzureまたはAWSマーケットプレイスで合成データ生成を試したい場合、YDataのジェネレーターが両プラットフォームで利用可能で、AIおよび機械学習モデルのためのデータを生成するためのGDPRに準拠した方法を提供しています。
合成データツールと企業の包括的なリストについては、以下のリンクにカスタムされたリストがあります。
これらの上記で説明したツールやライブラリを使用して合成データを生成する利点と欠点について説明しましたので、市場で利用可能で使いやすいベストなツールの1つであるMostly AIの使用方法を見てみましょう。
MOSTLY AIは、企業が機械学習、高度な分析、ソフトウェアテスト、データ共有などのさまざまなユースケースに対して高品質でプライバシーが保護された合成データを生成するのを支援する合成データ作成プラットフォームです。MOSTLY AIは、相関関係、分布、特性などの元のデータの統計的側面を学習する専用のAIパワードアルゴリズムを使用して合成データを生成します。これにより、MOSTLY AIは、データ主体のプライバシーを保護しながら、実際のデータを統計的に代表する合成データを生成することができます。
合成データは、プライベートであるだけでなく、使いやすく、数分で作成することができます。このプラットフォームには、生成型AIによって駆動された使いやすいインターフェースがあり、組織は既存のデータを入力し、適切な出力形式を選択し、数秒で合成データを生成することができます。合成データは、データのプライバシーを保護しながら、さまざまな目的に使用する必要がある組織にとって有益なツールです。この技術は使いやすく、高品質で統計的に代表的な合成データを迅速に作成します。
MOSTLY AIからの合成データは、CSV、JSON、XMLなどのさまざまな形式で提供されます。SAS、R、Pythonなど、さまざまなソフトウェアプログラムと組み合わせて使用することができます。さらに、MOSTLY AIは、合成データの生成器、データエクスプローラー、データ共有プラットフォームなど、さまざまなツールとサービスを提供しており、組織が合成データを使用するのをサポートします。
MOSTLY AIプラットフォームの使用方法を探索しましょう。以下のリンクを訪れてアカウントを作成することから始めることができます。
MOSTLY AI: 合成データ生成とナレッジハブ – MOSTLY AI
アカウントを作成したら、データ生成に関連するさまざまなオプションから選択できるホームページが表示されます。
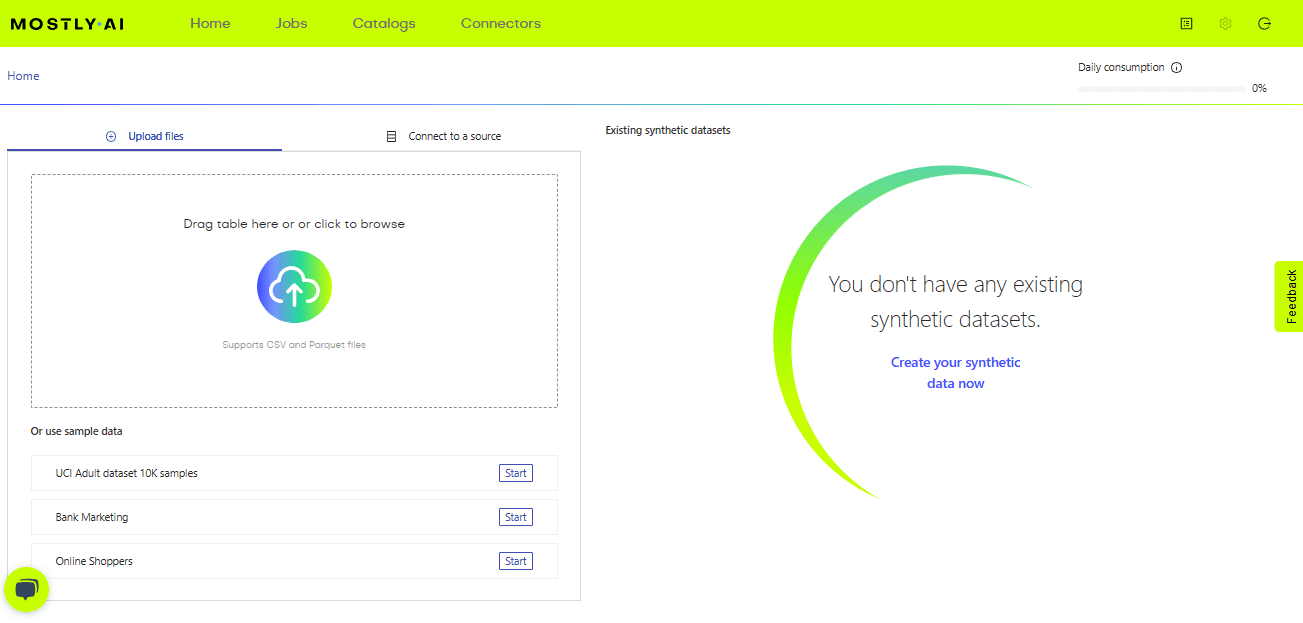
上記の画像でわかるように、ホームページでは、合成データを生成したい元のデータセットをアップロードするか、試すためにサンプルデータを使用することができます。必要に応じてデータをアップロードすることができます。
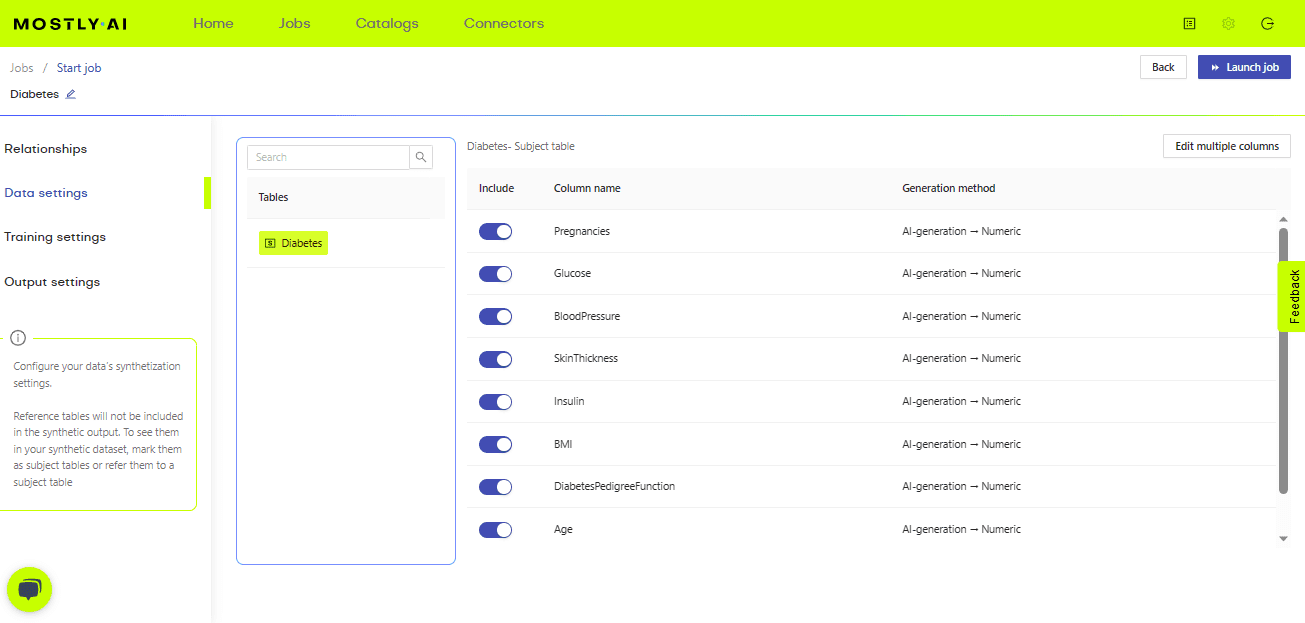
上記の画像でわかるように、データをアップロードすると、生成する必要のある列やデータ、トレーニング、出力に関連するさまざまな設定を行うことができます。
これらのプロパティを要件に応じて設定したら、データを生成するために「ジョブの開始」ボタンをクリックする必要があります。データはリアルタイムで生成されます。MOSTLY AIでは、毎日無料で10万行のデータを生成することができます。
これは、必要なデータプロパティを設定し、リアルタイムで合成データを生成するためにMOSTLY AIを使用する方法です。問題を解決しようとしている場合に応じて、複数のユースケースがあります。データセットでこれを試して、このプラットフォームがどれだけ役立つかをご意見いただければ幸いです。 Himanshu Sharmaは、製品リーダーシップ研究所で応用データサイエンスの修士号を取得しました。Pythonプログラミング言語/データ分析の経験を持つ自己励起型のプロフェッショナルです。データサイエンス、製品管理の分野で自分の名前を刻みたいと考えています。VoAGIによるAI分野でのトップライターに選ばれた、技術的なコンテンツライティングの専門知識を持つ積極的なブロガーです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
