動的言語理解:パラメトリックおよび半パラメトリックモデルでの新しい知識への適応
動的言語理解:新しい知識への適応
最近の言語モデル(LM)の多くの成功は、「静的なパラダイム」内で達成されています。ここでは、データの時間的側面を考慮せずに作成されたベンチマークのパフォーマンスを向上させることに焦点を当てています。例えば、モデルがトレーニング中に学習できるイベントに関する質問に答えること、またはトレーニングデータと同じ期間からサブサンプリングされたテキストの評価などです。しかし、言語と知識は動的で絶えず進化しています。したがって、次の性能向上のために質問応答モデルをより現実的に評価するためには、新しい見たことのないデータに遭遇したときに柔軟性と堅牢性を確保することが不可欠です。
2021年には、時間的一般化を評価するためのMind the Gap: Assessing Temporal Generalization in Neural Language ModelsおよびWMTおよびarXivの動的言語モデリングベンチマークを公開しました。本稿では、現行の最先端の大規模LMが時間的一般化に直面する問題を強調し、知識を重視したトークンが大きなパフォーマンスの低下を引き起こすことを発見しました。
今日、このトピックのさらなる研究を進めるために2つの論文と新しいベンチマークを公開します。『StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models』では、新しく提案されたベンチマークであるStreamingQA上の質問応答の下流タスクを研究し、パラメトリックおよびリトリバル増強型の半パラメトリックな質問応答モデルが新しい情報に適応する方法を理解したいと考えています。『Internet-augmented language models through few-shot prompting for open-domain question answering』では、few-shot提示を使用して大規模言語モデルとGoogle検索を組み合わせることで、モデルの事実性を向上させ、さまざまな質問に回答するための最新の情報にアクセスすることのパワーを探求しています。
StreamingQA:時間的一般化に適応するためのベンチマーク
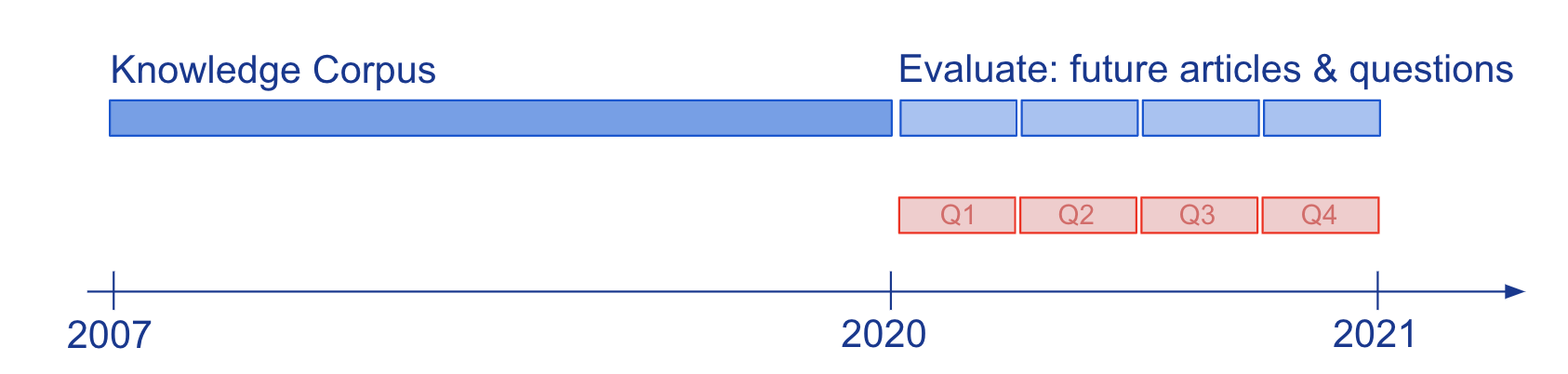
質問応答(QA)を通じてモデルの知識と言語理解を評価する際、Wikipediaなどの静的な知識スナップショットで研究されることが一般的です。我々は、半パラメトリックなQAモデルとその基礎となるパラメトリックなLMが進化する知識にどのように適応するかを研究するため、14年間のタイムスタンプ付きニュース記事から尋ねられる人間によって書かれたおよび自動生成された質問に答えるための新しい大規模なベンチマークであるStreamingQAを構築しました(図2参照)。パラメトリックモデルは完全な再トレーニングなしで更新することができ、カタストロフィックな忘却を回避することができます。半パラメトリックモデルでは、検索空間に新しい記事を追加することで迅速な適応が可能ですが、時代遅れの基礎となるLMを持つモデルは再トレーニングされたLMを持つモデルに比べて性能が低下します。

インターネットを利用した言語モデル:few-shot提示を用いたオープンドメイン質問応答
大規模言語モデルが提供するユニークなfew-shot機能を活用して、事実的かつ最新の情報に基づく課題に対処するためのいくつかの課題を克服することを目指しています。外部から取得した証拠に基づいて意思決定する半パラメトリックなLMに触発されて、few-shot提示を使用して、Google検索を介してウェブから返された情報にLMを条件付けて学習します。私たちのアプローチは、ファインチューニングや追加のパラメータの学習を必要としないため、ほぼすべての言語モデルに適用することができます。そして実際に、ウェブに基づくLMは、オープンドメインの質問応答において、同等またはより大きなモデルサイズのクローズドブックモデルの性能を上回ることがわかります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





