人間のフィードバックからの強化学習(RLHF)の説明
人間のフィードバックに基づく強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。
言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。
これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。
RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました:
それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう!
人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します:
- 言語モデル(LM)の事前トレーニング
- データの収集と報酬モデルのトレーニング
- 強化学習によるLMの微調整
まず、言語モデルの事前トレーニングについて見ていきましょう。
言語モデルの事前トレーニング
RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。
この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。
一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。
次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。
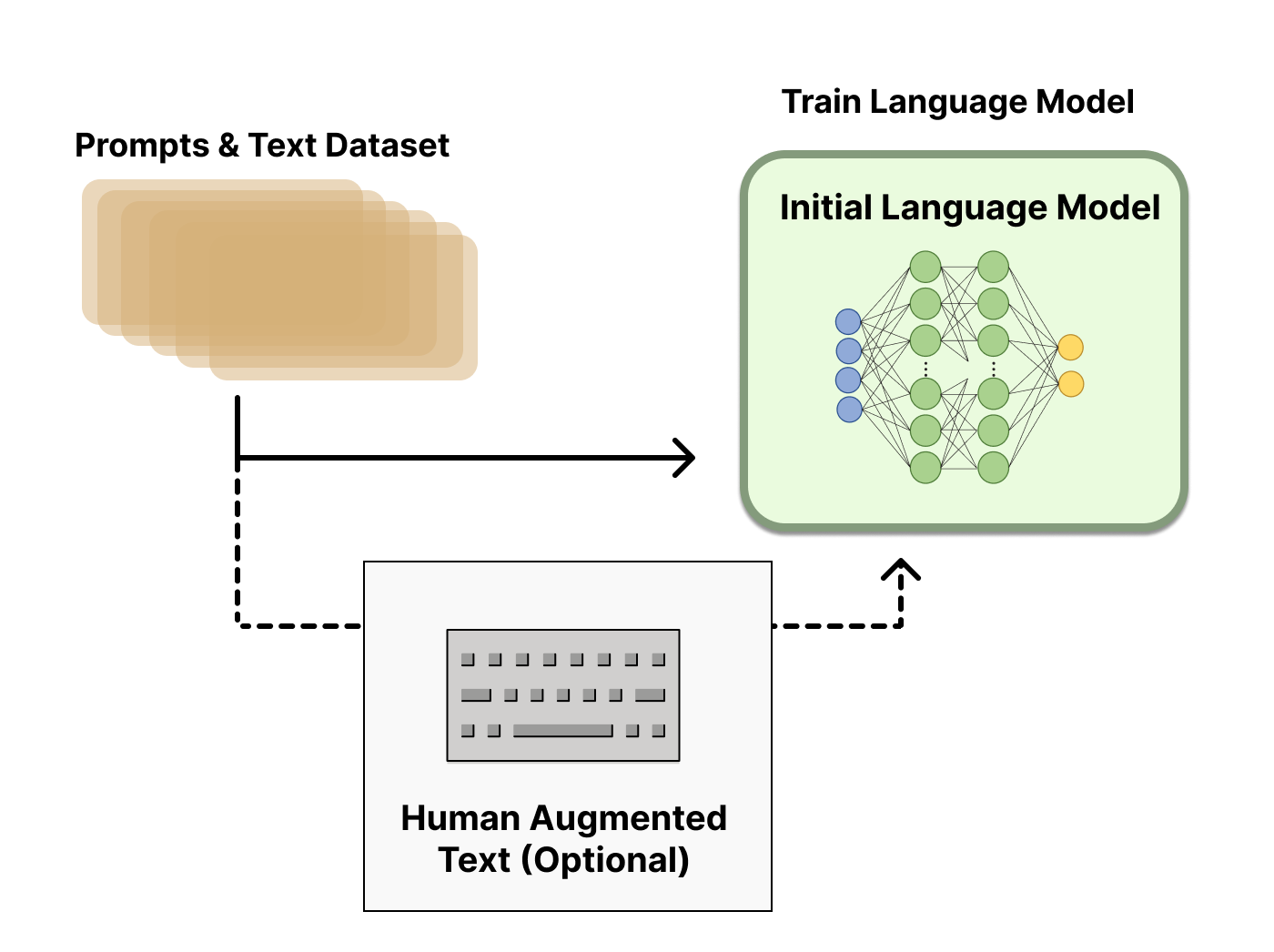
報酬モデルのトレーニング
人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。
報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。
RMのトレーニングデータセットは、あらかじめ定義されたデータセットからプロンプトのセットをサンプリングすることで生成されます(Anthropicのデータは主にAmazon Mechanical Turkのチャットツールで生成され、Hubで利用可能であり、OpenAIはユーザーがGPT APIに提出したプロンプトを使用しました)。プロンプトは初期言語モデルを通じて新しいテキストを生成するために使用されます。
人間の注釈者は、LMから生成されたテキストの出力をランク付けするために使用されます。最初に、人間はテキストごとに直接スカラースコアを適用して報酬モデルを生成するべきだと考えるかもしれませんが、実際にはこれは実践的には難しいです。人間の異なる価値観のために、これらのスコアは校正されておらず、ノイズがあります。その代わりに、ランキングが使用され、複数のモデルの出力を比較して、はるかに優れた正則化されたデータセットが作成されます。
テキストをランキングするための複数の方法があります。成功した方法の1つは、同じプロンプトに基づいて条件付けられた2つの言語モデルから生成されたテキストをユーザーに比較してもらうことです。モデルの出力を頭脳同士の対戦で比較することにより、Eloシステムを使用してモデルと出力のランキングを生成することができます。これらの異なるランキング方法は、トレーニングのためのスカラー報酬信号に正規化されます。
このプロセスの興味深い側面は、これまでに成功したRLHFシステムが、テキスト生成と比較して異なるサイズの報酬言語モデルを使用していることです(例:OpenAI 175B LM、6B報酬モデル、Anthropicは10Bから52BまでのLMと報酬モデルを使用し、DeepMindはLMと報酬に70BのChinchillaモデルを使用しています)。直感的には、これらの好みモデルは、与えられたテキストを理解するためのモデルがテキストを生成するために必要なキャパシティと類似している必要があると考えられます。
RLHFシステムのこの時点では、テキストを生成するために使用できる初期言語モデルと、任意のテキストを受け取り、人間がそれをどれだけ優れていると感じるかにスコアを割り当てる好みモデルがあります。次に、強化学習(RL)を使用して、報酬モデルに対して初期言語モデルを最適化します。
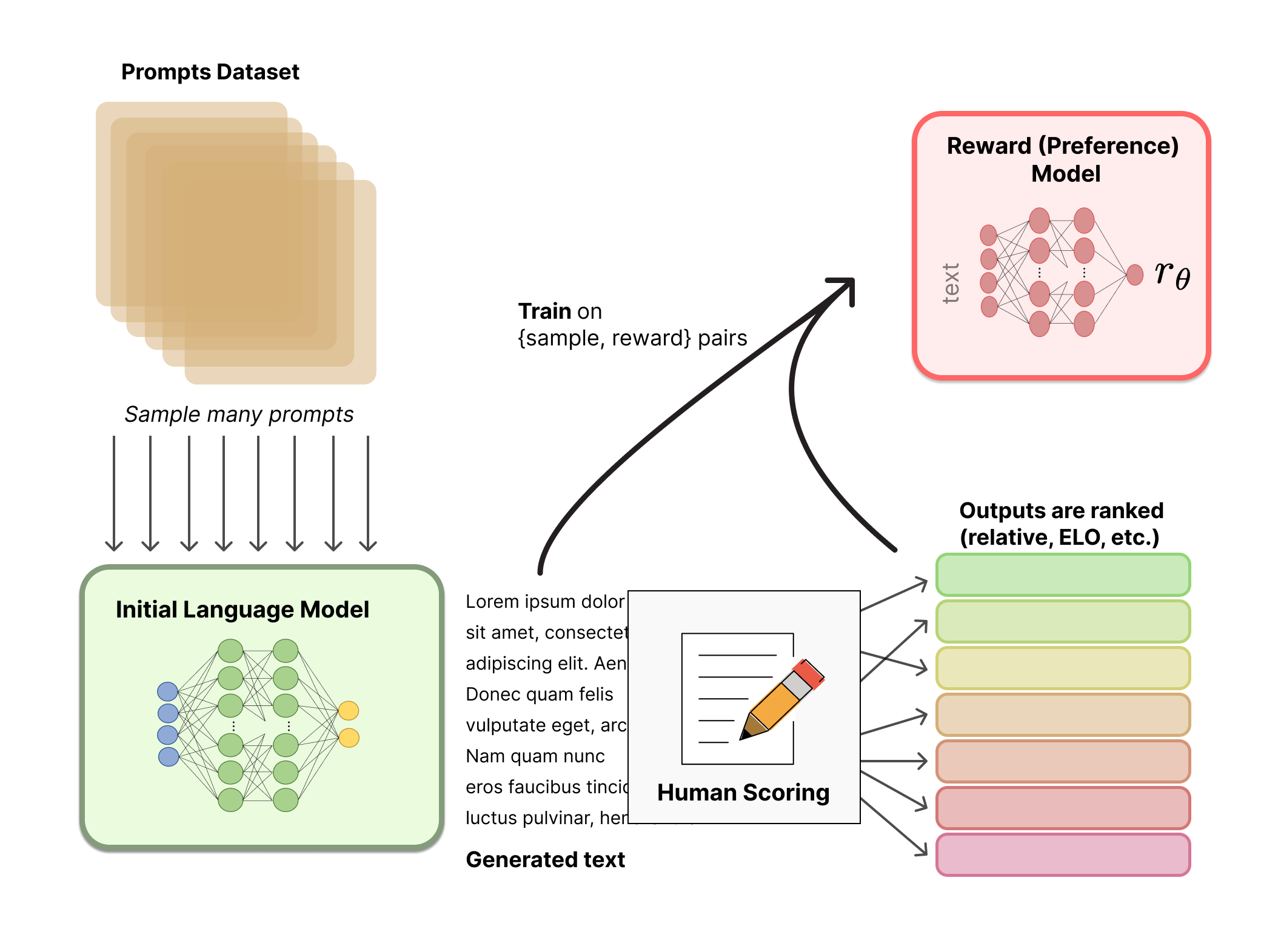
RLでの微調整
強化学習を使用して言語モデルをトレーニングすることは、長い間、技術的およびアルゴリズム的な理由から不可能と考えられていたものでした。しかし、複数の組織が何らかの形で動作するようになったのは、一部またはすべてのパラメータを初期言語モデルのコピーに対して微調整し、ポリシーグラディエントRLアルゴリズムであるProximal Policy Optimization(PPO)を使用することです。LMのパラメータは凍結されます。なぜなら、10Bまたは100B以上のパラメータモデル全体を微調整することは、コストが高すぎるからです(詳細については、LMのためのLow-Rank Adaptation(LoRA)やDeepMindのSparrow LMを参照してください)。PPOは比較的長い間存在しており、その動作方法についてのガイドはたくさんあります。この方法の相対的な成熟度により、RLHFのための分散トレーニングのスケーリングに適した選択肢となりました。実際、RLHFにおいては、この大規模なモデルをなじみのあるアルゴリズムで更新する方法を見つけることが、RLのコアの進歩の多くであったことがわかります(後述)。
まず、この微調整タスクをRL問題として定式化しましょう。まず、ポリシーはプロンプトを受け取り、テキストのシーケンス(またはテキスト上の確率分布)を返す言語モデルです。このポリシーのアクション空間は、言語モデルの語彙に対応するすべてのトークン(通常は約50kトークンのオーダー)であり、観測空間は以前のRLの使用により非常に大きくなっています(次元はおおよそ語彙のサイズ^入力トークンシーケンスの長さとなります)。報酬関数は、好みモデルとポリシーシフトの制約の組み合わせです。
報酬関数は、システムがすべての議論したモデルを1つのRLHFプロセスに組み合わせる場所です。データセットからのプロンプトxに対して、テキストyは、現在のイテレーションの微調整されたポリシーによって生成されます。元のプロンプトと連結されたそのテキストは、好みモデルに渡され、スカラーな「好ましさ」rθが返されます。さらに、RLポリシーからのトークンごとの確率分布は、初期モデルからの確率分布と比較され、それらの間の差に対するペナルティが計算されます。OpenAI、Anthropic、DeepMindの複数の論文では、このペナルティは、トークンの分布のKLダイバージェンスのスケーリングバージョンとして設計されています(rKL)。KLダイバージェンス項は、RLポリシーが初期の事前学習モデルから大幅に離れないようにするためのものであり、モデルが合理的に整合性のあるテキストスニペットを出力するために役立ちます。このペナルティがない場合、最適化は意味のないテキストを生成して報酬モデルに高い報酬を与えることがあります。実際には、KLダイバージェンスは両方の分布からサンプリングすることによって近似されます(ここでJohn Schulmanによって説明されています)。RL更新ルールに送られる最終報酬はr = rθ – λrKLです。
一部のRLHFシステムは報酬関数に追加の項目を追加しています。例えば、OpenAIはInstructGPTで追加の事前学習勾配(人間の注釈セットから)をPPOの更新ルールに混ぜ込んで実験的に成功を収めました。RLHFがさらに調査されるにつれて、この報酬関数の形式は進化し続ける可能性があります。
最後に、更新ルールは、PPOからのパラメータ更新であり、現在のデータバッチの報酬メトリクスを最大化するものです(PPOはオンポリシーであり、パラメータは現在のプロンプト生成ペアのバッチのみで更新されます)。PPOは勾配に制約をかける信頼領域最適化アルゴリズムであり、更新ステップが学習プロセスを不安定化させないようにします。DeepMindはGopherに対して類似の報酬設定を使用しましたが、最適化勾配には同期利点アクター・評価(A2C)を使用しました。これは明らかに異なる方法ですが、外部で再現されていません。

技術的な詳細については、上の図は両方のモデルが同じプロンプトに対して異なる応答を生成しているように見えますが、実際にはRLポリシーがテキストを生成し、そのテキストが初期モデルに供給され、KLペナルティのための相対確率を生成することが起こります。
オプションで、RLHFは報酬モデルとポリシーを同時に反復的に更新することでこの点から続けることができます。RLポリシーが更新されるにつれて、ユーザーはこれらの出力をモデルの以前のバージョンと比較し続けることができます。この操作を実装するためのデプロイメントモードは、関与型ユーザーベースへのアクセスを持つ対話エージェントにのみ適用できるため、ほとんどの論文はまだこの操作を議論していません。AnthropicはこれをIterated Online RLHFとして議論しています(詳細は元の論文を参照してください)。この場合、ポリシーの反復はモデル間のELOランキングシステムに含まれます。これにより、ポリシーと報酬モデルの進化に関する複雑なダイナミクスが導入され、これは複雑でオープンな研究課題を示しています。
最初に、LMでRLHFを実行するためのコードがOpenAIから2019年にTensorFlowで公開されました。
現在、これに続くいくつかのRLHFの活発なリポジトリが既にPyTorchで利用可能になっています。主なリポジトリはTransformers Reinforcement Learning(TRL)、TRLX(TRLのフォークから派生したもの)、およびReinforcement Learning for Language models(RL4LMs)です。
TRLは、PPOを使用してHugging Faceエコシステムの事前学習済みLMを微調整するために設計されています。TRLXは、オンラインおよびオフラインのトレーニング用に大きなモデルを扱うためにCarperAIによって作成されたTRLの拡張フォークです。現時点で、TRLXにはLLMの展開に必要なスケールでPPOとImplicit Language Q-Learning ILQLを使用した本番対応のRLHFを実行するためのAPIがあります(例:330億パラメータ)。将来のTRLXのバージョンでは、最大2000億パラメータの言語モデルを扱うことができるようになります。そのため、TRLXとのインターフェースは、このスケールでの経験を持つ機械学習エンジニアに最適化されています。
RL4LMsは、様々なRLアルゴリズム(PPO、NLPO、A2C、TRPO)、報酬関数、およびメトリクスでのLLMの微調整と評価を提供するビルディングブロックを提供しています。さらに、このライブラリは簡単にカスタマイズできるため、任意のエンコーダーデコーダーやエンコーダートランスフォーマーベースのLMを任意のユーザー指定の報酬関数でトレーニングすることが可能です。特に、最近の作業でさまざまなタスクで広範なテストとベンチマークが行われ、データ予算の比較(専門家のデモンストレーションと報酬モデリング)、報酬ハッキングとトレーニングの不安定性の処理などに関する実用的な洞察が2000以上の実験で示されました。RL4LMsの現在の計画には、より大きなモデルと新しいRLアルゴリズムの分散トレーニングが含まれています。
TRLXとRL4LMsの両方は、現在も積極的に開発が進行中ですので、近日中にこれらを超えるさらなる機能が期待されます。
Anthropicによって作成された大規模なデータセットがHubで利用可能です。
これらの技術は非常に有望で影響力があり、AIの最大の研究所の注意を引いていますが、まだ明確な制限が存在します。モデルは改善されているものの、不確実性なしに有害または事実に反したテキストを出力する可能性があります。この不完全さはRLHFの長期的な課題であり、動機です。人間の問題領域での運用は、トレーニングループ外の他の人間労働者との直接統合により、人間の好みデータの収集が非常に高価です。RLHFのパフォーマンスは、人間による注釈の品質によってのみ決まります。注釈には、InstructGPTでの初期のLMの微調整など、人間によって生成されたテキストとモデルの出力間の人間の選好のラベルなどの2つのバラエティがあります。
特定のプロンプトに答えるために、よく書かれた人間のテキストを生成することは非常に高コストです。なぜなら、通常はパートタイムのスタッフを雇う必要があります(製品のユーザーやクラウドソーシングに頼ることはできません)。幸いなことに、RLHFのほとんどのアプリケーションの報酬モデルのトレーニングに使用されるデータの規模(約5万件のラベル付き優先度サンプル)は、それほど高価ではありません。ただし、これは学術研究所が負担できるコストよりも高いです。現在、一般的な言語モデル(Anthropicからのもの)に関するRLHFの大規模データセットは1つしか存在せず、いくつかの小規模なタスク固有のデータセット(OpenAIからの要約データなど)があります。RLHFのデータの第2の課題は、人間の注釈付け者がしばしば異なる意見を持つことであり、グラウンドトゥルースのないトレーニングデータに大きなばらつきをもたらすことです。
これらの制約を考慮すると、まだ未開拓の設計オプションの多くがRLHFに大きな進歩をもたらす可能性があります。これらの多くはRLオプティマイザの改善の範疇に含まれます。PPOは比較的古いアルゴリズムですが、他のアルゴリズムが既存のRLHFワークフローに利益と変種をもたらす理由はありません。LMポリシーの微調整のフィードバック部分の大きなコストは、ポリシーから生成されるテキストのすべてが報酬モデルで評価される必要があるためです(これは標準のRLフレームワークでは環境の一部のように機能します)。大規模なモデルの高コストなフォワードパスを回避するために、オフラインRLをポリシーオプティマイザとして使用することができます。最近では、このタイプの最適化と特によく合うimplicit language Q-learning(ILQL)[ CarperAIでのILQLに関するトーク]などの新しいアルゴリズムが登場しています。探索と活用のバランスなど、RLプロセスの他の核心的なトレードオフも文書化されていません。これらの方向を探索することによって、少なくともRLHFの機能についての相当な理解が開発され、改善されたパフォーマンスが提供される可能性があります。
2022年12月13日(火曜日)にこの投稿についての講義を開催しました。こちらでご覧いただけます!
さらなる読み物
これまでのRLHFに関する最も一般的な論文のリストを以下に示します。DeepRLの登場(2017年頃)により、この分野は広範なLLMのアプリケーションの研究に成長しました。以下は、LMに焦点を当てる前のRLHFに関するいくつかの論文です。
- TAMER: Training an Agent Manually via Evaluative Reinforcement (Knox and Stone 2008): 人間が反復的に行動にスコアを付けることで報酬モデルを学習する学習エージェントを提案しました。
- Interactive Learning from Policy-Dependent Human Feedback (MacGlashan et al. 2017): ヒューマンフィードバック(肯定的、否定的両方)を使用してアドバンテージ関数を調整するためのアクター・クリティックアルゴリズムCOACHを提案しました。
- Deep Reinforcement Learning from Human Preferences (Christiano et al. 2017): Atariの軌跡間の優先度にRLHFを適用しました。
- Deep TAMER: Interactive Agent Shaping in High-Dimensional State Spaces (Warnell et al. 2018): TAMERフレームワークを拡張し、報酬予測にディープニューラルネットワークを使用しました。
さらに、LLMのパフォーマンスを示す「主要な」論文の増加するセットのスナップショットも以下に示します。
- Fine-Tuning Language Models from Human Preferences (Zieglar et al. 2019): 報酬学習が4つの具体的なタスクに与える影響を研究した初期の論文です。
- Learning to summarize with human feedback (Stiennon et al., 2020): テキストの要約タスクにRLHFを適用しました。また、書籍の要約に関する続編の研究もあります(OpenAI Alignment Team 2021)。
- WebGPT: Browser-assisted question-answering with human feedback (OpenAI, 2021): RLHFを使用してエージェントをWeb上でナビゲートするためにトレーニングしました。
- InstructGPT: Training language models to follow instructions with human feedback (OpenAI Alignment Team 2022): 一般的な言語モデルにRLHFを適用しました[ InstructGPTに関するブログ投稿]。
- GopherCite: Teaching language models to support answers with verified quotes (Menick et al. 2022): 特定の引用を持つ回答を返すためのRLHFでLMをトレーニングしました。
- Sparrow: Improving alignment of dialogue agents via targeted human judgements (Glaese et al. 2022): RLHFで対話エージェントを微調整しました。
- ChatGPT: Optimizing Language Models for Dialogue (OpenAI 2022): あらゆる用途のチャットボットとして適したLMをRLHFでトレーニングしました。
- Scaling Laws for Reward Model Overoptimization (Gao et al. 2022): RLHFで学習された優先度モデルのスケーリング特性を研究しました。
- Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback (Anthropic, 2022): RLHFでLMアシスタントをトレーニングする詳細なドキュメントです。
- Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned (Ganguli et al. 2022): 「潜在的に有害な出力を発見し、測定し、削減しようとする」取り組みの詳細なドキュメントです。
- Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning (Cohen at al. 2022): RLを使用してオープンエンドの対話エージェントの対話スキルを向上させるために使用しました。
- Is Reinforcement Learning (Not) for Natural Language Processing?: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization (Ramamurthy and Ammanabrolu et al. 2022): RLHFのオープンソースツールの設計空間について議論し、PPOの代替手段として新しいアルゴリズムNLPO(Natural Language Policy Optimization)を提案しています。
この分野は複数の分野の収束点であり、他の分野でもリソースを見つけることができます:
- 指示の継続的学習(Kojima et al. 2021、Suhr and Artzi 2022)やユーザフィードバックからのバンディット学習(Sokolov et al. 2016、Gao et al. 2022)
- テキスト生成のための他のRLアルゴリズムの以前の歴史(すべてが人間の好みとは限らない)を使用した以前の研究、例えば再帰ニューラルネットワークを用いたもの(Ranzato et al. 2015)、テキスト予測のためのアクターコメディアンアルゴリズム(Bahdanau et al. 2016)、またはこのフレームワークに人間の好みを追加した初期の研究(Nguyen et al. 2017)
引用:もし学術的な研究においてこの情報が役立つと考えた場合、以下のテキストを引用していただけると幸いです:
Lambert, et al., "Illustrating Reinforcement Learning from Human Feedback (RLHF)", Hugging Face Blog, 2022.BibTeX引用:
@article{lambert2022illustrating,
author = {Lambert, Nathan and Castricato, Louis and von Werra, Leandro and Havrilla, Alex},
title = {Illustrating Reinforcement Learning from Human Feedback (RLHF)},
journal = {Hugging Face Blog},
year = {2022},
note = {https://huggingface.co/blog/rlhf},
}特定のRLHFの具体的な実装に関する事実上の誤りの修正には、Robert Kirkに感謝します。関連研究を歴史的にさらに拡大するために、Peter Stone、Khanh X. Nguyen、Yoav Artziに感謝します。
一部の誤字や混乱するフレーズの修正には、Stas Bekmanに感謝します。
RLHF手順のKLペナルティ項、その図表、およびテキストの説明における技術的な誤りを指摘してくれたIgor Kotenkovに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





