Matplotlibを使用してインフォグラフィックを作成する
作成するインフォグラフィックにはMatplotlibを使用します
ノルウェー大陸棚のゼクシュタイン層における地質岩石変動
魅力的で引き込まれるデータの視覚化は、データを扱いデータサイエンティストであることにとって不可欠です。それにより、生データの値を確認することなく、読者にデータを理解しやすい簡潔な形式で情報を提供することができます。さらに、チャートやグラフを使用して、データに関する1つ以上の質問に答える、魅力的で興味深いストーリーを伝えることもできます。
Pythonの世界では、データサイエンティストが視覚化を作成するための多くのライブラリがあり、データサイエンスの道を歩み始めると最初に出会うものの1つがmatplotlibです。しかし、matplotlibで少し作業した後、基本的なmatplotlibプロットを退屈で基本的だと見なし、よりモダンな他のライブラリに移る人も多いです。
少しの時間と努力、コード、そしてmatplotlibの機能に理解を持つことで、基本的で退屈なプロットをより魅力的で視覚的に魅力的なものに変えることができます。
私の過去数記事では、さまざまなスタイリング方法で個々のプロットを変換する方法に焦点を当ててきました。matplotlibのデータ視覚化を改善することに興味がある場合は、以下のいくつかの以前の記事をご覧いただけます。
- データ視覚化のアップグレード:Matplotlibチャートを向上させるための4つのPythonライブラリ
- Matplotlibフィギュアをサイバーパンク風にする
- Matplotlibを使用して極座標棒グラフを向上させる
- Matplotlibを使用して魅力的なレーダープロットを作成する
これらの記事は主に単一のプロットとそのスタイリングに焦点を当てています。この記事では、matplotlibを使用してインフォグラフィックを作成する方法について見ていきます。
インフォグラフィックは、複雑なデータセットを情報豊かで魅力的な視覚的なナラティブに変換するために使用されます。インフォグラフィックはデータを視覚的に表現し、チャート、テーブル、最小限のテキストから構成されます。これらを組み合わせることで、トピックや質問の理解しやすい概要を提供することができます。
私の以前の記事で極座標棒グラフについて共有した後、Russell Forbesからのツイートでmatplotlibでインフォグラフィックを作成することが可能であることが示されました。
それを受けて、私は自分自身に考えました。なぜmatplotlibでインフォグラフィックを作成してみないのでしょうか。
そして、実際に作成しました。
次のインフォグラフィックはその結果であり、この記事で再現していきます。
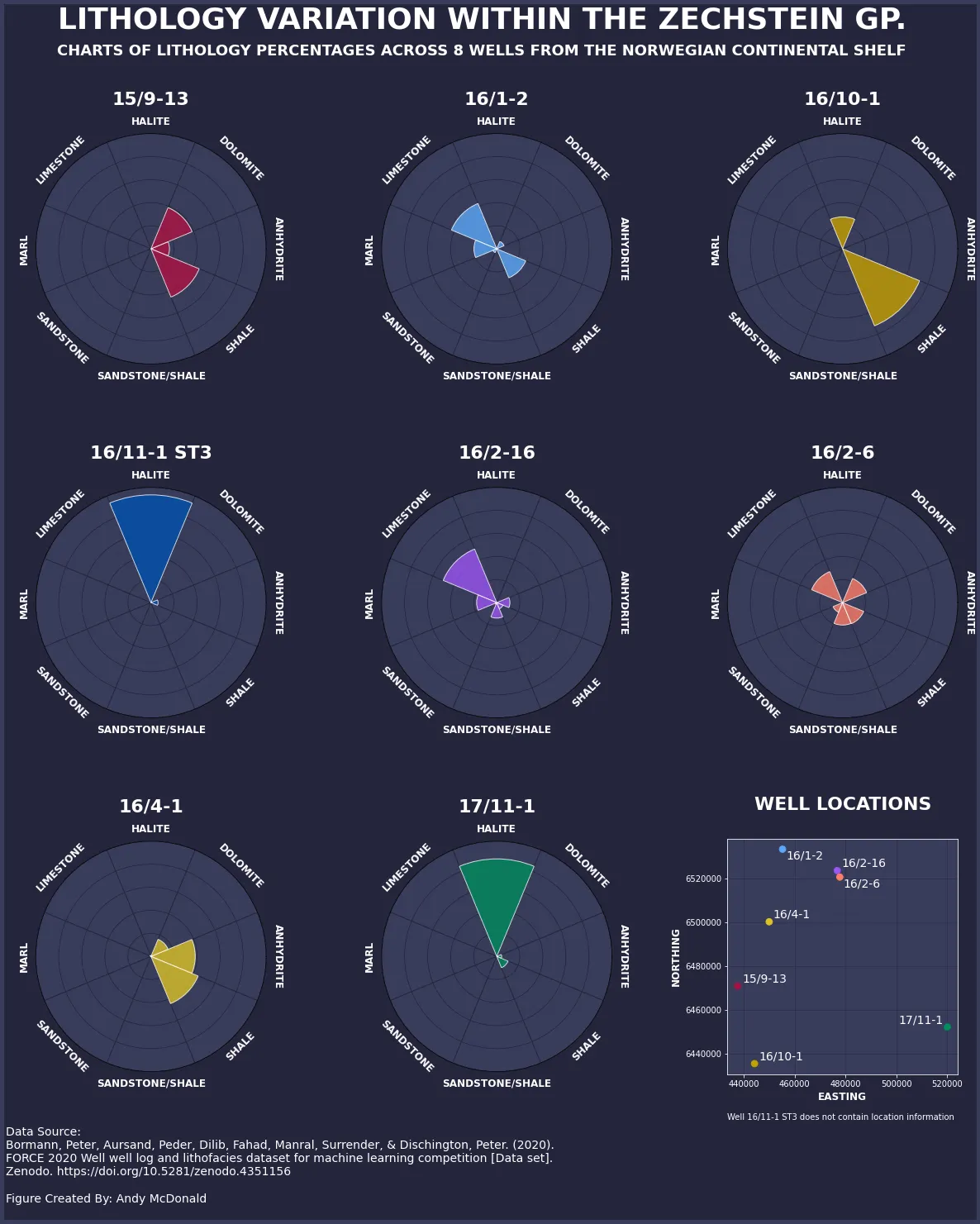
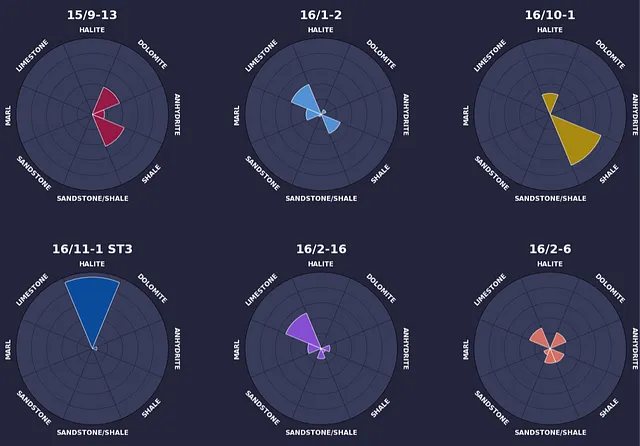
この記事で作成するインフォグラフィックは、ウェブ上で使用するか、プレゼンテーションに含めることが適しているかもしれません。ただし、報告書に含める場合やより形式的な場で表示する場合は、代替のカラーパレットとよりプロフェッショナルな雰囲気を考慮する必要があります。
インフォグラフィックの目標
データの視覚化に手を付ける前に、インフォグラフィックを作成する目的を理解する必要があります。これがなければ、使用したいプロットや伝えたいストーリーを絞り込むことは難しいでしょう。
この例では、ノルウェー大陸棚から得られたウェルログに由来する岩石学的測定値のデータセットを使用します。このデータセットから、次の質問に特に焦点を当てます:
データセット内のゼクシュタイン層の岩石変動は何ですか?
これが私たちの出発点となります。
私たちは岩石学のデータとゼクシュタイン層内のデータを探していることを知っています。
ライブラリのインポートとデータの読み込み
まず、いくつかの重要なライブラリをインポートする必要があります。
これには、データの読み込みと保存に使用するpandas、極座標でラベルとデータをプロットするための数学的計算を実行するためのnumpy、プロットを作成するためのmatplotlib、およびラベルが散布図上で重ならないようにするためのadjustTextが含まれます。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from adjustText import adjust_textライブラリがインポートされた後、次にデータセットをロードする必要があります。このデータセットのソースの詳細は、この記事の末尾に含まれています。
最初にロードするデータセットは、私の前の記事で作成したゼクシュタイン層の岩石組成です。
このデータをpandasのread_csv()関数を使用してロードできます。
df = pd.read_csv('Data/LithologySummary.csv', index_col='WELL')データフレームを表示すると、各井戸内で解釈されたゼクシュタイン層内の岩石組成に関する次の情報が得られます。
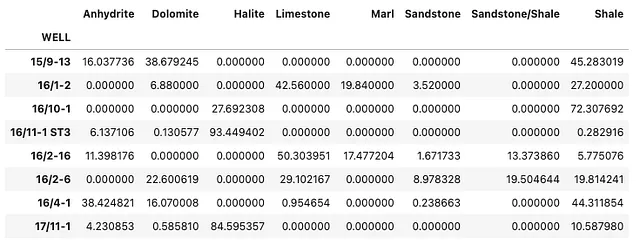
読者がデータをより理解しやすくするために、掘削された井戸がゼクシュタイン層と交差した場所に関する情報があると良いでしょう。
これはpd.read_csv()を使用して同じ方法でデータをロードできます。ただし、今回はインデックスを設定する必要はありません。
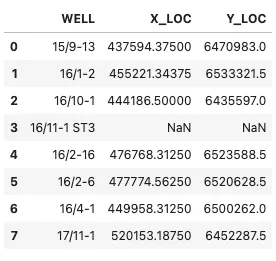
zechstein_well_intersections = pd.read_csv('Data/Zechstein_WellIntersection.csv')このデータフレームを表示すると、井戸の名前とゼクシュタイン層に侵入した場所のX座標とY座標が含まれる次の表が表示されます。
Matplotlibを使用したインフォグラフィックの準備と作成
図を作成する前に、データに関する重要な情報を含むいくつかの変数を作成する必要があります。これにより、プロットを作成する際に作業が容易になります。
まず、可能な岩石のリストを取得します。これは、サマリーデータフレームの列名をリストに変換することで行われます。
lith_names = list(df.columns)このリストを表示すると、次の岩石が表示されます。

次に、インフォグラフィック内の個々のプロットの設定方法を決定する必要があります。
このデータセットでは、8つの井戸があり、これらを使用して8つの放射状の棒グラフを生成します。
また、井戸の位置も同じ図に表示したいです。つまり、9つのサブプロットが必要です。
図を細分化する方法の一つは、3つの列と3つの行を持つことです。これにより、num_colsという変数を作成し、列の数を表します。
num_rowsという変数を一般化して、他のデータセットでも再利用できるようにします。この例では、データフレームの行数(井戸数)を取得し、欲しい列数で割って数を計算します。これにより、np.ceilを使用してこの数を切り上げて、図上のすべてのプロットを作成します。
# サブプロットグリッドの列数を設定する
num_cols = 3
# ウェル数(データフレームの行数)を取得する
num_wells = len(df)
# サブプロットグリッドに必要な行数を計算する
num_rows = np.ceil(num_wells / num_cols).astype(int)次に宣言する変数のセットは次のとおりです:
indexes: リストを作成し、リスト内のアイテムの総数の範囲内で0からの数値を生成します。この場合、データセットの8つの岩石をカバーするため、0から7までのリストが生成されます。width: チャート内の各バーの幅を計算してリストを作成します。これは、円の円周を岩石の数で割ることによって行われます。angles: 各岩石の角度を含むリストを作成します。colours: 各井戸を表すために使用する16進数の色のリストです。label_loc: 岩石タイプを表示するために0から2 * piの間の均等に間隔を開けた値のリストを作成します。
indexes = list(range(0, len(lith_names)))width = 2*np.pi / len(lith_names)angles = [element * width for element in indexes]colours = ["#ae1241", "#5ba8f7", "#c6a000", "#0050ae", "#9b54f3", "#ff7d67", "#dbc227", "#008c5c"]label_loc = np.linspace(start=0, stop=2 * np.pi, num=len(lith_names))Matplotlibでインフォグラフィックを作成する
サブプロットとして放射状の棒グラフを追加する
インフォグラフィックを作成するには、まずfigureオブジェクトを作成する必要があります。これはplt.figure()を呼び出すことで行います。
図をセットアップするために、いくつかのパラメータを渡す必要があります:
figsize:インフォグラフィックのサイズを制御します。行数が異なる場合があるため、行のパラメータを行数の倍数に設定することで、プロットや図が歪まないようにします。linewidth:図の境界の太さを制御します。edgecolor:図の境界の色を設定します。facecolor:図の背景色を設定します。
# 図を作成するfig = plt.figure(figsize=(20, num_rows * 7), linewidth=10, edgecolor='#393d5c', facecolor='#25253c')次に、グリッドレイアウトを定義する必要があります。これにはいくつかの方法がありますが、この例ではGridSpecを使用します。これにより、サブプロットの位置と間隔を指定できます。
# グリッドレイアウトを作成するgrid = plt.GridSpec(num_rows, num_cols, wspace=0.5, hspace=0.5)これで、放射状の棒グラフを追加する準備が整いました。
これを行うには、リソログラフィの概要データフレームの各行をループし、add_subplot()を使用してグリッドに軸を追加する必要があります。放射状の棒グラフをプロットしているため、projectionパラメータをpolarに設定する必要があります。
次に、ax.barを呼び出すことで、プロットにデータを追加できます。この呼び出しでは、以下のものを渡します:
angles:極座標の中での棒の位置を提供し、リソログラフィのラベルの位置も決定するheight:現在の行のパーセンテージ値を使用して各棒の高さを設定するwidth:棒の幅を設定するedgecolor:放射状の棒の境界の色を設定するzorder:図のプロット順序を設定するために使用されます。この場合、値を2に設定しているため、図の最上層に配置されます。alpha:棒の透明度を設定するcolor:事前に定義されたカラーリストに基づいて棒の色を設定する
次に、背景の塗りつぶしを追加するために棒を追加するプロセスを繰り返します。テーブルからの値ではなく、100に設定することで、領域全体を塗りつぶします。
次のセットの一部では、ラベル、サブプロットのタイトル、およびグリッドの色を設定します。
リソログラフィのラベルには、正しい角度でラベルを配置するためのforループを作成する必要があります。
このループ内では、ループ内の現在の角度を確認する必要があります。バーの角度がpi未満の場合、回転角から90度を引きます。それ以外の場合、バーが円の下半分にある場合は、回転角に90度を追加します。これにより、プロットの左右の側面にあるラベルが簡単に読めるようになります。
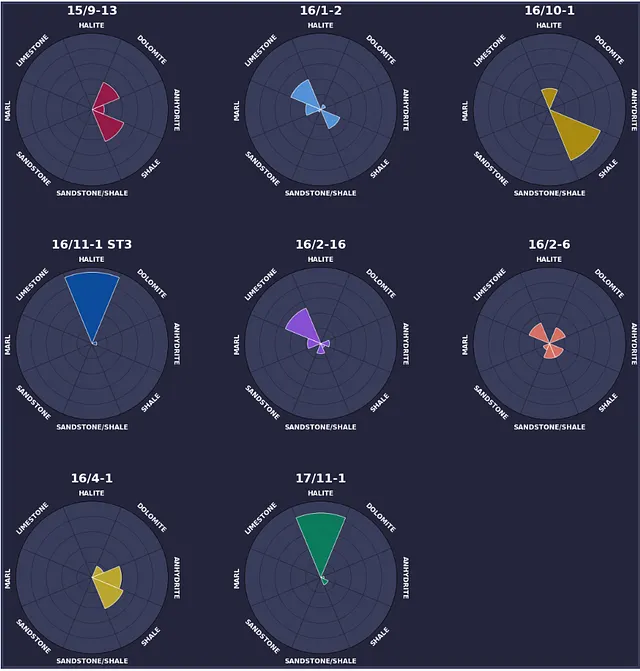
# DataFrame内の各行をループするfor i, (index, row) in enumerate(df.iterrows()): ax = fig.add_subplot(grid[i // num_cols, i % num_cols], projection='polar') bars = ax.bar(x=angles, height=row.values, width=width, edgecolor='white', zorder=2, alpha=0.8, color=colours[i]) bars_bg = ax.bar(x=angles, height=100, width=width, color='#393d5c', edgecolor='#25253c', zorder=1) ax.set_title(index, pad=35, fontsize=22, fontweight='bold', color='white') ax.set_ylim(0, 100) ax.set_yticklabels([]) ax.set_xticks([]) ax.grid(color='#25253c') for angle, height, lith_name in zip(angles, row.values, lith_names): rotation_angle = np.degrees(angle) if angle < np.pi: rotation_angle -= 90 elif angle == np.pi: rotation_angle -= 90 else: rotation_angle += 90 ax.text(angle, 110, lith_name.upper(), ha='center', va='center', rotation=rotation_angle, rotation_mode='anchor', fontsize=12, fontweight='bold', color='white')この時点でコードを実行すると、以下の画像が返されます。この画像には、ノルウェー大陸棚からの8つの井戸の岩石割合を表示する径方向バーチャートが含まれています。
散布図をサブプロットとして追加
上記の通り、図の右下には隙間があります。この部分に井戸の位置を示す散布図を配置します。
これを行うために、forループの外部に新しいサブプロットを追加できます。このプロットを図の最後にしたいので、num_rowsとnum_colsから1を引く必要があります。
次に、zechstein_well_intersectionsデータフレームからXおよびYの位置を引数としてax.scatter()を呼び出して散布図を軸に追加します。
コードの残りの部分では、x軸とy軸にラベルを追加し、目盛りの形式を設定し、散布図の枠線(spine)を白色に設定します。
位置情報を持たない井戸が1つあるため、そのことを読者に知らせるために散布図に小さな脚注を追加できます。
最後に、各マーカーが何を表すかを読者が理解できるように、井戸の名前をラベルとして追加する必要があります。これはforループの一部として行い、ラベルをリストに追加します。
# 散布図を最後のサブプロット(サブプロット9)に追加するax = fig.add_subplot(grid[num_rows - 1, num_cols - 1], facecolor='#393d5c')ax.scatter(zechstein_well_intersections['X_LOC'], zechstein_well_intersections['Y_LOC'], c=colours, s=60)ax.grid(alpha=0.5, color='#25253c')ax.set_axisbelow(True)ax.set_ylabel('NORTHING', fontsize=12, fontweight='bold', color='white')ax.set_xlabel('EASTING', fontsize=12, fontweight='bold', color='white')ax.tick_params(axis='both', colors='white')ax.ticklabel_format(style='plain')ax.set_title('井戸の位置', pad=35, fontsize=22, fontweight='bold', color='white')ax.spines['bottom'].set_color('white')ax.spines['top'].set_color('white') ax.spines['right'].set_color('white')ax.spines['left'].set_color('white')ax.text(0.0, -0.2, '井戸16/11-1 ST3には位置情報が含まれていません', ha='left', va='bottom', fontsize=10, color='white', transform=ax.transAxes)labels = []for i, row in zechstein_well_intersections.iterrows(): labels.append(ax.text(row['X_LOC'], row['Y_LOC'], row['WELL'], color='white', fontsize=14))プロットコードを実行すると、以下の図が得られます。これにより、径方向バーチャートで表示される8つの井戸と散布図で表示される位置がすべて表示されるようになります。
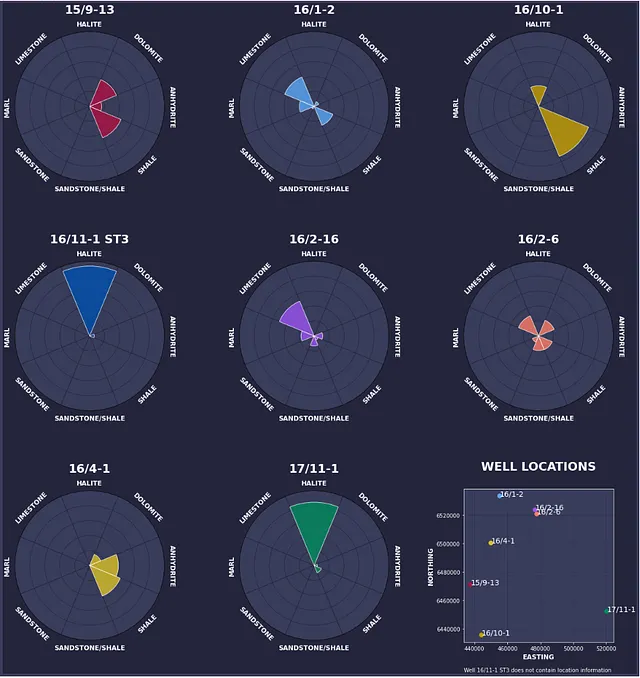
解決する必要のある問題が1つあります。それはラベルの位置です。現在、ラベルはデータポイント、spine、および他のラベルと重なっています。
この問題を解決するために、前にインポートしたadjustTextライブラリを使用できます。このライブラリは、これらの問題を回避するための最適なラベルの位置を計算します。
これを使用するためには、単にadjust_textを呼び出し、前のforループで作成したラベルのリストを渡すだけです。重なりを減らすために、expand_pointsおよびexpand_objectsパラメータを使用することができます。この例では、1.2の値が適切です。
adjust_text(labels, expand_points=(1.2, 1.2), expand_objects=(1.2, 1.2))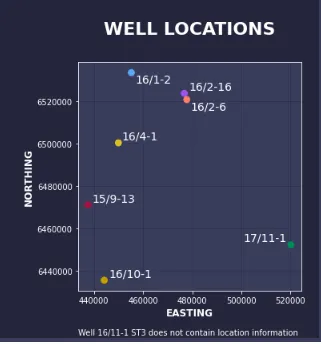
脚注と図タイトルの追加
インフォグラフィックを完成させるために、読者に追加情報を提供する必要があります。
データの出所と作成者を示す脚注を図に追加します。
インフォグラフィックの内容を読者に理解してもらうために、plt.suptitleを使用してタイトル、fig.textを使用してサブタイトルを追加します。これにより、チャートを見るときに読者に即座に何を期待できるかが伝わります。
footnote = """データソース:Bormann, Peter, Aursand, Peder, Dilib, Fahad, Manral, Surrender, & Dischington, Peter. (2020). FORCE 2020 Well well log and lithofacies dataset formachine learning competition [Data set]. Zenodo. https://doi.org/10.5281/zenodo.4351156作成者:Andy McDonald"""plt.suptitle('ゼクシュタインGP内の岩石学的変動', size=36, fontweight='bold', color='white')plot_sub_title = """ノルウェーギア大陸棚の8つのウェルにわたる岩石学割合のグラフ"""fig.text(0.5, 0.95, plot_sub_title, ha='center', va='top', fontsize=18, color='white', fontweight='bold')fig.text(0.1, 0.01, footnote, ha='left', va='bottom', fontsize=14, color='white')plt.show()プロットコードを完了すると、以下のようなmatplotlibのフィギュアが得られます。
全ての半径バーチャートと各ウェルの位置が表示されています。これにより、読者はウェル間の空間的な変動を理解することができ、データ内の変動を説明するのに役立つかもしれません。
たとえば、ウェル15/9-13は地域の西側に位置し、ドロマイト、無水石膏、シェールの混合物で構成されています。一方、ウェル17/11-1は地域の東側に位置し、主にハロイトで構成されています。これは、地域全体で異なる堆積環境に起因する可能性があります。
インフォグラフィックの完全なコード
インフォグラフィックの完全なコードは以下に示されており、各メインセクションにはコメントがついています。
# サブプロットグリッドの列数を設定するnum_cols = 3# ウェルの数を取得する(DataFrameの行数)num_wells = len(df)# サブプロットグリッドの行数を計算するnum_rows = np.ceil(num_wells / num_cols).astype(int)indexes = list(range(0, len(lith_names)))width = 2*np.pi / len(lith_names)angles = [element * width for element in indexes]colours = ["#ae1241", "#5ba8f7", "#c6a000", "#0050ae", "#9b54f3", "#ff7d67", "#dbc227", "#008c5c"]label_loc = np.linspace(start=0, stop=2 * np.pi, num=len(lith_names))# フィギュアを作成するfig = plt.figure(figsize=(20, num_rows * 7), linewidth=10, edgecolor='#393d5c', facecolor='#25253c')# グリッドレイアウトを作成するgrid = plt.GridSpec(num_rows, num_cols, wspace=0.5, hspace=0.5)# 各行のDataFrameをループ処理し、ウェルごとにラジアルバーチャートを作成するfor i, (index, row) in enumerate(df.iterrows()): ax = fig.add_subplot(grid[i // num_cols, i % num_cols], projection='polar') bars = ax.bar(x=angles, height=row.values, width=width, edgecolor='white', zorder=2, alpha=0.8, color=colours[i]) bars_bg = ax.bar(x=angles, height=100, width=width, color='#393d5c', edgecolor='#25253c', zorder=1) # ラベル、目盛り、グリッドを設定する ax.set_title(index, pad=35, fontsize=22, fontweight='bold', color='white') ax.set_ylim(0, 100) ax.set_yticklabels([]) ax.set_xticks([]) ax.grid(color='#25253c') #正しい角度に表示されるようにリソロジー/カテゴリラベルを設定する for angle, height, lith_name in zip(angles, row.values, lith_names): rotation_angle = np.degrees(angle) if angle < np.pi: rotation_angle -= 90 elif angle == np.pi: rotation_angle -= 90 else: rotation_angle += 90 ax.text(angle, 110, lith_name.upper(), ha='center', va='center', rotation=rotation_angle, rotation_mode='anchor', fontsize=12, fontweight='bold', color='white')# 最後のサブプロットに散布図を追加する(サブプロット9)ax = fig.add_subplot(grid[num_rows - 1, num_cols - 1], facecolor='#393d5c')ax.scatter(zechstein_well_intersections['X_LOC'], zechstein_well_intersections['Y_LOC'], c=colours, s=60)ax.grid(alpha=0.5, color='#25253c')ax.set_axisbelow(True)# 散布図のラベルと目盛りを設定するax.set_ylabel('NORTHING', fontsize=12, fontweight='bold', color='white')ax.set_xlabel('EASTING', fontsize=12, fontweight='bold', color='white')ax.tick_params(axis='both', colors='white')ax.ticklabel_format(style='plain')ax.set_title('ウェルの位置', pad=35, fontsize=22, fontweight='bold', color='white')# 散布図の外側の境界線を白色に設定するax.spines['bottom'].set_color('white')ax
概要
インフォグラフィックは、生の数字を気にすることなく、データを簡潔かつ興味深く読者に提示する素晴らしい方法です。また、データについてのストーリーを伝える素晴らしい方法でもあります。
最初は、matplotlibはインフォグラフィックの作成に向いていないと思うかもしれませんが、練習と時間、努力を重ねることで、確かに可能です。
このチュートリアルで使用されるデータセット
XeekとFORCE 2020 (Bormann et al., 2020) によって実施された機械学習競技会の一環として使用されるトレーニングデータセットです。このデータセットはクリエイティブ・コモンズ・ライセンス 表示 4.0 国際に準拠しています。
完全なデータセットは以下のリンクからアクセスできます: https://doi.org/10.5281/zenodo.4351155 .
読んでくれてありがとう。帰る前に、ぜひ私のコンテンツを購読して、記事をメールで受け取ってください。 こちらからできます!
さらに、VoAGIのフル体験を得て、他の数千人の作家と私をサポートするためにメンバーシップに登録してください。月額$5しかかからず、すべての素晴らしいVoAGIの記事にフルアクセスできるだけでなく、執筆でお金を稼ぐチャンスもあります。
もし私のリンクを使って登録する場合、あなたの料金の一部で私を直接サポートしてくれますし、追加費用はかかりません。もしそうしてくれたら、本当にありがとうございます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
-
なぜディープラーニングは常に配列データ上で行われるのか?新しいAI研究は、データからファンクタまでを一つとして扱う「スペースファンクタ」を紹介しています
-
合成データのフィールドガイド
-
新しいAI研究がAttrPromptを紹介します:ゼロショット学習における新しいパラダイムのためのLLM-as-Training-Data-Generator
-
データ駆動型の世界で理解すべき重要な統計的アイデア4つ
-
分析から実際の応用へ:顧客生涯価値の事例
-
Pythonを使用したウェブサイトモニタリングによるリアルタイムインサイトの強化
-
Spotifyで学んだ初級データサイエンティストのための5つの重要なレッスン(パート1)
