人工エージェントにおける遵守と執行行動の学習を向上させる偽の規範性
偽の規範性は、人工エージェントの遵守と執行行動の学習を向上させる
私たちの最近の論文では、マルチエージェントの深層強化学習が社会的な相互作用のモデルとして、社会的規範の形成などの複雑な社会的相互作用を探求しています。この新しいモデルのクラスは、より豊かで詳細な世界のシミュレーションを作成するための道を提供する可能性があります。
人間は超社会的な種です。他の哺乳類に比べて、私たちは協力からより多くの利益を得る一方、それにもっと依存し、より大きな協力の課題に直面しています。今日、人類は資源を巡る紛争を防止し、誰もが清潔な空気と飲料水にアクセスできるようにし、極度の貧困を撲滅し、気候変動と戦うという数多くの協力課題に直面しています。私たちが直面する多くの協力問題は、社会生態系と呼ばれる社会的および生物物理学的相互作用の複雑な結びつきを含むため、解決が困難です。しかし、人間は私たちが直面する協力の課題を集合的に克服するために学ぶことができます。私たちは、環境や他の人々との相互作用を組織する規範や制度を含む、進化し続ける文化によってこれを達成しています。
ただし、規範や制度は時に協力の課題を解決できないこともあります。例えば、個々の人々が森林や漁業などの資源を過剰に利用し、それらが崩壊する原因となることがあります。このような場合、政策立案者は法律を制定して制度のルールを変更したり、規範を変えるための他の介入策を開発したりすることで、ポジティブな変化をもたらそうとします。しかし、政策の介入が必ずしも意図通りに機能しないこともあります。これは、実世界の社会生態系が、候補政策の影響を予測しようとするために通常使用するモデルよりもはるかに複雑であるためです。
ゲーム理論に基づいたモデルは、文化進化の研究に広く適用されています。これらのモデルのほとんどでは、エージェント間の主要な相互作用は「ペイオフ行列」で表現されます。2つの参加者と2つのアクションAとBのゲームでは、ペイオフ行列は次の4つの可能な結果の価値を定義します:(1)私たちは両方Aを選びます、(2)私たちは両方Bを選びます、(3)私はAを選び、あなたはBを選びます、(4)私はBを選び、あなたはAを選びます。最も有名な例は「囚人のジレンマ」であり、アクションは「協力」と「裏切り」と解釈されます。自己利益に基づいて行動する合理的なエージェントは、相互協力の方が良い結果が得られるにもかかわらず、囚人のジレンマでは必ず裏切ります。
ゲーム理論のモデルは非常に広く適用されています。さまざまな分野の研究者は、経済や人間の文化の進化など、さまざまな現象を研究するためにこれらを使用しています。しかし、ゲーム理論は中立的なツールではなく、深く主観的なモデリング言語です。すべてが最終的にペイオフ行列(または同等の表現)で結果を表すことが厳密に要求されます。これは、モデラーが個々の行動の効果がどのように組み合わさってインセンティブを生成するかを知っているか、または仮定することを必要とします。これは時に適切な場合もあり、ゲーム理論的アプローチは、寡占企業の行動や冷戦時代の国際関係のモデリングなど、多くの傑出した成功を収めてきました。ただし、ゲーム理論のモデリング言語としての主な弱点は、モデラーが個々の選択がペイオフを生成するためにどのように組み合わさるかを完全に理解していない場合に露呈します。残念ながら、これは社会生態系の場合にはしばしば当てはまります。なぜなら、社会的および生態学的な要素が複雑な方法で相互作用するため、私たちはそれを完全に理解していないからです。
ここで紹介する作業は、社会生態系の研究においてゲーム理論とは異なる代替のモデリングフレームワークを確立しようとする研究プログラムの一例です。私たちのアプローチは、形式的にはエージェントベースのモデリングの一種と見なされるかもしれません。ただし、その特徴は、人工知能からのアルゴリズム的な要素、特にマルチエージェントの深層強化学習の組み込みです。
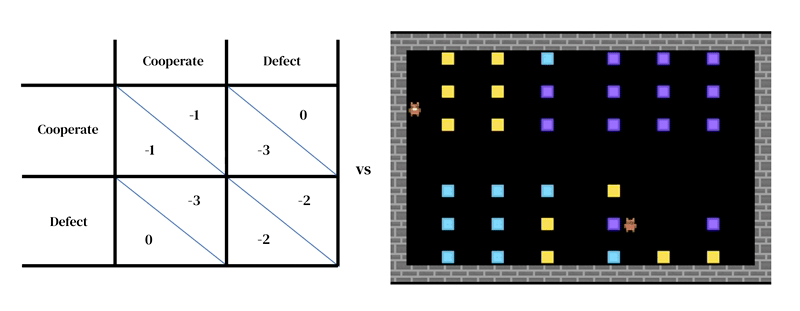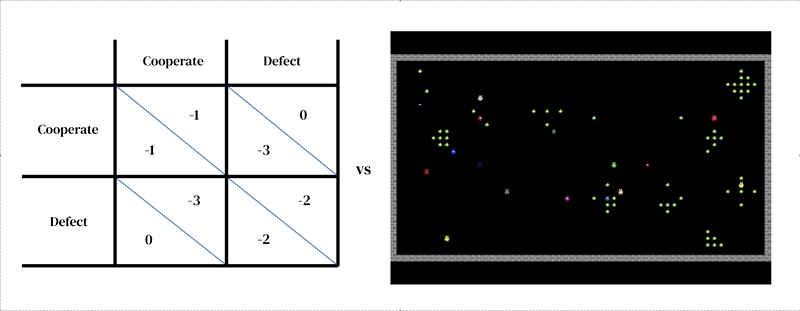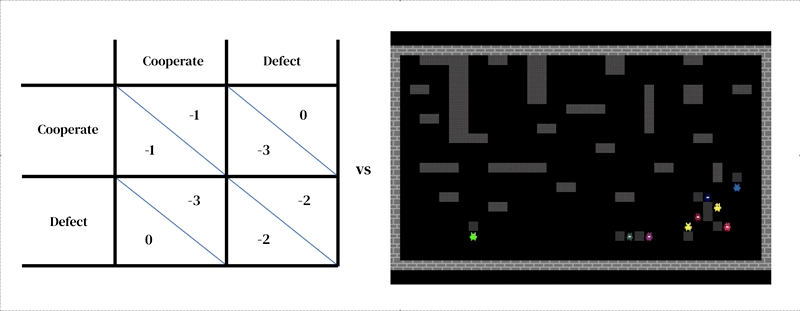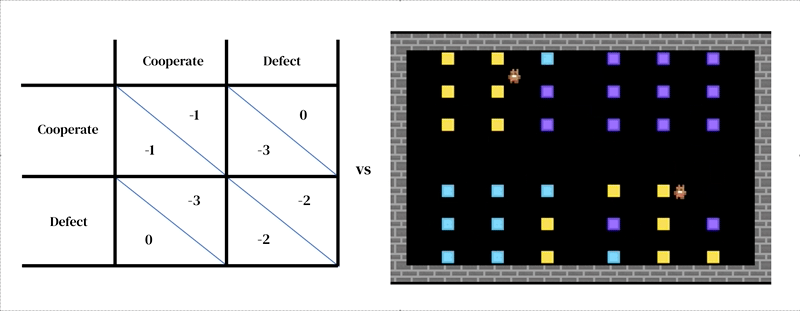
このアプローチの核心的なアイデアは、すべてのモデルが2つの相互作用する部分から成るということです:(1)環境の豊かな動的モデル、および(2)個別の意思決定のモデル。
最初の部分は、研究者が設計したシミュレーターという形で表現されます:現在の環境の状態とエージェントの行動を受け取り、次の環境の状態とすべてのエージェントの観測と即時の報酬を出力します。個別の意思決定のモデルも環境の状態に依存します。それは過去の経験から学ぶエージェントであり、試行錯誤の形を取ります。エージェントは観測を受け取り、行動を出力することで環境と相互作用します。各エージェントは、観測から行動へのマッピングである行動ポリシーに従ってアクションを選択します。エージェントは、報酬を増やすために通常はより多くの報酬を得るために、任意の次元でポリシーを改善することで学習します。ポリシーはニューラルネットワークに格納されます。エージェントは、自分自身の経験から世界がどのように機能し、より多くの報酬を得るために何ができるかを徐々に変換するために、ネットワークの重みを調整することで学習します。いくつかの学習エージェントは互いに同じ環境に存在することができます。この場合、エージェントはお互いに影響を与えるため、相互依存関係を持ちます。
他のエージェントベースのモデリング手法と同様に、マルチエージェント深層強化学習は、ゲーム理論では扱いにくい分析レベルをまたがるモデルを簡単に指定することができます。例えば、行動はゲーム理論の高レベルの戦略的な意思決定(例:「協力する」)よりも、低レベルのモータープリミティブ(例:「前に進む」、「右に曲がる」)に近い場合があります。これは、エージェントが戦略的な選択肢を実装する方法を効果的に学ぶための状況を捉えるために必要な重要な特徴です。例えば、ある研究では、エージェントが交互に川を掃除することで協力を学びました。この解決策は、エージェント同士の行動をどのように構造化するかに関して、空間的および時間的な次元を持つ環境だからこそ可能でした。興味深いことに、環境は多くの異なる解決策(例:領土性)を許容していましたが、エージェントは人間のプレイヤーと同じように交互に行動する解決策に収束しました。
最新の研究では、このタイプのモデルを文化進化の研究における未解決の問題に適用しました。それは、即時の物質的な結果を伴わない見かけ上の無意味な社会的規範の存在を説明する方法です。例えば、一部の社会では男性はスカートではなくズボンを穿くことが期待されています。多くの社会では、礼儀正しい場では使用すべきでない言葉や手のジェスチャーがあります。また、ほとんどの社会では、髪型や頭に被るものについての規則が存在します。これらの社会的規範を「愚かなルール」と呼びます。重要なのは、私たちのフレームワークでは、社会的規範の施行と遵守の両方を学ぶ必要があるということです。”愚かなルール”を含む社会環境があることで、エージェントは一般的な規範の施行についてより多くの学習の機会を持つことができます。この追加の実践により、彼らは重要な規則をより効果的に施行することができます。全体的には、”愚かなルール”は人口にとって有益な結果となる可能性があります。この結果は、私たちのシミュレーションが学習に焦点を当てているためにのみ可能です。規則の施行と遵守は、訓練が必要な複雑なスキルです。
「愚かなルール」に関するこの結果が興奮している理由の一部は、マルチエージェント深層強化学習が文化進化のモデリングにおいて有用であることを示しているからです。文化は社会生態系の政策介入の成功または失敗に寄与します。例えば、リサイクルに関する社会的規範を強化することは、一部の環境問題の解決策の一部です。この軌道を追うと、より豊かなシミュレーションが社会生態系の介入の設計についてより深い理解をもたらす可能性があります。シミュレーションが十分に現実的になれば、生産性と公正さを促進する税制を設計するといった介入の影響をテストすることさえ可能になるかもしれません。
このアプローチは、研究者に自分たちの興味を持つ現象の詳細なモデルを指定するためのツールを提供します。もちろん、すべての研究方法論と同様に、この方法には長所と短所があることを予想されます。私たちは、このスタイルのモデリングが将来どのような場面で有益に適用できるのかについて、さらに多くのことを見つけ出したいと考えています。モデリングには万能薬はありませんが、学習を含む社会現象のモデルを構築する際に、マルチエージェント深層強化学習に注目する説得力のある理由があると思います。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles