南アメリカにおける降水量と気候学的なラスターデータの活用
'南アメリカの降水量と気候学的なラスターデータの利用'
Google Colabを使用してINPEからMERGE降水量およびその他の気候学的製品にアクセスして包括的な天気情報を取得する方法
導入
2023年にエルニーニョ現象が強まる中で、気候学的および降水データは、その影響を解読するために、地球または地域のスケールでの気象パターンと気候ダイナミクスへの影響を解読するために、基本的な役割を果たしています。降水データに関しては、CHIRPS(米国地質調査所による気候ハザードグループ赤外線降水量データセット)とNASAによって開発されたIMERGE(GPMの統合多衛星データ取得)が世界的に認識されており、GPMはグローバル降水量測定ミッションを示しています。このミッションでは、衛星ネットワークを利用して包括的な世界的な降雨量の推定を提供しています。これらの製品はグローバルモデルに適していますが、南米のシナリオに特化していません。
このような文脈の中で、ブラジル国立宇宙研究所(INPE)は、南米に特化した日次降水量のラスターデータを提供しています。この製品はMERGEとして知られ、IMERGE/GPMモデルに依存していますが、数千の現地の雨量計とのキャリブレーションにより、バイアスのない結果を保証しています(Rozante et al. 2010、Rozante et al. 2020)。INPEは、月平均、日平均などの追加の気候データも提供しています。
図1は、南米の2015年の総降水量を左側に、エルニーニョが存在しなかった前年と比較した降水異常を右側に示しています。
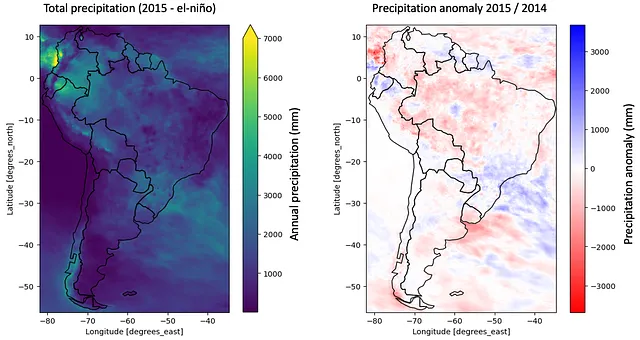
図から、アマゾンの生物圏を含む広範な地域で負の異常が見られ、前年と比べて最大2,000mmの降雨量が少なくなっていることがわかります。
- DatabricksでカスタムDockerコンテナ内でPython Wheelタスクを実行する
- デノイザーの夜明け:表形式のデータ補完のためのマルチ出力MLモデル
- Hugging Face Datasets での作業
これらのリソースは、流域や貯水池の管理、重要なイベントのモニタリング、および精密農業など、多様なアプリケーションにおいて非常に価値があります。しかし、これらのデータセットをダウンロードして操作する際には、複雑な手順が必要であり、その効果的な利用が妨げられることがしばしばあります。そのため、気象学者に限られ、水文学者や農業専門家などの他の専門家は装備が不十分となります。これは、私の組織(ANA)で観察された課題であり、水文学者やエンジニアは特定の流域の降雨データにアクセスするのに苦労することがよくあります。
この課題に対処するため、この記事ではmerge-downloaderパッケージを使用してこれらのデータを効率的にダウンロードおよび操作する方法について読者をガイドすることを目指しています。これにより、より広範な学際的な利用と洞察が可能になります。
インストール
merge-downloaderはINPEからデータにアクセスするための非公式ライブラリであり、ソースコードは次の場所で利用可能です:https://github.com/cordmaur/merge-downloader。
地理空間アプリケーションに必要なPythonライブラリのインストールは、時には困難な場合がありますので、dockerを使用することを強くお勧めします。私はすでに以前のTDSでこのトピックを取り上げています:
- Pythonを使用した空間解析のための最小限のDockerイメージの設定
- ジオスペーシャル開発にDevcontainersを使用する理由
Docker Hubでdockerイメージがすでに利用可能であり、次のコマンドをシェルプロンプトで実行することでインストールが行えます。
> docker pull cordmaur/merge-downloader:v1> docker run -it -p 8888:8888 merge-downloader:v1 bashコンテナ内に入った後、パッケージをインストールし、jupyterを起動することができます。jupyterは、http://127.0.0.1:8888でウェブブラウザからアクセスできます。
root@89fd8c332f98:/# pip install merge-downloaderroot@89fd8c332f98:/# jupyter notebook --ip=0.0.0.0 --allow-root --no-browser別のオプションとして、さらに直接的な方法はGoogle Colabにmerge-downloaderをインストールすることです。
# コードセルから%pip install merge-downloaderアセットのダウンロード
まず最初に、INPEから単純に降水量と気候資産をダウンロードする方法を説明します。merge-downloaderを使用してダウンロードできる利用可能なアセットのリストは、次のコマンドで取得できます:
from mergedownloader.inpeparser import INPETypesINPETypes.types()result: DAILY_RAIN, MONTHLY_ACCUM_YEARLY, DAILY_AVERAGE, MONTHLY_ACCUM, MONTHLY_ACCUM_MANUAL, YEARLY_ACCUM, HOURLY_WRF, DAILY_WRF各タイプの意味は、GitHubのドキュメントで利用でき、次の表に要約されています:

任意のアセットをダウンロードするには、最初にINPEのFTPサーバーを指すダウンロードインスタンスを作成し、ファイルをダウンロードするためのローカルフォルダーを設定する必要があります。
from mergedownloader.downloader import Downloaderfrom mergedownloader.inpeparser import INPETypes, INPEParsers# ファイルを保存するための一時フォルダを作成します!mkdir ./tmpdownloader = Downloader( server=INPEParsers.FTPurl, parsers=INPEParsers.parsers, local_folder='./tmp')ダウンローダーインスタンスが作成されたら、特定の日の降雨をダウンロードしましょう。get_fileコマンドを使用して、次のようにします:
import xarray as xrfile = downloader.get_file(date='20230601', datatype=INPETypes.DAILY_RAIN)fileresult:PosixPath('tmp/DAILY_RAIN/MERGE_CPTEC_20230601.grib2')ファイルはxarrayライブラリで開くことができます:
rain = xr.load_dataset(file)rain['prec'].plot(vmax=150)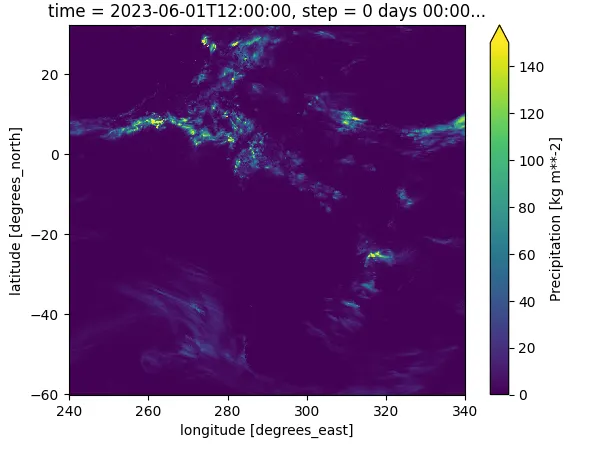
複数のアセットの開く
前の例では、経度が240から340度東に範囲が広がっています。これは通常ではありません。通常、経度はグリニッジの右側に正の数、左側に負の数を使用します。この修正や正しいCRSの定義など、その他の細かい修正は、Downloaderインスタンスを使用してアセットを開くときに自動的に行われます。これは、get_fileの代わりにopen_fileを使用することで実現できます。例として、2023年の最初の4ヶ月に発生した降雨を表す複数のファイルを開きます。さらに、南アメリカの国を空間参照としてプロットします。
# 国のデータセットを開くcountries = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))south_america = countries.query("continent == 'South America'")# ダウンロードする月を選択dates = ['2023-01', '2023-02', '2023-03', '2023-04']monthly_rains = [downloader.open_file(date, datatype=INPETypes.MONTHLY_ACCUM_YEARLY) for date in dates]# 月間降水量のある図を作成fig, axs = plt.subplots(2, 2, figsize=(12, 11))for i, rain in enumerate(monthly_rains): ax = axs.reshape(-1)[i] rain.plot(ax=ax, vmax=1200) south_america.plot(ax=ax, facecolor='none', edgecolor='white')
データキューブの作成
さて、2023年6月の前半に特定の地域(例:アマゾン生物圏)で発生した累積降水量を評価する必要があるとしましょう。これらのシナリオでは、個々のファイルを開き、エリアをクリッピングし、スタックし、などする代わりに、データキューブを作成し、それに直接操作する方がはるかに簡単です。キューブは、複数のラスタがtime次元と並んで積まれたものです。
では、まずキューブを作成しましょう。指定された日付範囲に対してDownloaderクラスが自動的にキューブを作成できます。
# 6月の前半のキューブを作成しますcube = downloader.create_cube( start_date='20230601', end_date='20230615', datatype=INPETypes.DAILY_RAIN)cube
次に、2つの操作を行う必要があります。まず、データを目的のエリアに制限するためのクリッピング、そして目的の日数にわたる降水量を累積するための合計です。最初のステップでは、キューブをアマゾン生物圏の範囲に切り取ります。これはGISUtil.cut_cube_by_geoms()メソッドを使用して行うことができます。次に、time軸に沿って合計を行い、単一の2次元レイヤーになるようにします。ステップごとに見てみましょう。
from mergedownloader.utils import GISUtil# アマゾンのジオメトリを開くamazon = gpd.read_file('https://raw.githubusercontent.com/cordmaur/Fastai2-VoAGI/master/Data/amazon.geojson')# ジオメトリでキューブを切り取るamazon_cube = GISUtil.cut_cube_by_geoms( cube=cube, geometries = amazon.geometry)# 時間軸に沿って降水量を累積するamazon_rain = amazon_cube.sum(dim='time', skipna=False)# 図をプロットfig, ax = plt.subplots(figsize=(8, 5))amazon_rain.plot(ax=ax)south_america.plot(ax=ax, facecolor='none', edgecolor='firebrick')
時系列の作成
特定の地域の時間系列を作成することは、特に降雨や歴史的な気候データを考慮する場合に有益な情報を提供することができます。例えば、2015年のエルニーニョ現象中のアマゾンの月間降雨量をプロットし、各月における地域の長期平均降水量と比較することができます。
まず、2つのキューブを作成します。1つは2015年1月から12月までの月間降水量で、もう1つは長期平均です。INPEが提供する長期平均は2000年から2022年までのデータ(23年分)から計算されており、この場合、参照として任意の年を使用できます。
次のコードでは、各ピクセルの値を集計し、time次元のみを残すために使用されるreducer=xr.DataArray.meanメソッドを使用していることに注意してください。
# キューブを作成しますcube_2015 = downloader.create_cube( start_date='2015-01', end_date='2015-12', datatype=INPETypes.MONTHLY_ACCUM_YEARLY)cube_lta = downloader.create_cube( start_date='2015-01', end_date='2015-12', datatype=INPETypes.MONTHLY_ACCUM)# シリーズを作成しますseries_2015 = downloader.get_time_series( cube=cube_2015, shp=amazon, reducer=xr.DataArray.mean)series_lta = downloader.get_time_series( cube=cube_lta, shp=amazon, reducer=xr.DataArray.mean)# 年と月のみを持つ文字列インデックスを作成しますseries_lta.index = series_2015.index = series_2015.index.astype('str').str[:7]# グラフをプロットfig, ax = plt.subplots(figsize=(12,6))series_lta.plot(ax=ax, kind='line', color='orange', marker='x')series_2015.plot(ax=ax, kind='bar')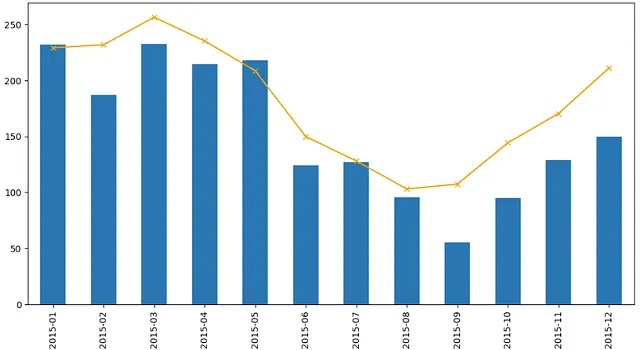
結論
merge-downloader パッケージとINPEの降水および気候データは、環境分析アプリケーションにおける効果的なリソースを提供します。このパッケージは、geopandasやxarrayなどの確立されたライブラリとの互換性もあり、その適用範囲をさらに拡大しています。
さまざまなケース例を通じて示されるパッケージの機能は、降水データのダウンロードとプロットなどの簡単なタスクから、データキューブの生成、空間クリッピングの実装、時系列分析の実行などの高度な操作まで広がっています。ユーザーはこれらのツールを特定の要件に応じて適用することができ、環境変化の追跡、気候イベントの監視、総合的な地域研究などのタスクを容易にすることができます。図2は、merge-downloader と他のPythonジオスペーシャルツールを使用したレポートの例を示しています。
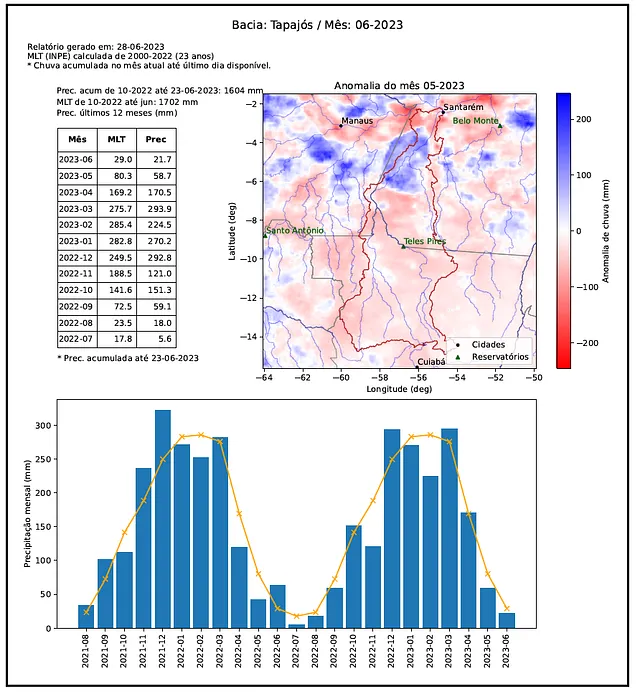
提示された方法論により、降水データの評価と気候参照との比較が任意の空間的に定義された領域で可能となり、さまざまなドメインに利用できます。
最新情報を受け取る
この記事がお気に入りでしたら、VoAGIのメンバーになり、この記事のような数千の記事を閲覧できるようになります。
私の紹介リンクでVoAGIに参加する – Maurício Cordeiro
VoAGIのメンバーとして、あなたの会費の一部はあなたが読む作家に支払われ、あなたはすべてのストーリーに完全アクセスできます…
cordmaur.medium.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
