ロッテン・トマト映画の評価予測のデータサイエンスプロジェクト:2つ目のアプローチ
ロッテン・トマト映画の評価予測のデータサイエンスプロジェクトの2つ目のアプローチ
このデータサイエンスのプロジェクトは、Meta(Facebook)の採用プロセスでテイクホーム課題として使用されています。このテイクホーム課題では、Rotten Tomatoesが「Rotten」、「Fresh」、または「Certified Fresh」とラベル付けしている方法を探求します。
このデータサイエンスのプロジェクトへのリンク: https://platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
それを行うために、2つの異なるアプローチを開発します。
- クレジットカードの取引データを使用した顧客セグメンテーションのマスタリング
- Mageを使用してデータパイプラインでの振る舞い駆動開発を実装してください
- 企業がOpenAIのChatGPTに類似した自社の大規模言語モデルを構築する方法
私たちの探求の過程で、データの前処理、さまざまな分類器、およびモデルのパフォーマンスを向上させるための潜在的な改善点について議論します。
この投稿の最後までに、映画の成功を予測するために機械学習がどのように活用されるか、そしてこの知識がエンターテイメント業界にどのように応用されるかを理解することができるでしょう。
しかし、もっと深く掘り下げる前に、私たちが取り組むデータを見つけてみましょう。
第2のアプローチ:レビューの感情に基づいて映画のステータスを予測する
第2のアプローチでは、映画の成功をレビューの感情分析によって予測する予定です。具体的には、レビューの全体的な感情を評価し、この感情に基づいて映画を「Fresh」または「Rotten」と分類します。
しかし、感情分析を開始する前に、まずデータセットの準備をしなければなりません。この戦略では、数値やカテゴリ変数ではなく、テキストデータ(レビュー)を扱う必要があります。この課題では、引き続きRandom Forestモデルを使用します。それでは、進む前にデータを詳しく見てみましょう。
まず、データを読み込みましょう。
以下がコードです。
df_critics = pd.read_csv('rotten_tomatoes_critic_reviews_50k.csv')
df_critics.head()以下が出力です。

素晴らしいですね、データの前処理を始めましょう。
データの前処理
このデータセットでは、映画の名前と対応するステータスがありません。このデータセットでは、review_contentとreview_typeの変数があります。
そのため、このデータセットを前のデータセットとrotten_tomatoes_linkで結合し、次のようにインデックスブラケットを使用して必要な特徴を選択します。
以下がコードです。
df_merged = df_critics.merge(df_movie, how='inner', on=['rotten_tomatoes_link'])
df_merged = df_merged[['rotten_tomatoes_link', 'movie_title', 'review_content', 'review_type', 'tomatometer_status']]
df_merged.head()以下が出力です。

このアプローチでは、入力特徴量としてreview_content列のみを使用し、ground truthラベルとしてreview_typeを使用します。
使用するデータが利用可能であることを確認するために、感情分析では空のレビューは使用できないため、review_content列の欠損値をフィルタリングする必要があります。
df_merged = df_merged.dropna(subset=['review_content'])欠損値をフィルタリングした後、review_typeの分布を視覚化してデータの分布をよりよく理解します。
# レビューの分布をプロットする
ax = df_merged.review_type.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])この視覚化により、データにクラスの不均衡があるかどうかを判断し、モデルの適切な評価指標の選択に役立ちます。
以下が全体のコードです。
df_merged = df_merged.dropna(subset=['review_content'])
# レビューの分布をプロットする
ax = df_merged.review_type.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])出力はこちらです。
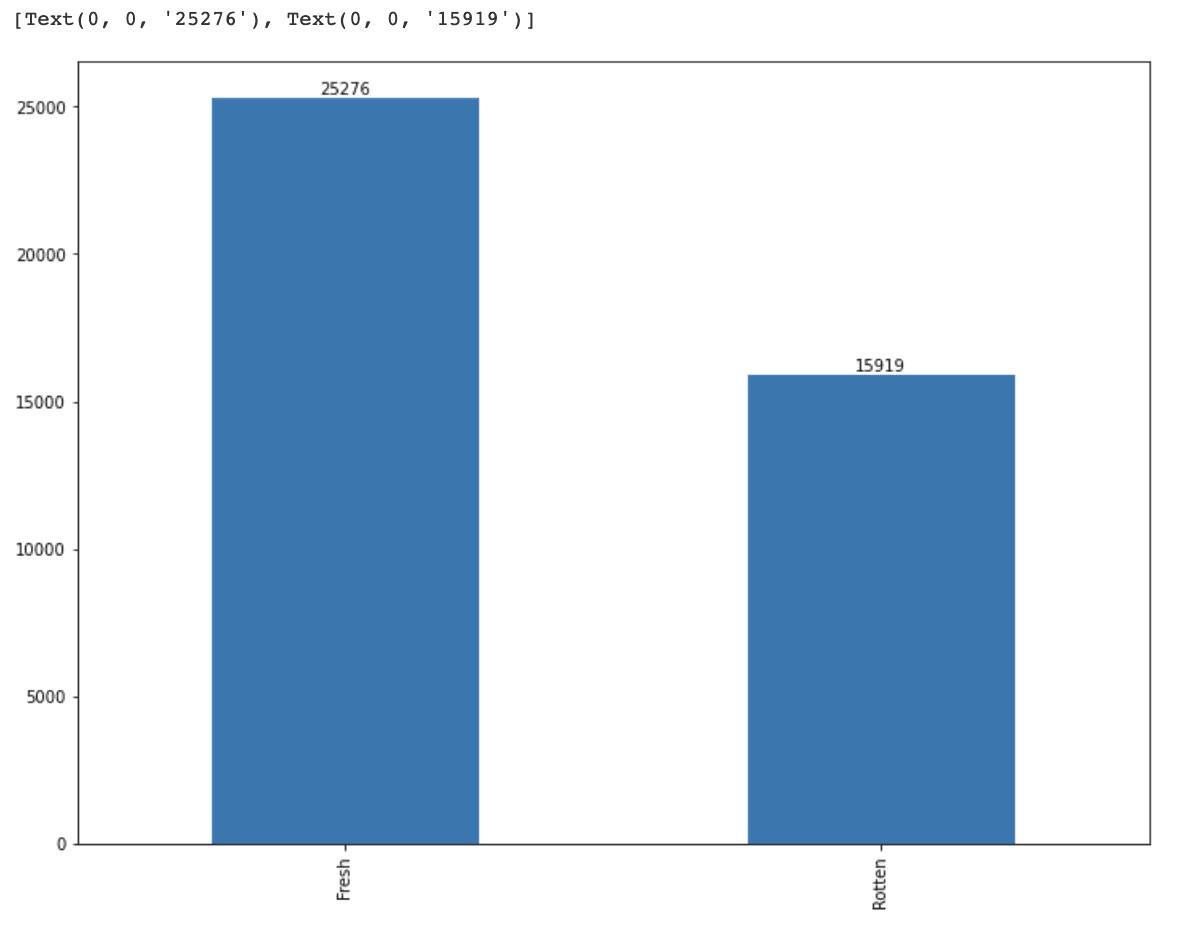
特徴量間のバランスの問題があるようです。
また、データポイントが多すぎるため、処理速度が低下する可能性があります。
そこで、まず元のデータセットから5000エントリを選びます。
df_sub = df_merged[0:5000]次に、順序エンコーディングを行います。
review_type = pd.DataFrame(df_sub.review_type.replace(['Rotten','Fresh'],[0,1]))最後に、Pythonのconcat()メソッドを使用してエンコードされたラベルとレビューコンテンツを含むデータフレームを作成し、head()メソッドを使用して最初の5行を表示します。
df_feature_critics = pd.concat([df_sub[['review_content']]
,review_type], axis=1).dropna()
df_feature_critics.head()以下が全体のコードです。
# 元のデータセットから5000エントリのみを選択
df_sub = df_merged[0:5000]
# ラベルをエンコード
review_type = pd.DataFrame(df_sub.review_type.replace(['Rotten','Fresh'],[0,1]))
# 最終的なデータフレームを構築
df_feature_critics = pd.concat([df_sub[['review_content']]
,review_type], axis=1).dropna()
df_feature_critics.head()出力はこちらです。

素晴らしいですね、このセクションの最後のステップとして、データセットをトレインセットとテストセットに分割しましょう。
X_train, X_test, y_train, y_test = train_test_split( df_feature_critics['review_content'], df_feature_critics['review_type'], test_size=0.2, random_state=42)デフォルトのランダムフォレスト
機械学習手法でデータフレーム内のテキストレビューを使用するためには、それらを処理できる形式に変換する必要があります。自然言語処理では、これをトークン化と呼び、テキストや単語をn次元ベクトルに変換し、これらのベクトル表現を機械学習アルゴリズムのトレーニングデータとして使用します。
これを行うために、scikit-learnのCountVectorizerクラスを使用してテキストレビューをトークン数の行列に変換します。まず、入力テキストから一意の用語の辞書を作成します。
例えば、”This movie is good”と”The movie is bad”という2つのレビューに基づいて、アルゴリズムは次のような一意のフレーズの辞書を作成します。
次に、入力テキストに基づいて、辞書内の各単語の出現回数を計算します。
[“this”, “movie”, “is”, “a”, “good”, “the”, “bad”]。
例えば、入力 “This movie is a good movie” は、ベクトル [1, 2, 1, 1, 1, 0, 0] になります。
最後に、生成されたベクトルをランダムフォレストモデルに入力します。
トレーニングデータのテキストデータを数値ベクトルに変換するCountVectorizerクラスのインスタンスを作成し、単語が少なくとも1つのドキュメントに現れる場合にのみ語彙に含めることを指定するコードは次のようになります。
# ベクトライザークラスのインスタンスを作成
vectorizer = CountVectorizer(min_df=1)次に、インスタンス化されたCountVectorizerオブジェクトを使用してトレーニングデータをベクトル化します。
# テキストデータをベクトルに変換
X_train_vec = vectorizer.fit_transform(X_train).toarray()そして、指定されたランダムステートを持つRandomForestClassifierオブジェクトをインスタンス化し、トレーニングデータを使用してランダムフォレストモデルをフィットさせます。
# ランダムフォレストを初期化してトレーニング
rf = RandomForestClassifier(random_state=2)
rf.fit(X_train_vec, y_train)これで、トレーニング済みモデルと変換されたテストデータを使用して予測する時が来ました。
そして、適合率、再現率、F1スコアなどの評価メトリクスを含む分類レポートを出力します。
# 予測して分類レポートを出力する
y_predicted = rf.predict(vectorizer.transform(X_test).toarray())
print(classification_report(y_test, y_predicted))最後に、混同行列のプロットのために指定されたサイズで新しい図を作成し、混同行列をプロットします。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax以下は全体のコードです。
# ベクトライザークラスのインスタンス化
vectorizer = CountVectorizer(min_df=1)
# テキストデータをベクトルに変換する
X_train_vec = vectorizer.fit_transform(X_train).toarray()
# ランダムフォレストを初期化してトレーニングする
rf = RandomForestClassifier(random_state=2)
rf.fit(X_train_vec, y_train)
# 予測して分類レポートを出力する
y_predicted = rf.predict(vectorizer.transform(X_test).toarray())
print(classification_report(y_test, y_predicted))
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax以下は出力結果です。

重み付きランダムフォレスト
最新の混同行列からわかるように、モデルの性能は十分に良くありません。
しかし、これはデータポイントの数が限られているために予想されることかもしれません。(10万ではなく5000)
クラスの不均衡問題を解決するために、クラスの重み付けで性能を向上させることができるかどうか見てみましょう。
以下はコードです。
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature_critics.review_type),
y = df_feature_critics.review_type.values)
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()))
class_weight_dict以下は出力結果です。
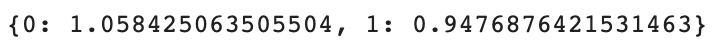
今度はテキスト入力をベクトル化したデータでランダムフォレスト分類器をトレーニングしますが、今回はクラスの重み情報を含めて評価指標を向上させます。
まず、CountVectorizerクラスを作成し、以前と同様にテキスト入力をベクトルに変換します。
そして、テキストデータをベクトルに変換します。
vectorizer = CountVectorizer(min_df=1)
X_train_vec = vectorizer.fit_transform(X_train).toarray()次に、計算されたクラスの重みを考慮してランダムフォレストを定義し、トレーニングします。
# ランダムフォレストを初期化してトレーニングする
rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict)
rf_weighted.fit(X_train_vec, y_train)テストデータを使用して予測し、分類レポートを出力します。
# 予測して分類レポートを出力する
y_predicted = rf_weighted.predict(vectorizer.transform(X_test).toarray())
print(classification_report(y_test, y_predicted))最後に、図のサイズを設定し、混同行列をプロットします。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf_weighted, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax)以下は全体のコードです。
# ベクトライザークラスのインスタンス化
vectorizer = CountVectorizer(min_df=1)
# テキストデータをベクトルに変換する
X_train_vec = vectorizer.fit_transform(X_train).toarray()
# ランダムフォレストを初期化してトレーニングする
rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict)
rf_weighted.fit(X_train_vec, y_train)
# 予測して分類レポートを出力する
y_predicted = rf_weighted.predict(vectorizer.transform(X_test).toarray())
print(classification_report(y_test, y_predicted))
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf_weighted, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax)以下は出力結果です。
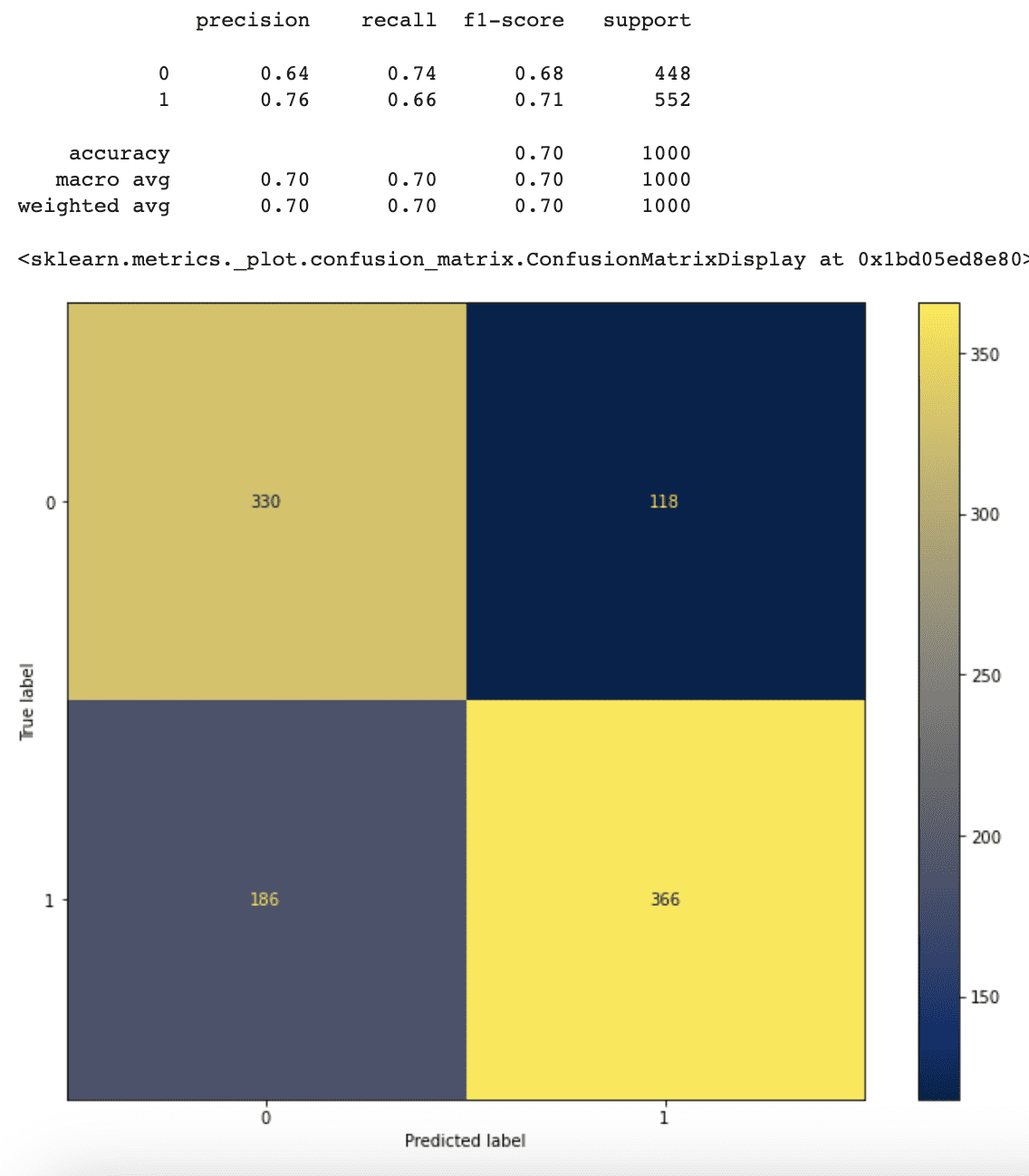
今、私たちのモデルの精度は、クラスの重みを考慮しないモデルよりもわずかに良くなっています。
さらに、クラス0(’Rotten’)の重みがクラス1(’Fresh’)の重みよりも大きいため、モデルは今では ‘Rotten’ 映画のレビューをより正確に予測する一方で、 ‘Fresh’ 映画のレビューをより悪く予測します。
これは、モデルが ‘Rotten’ と分類されたデータにより注意を払っているためです。
映画の状態予測
今、私たちのランダムフォレストモデルを使用して、映画の状態を予測しましょう。映画のレビューの感情を予測するようにトレーニングされたモデルを使用します。次のステージを進めて、映画の状態を決定します:
- 特定の映画のすべてのレビューを収集します。
- ランダムフォレストモデルを使用して、各レビューの状態(例: ‘Fresh’ または ‘Rotten’)を推定します。
- 映画の最終的な状態を、Rotten Tomatoesのウェブサイトで提供されているルールベースのアプローチを使用して、レビューの状態の合計に基づいて分類します。
次のコードでは、まず予測を引数として受け取る predict_movie_statust という関数を作成します。
その後、positive_percentage の値に応じて映画の状態を識別し、予測変数に ‘Fresh’ または ‘Rotten’ を割り当てます。
最後に、映画の状態とともに、肯定的なレビューの割合を出力します。
以下はコードです。
def predict_movie_status(prediction):
"""予測に基づいてラベル(Fresh/Rotten)を割り当てる"""
positive_percentage = (prediction == 1).sum()/len(prediction)*100
prediction = 'Fresh' if positive_percentage >= 60 else 'Rotten'
print(f'肯定的なレビュー:{positive_percentage:.2f}%')
print(f'映画の状態:{prediction}')この例では、3つの映画の状態を予測します:Body of Lies、Angel Heart、The Duchessです。Body of Liesから始めましょう。
‘Body of Lies’ の予測
上記に記載されているように、まず Body of Lies 映画のすべてのレビューを収集しましょう。
以下はコードです。
# Body of Lies 映画のすべてのレビューを収集する
df_bol = df_merged.loc[df_merged['movie_title'] == 'Body of Lies']
df_bol.head()以下は出力です。

素晴らしい、この段階では重み付きランダムフォレストアルゴリズムを適用して状態を予測します。そして、予測を引数として受け取る以前に定義したカスタム関数を使用します。
以下はコードです。
y_predicted_bol = rf_weighted.predict(vectorizer.transform(df_bol['review_content']).toarray())
predict_movie_status(y_predicted_bol)以下は出力です。

そして、ここで結果です。予測結果をグラウンドトゥルースの状態と比較して、有効かどうかをチェックします。
以下はコードです。
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'Body of Lies'].unique()以下は出力です。

予測がかなり正確であるようです。なぜなら、この映画の状態は予測通りに Rotten であるからです。
‘Angel Heart’ の予測
すべてのステップを繰り返します。
- すべてのレビューを収集する
- 予測を行う
- 比較する
まず、Anna Karenina の映画のすべてのレビューを収集しましょう。
以下はコードです。
df_ah = df_merged.loc[df_merged['movie_title'] == 'Angel Heart']
df_ah.head()以下は出力です。

今はランダムフォレストとカスタム関数を使って予測を行う時間です。
以下がコードです。
y_predicted_ah = rf_weighted.predict(vectorizer.transform(df_ah['review_content']).toarray())
predict_movie_status(y_predicted_ah)以下が出力です。

比較してみましょう。
以下がコードです。
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'Angel Heart'].unique()以下が出力です。
モデルは再び正しく予測しています。
さあ、もう一度やってみましょう。
‘The Duchess’ の予測
まずは全てのレビューを収集しましょう。
以下がコードです。
df_duchess = df_merged.loc[df_merged['movie_title'] == 'The Duchess']
df_duchess.head()以下が出力です。

予測を行う時間です。
以下がコードです。
y_predicted_duchess = rf_weighted.predict(vectorizer.transform(df_duchess['review_content']).toarray())
predict_movie_status(y_predicted_duchess)以下が出力です。

予測結果を正解データと比較しましょう。
以下がコードです。
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'The Duchess'].unique()以下が出力です。

映画の正解ラベルは ‘Fresh’ ですが、モデルの予測は間違っています。
ただし、モデルの予測は60%の閾値に非常に近いことが分かります。これは、モデルを少し調整すれば ‘Rotten’ から ‘Fresh’ に予測が変わる可能性があることを示しています。
明らかに、上記でトレーニングしたランダムフォレストモデルは最も優れたモデルではありません。改善の余地がまだあります。次のパートでは、モデルの性能を向上させるための多くの提案を提供します。
パフォーマンス向上のための提案
- 使用するデータの量を増やす。
- ランダムフォレストモデルの異なるハイパーパラメータを設定する。
- 異なる機械学習モデルを適用して最適なモデルを見つける。
- テキストデータを表現するために使用する方法を調整する。
結論
この記事では、数値データとカテゴリカルデータを基に映画のステータスを予測するための2つの異なるアプローチを探求しました。
まず、データの前処理を行い、次に決定木分類器とランダムフォレスト分類器を適用してモデルをトレーニングしました。
また、特徴選択と重み付けランダムフォレスト分類器も試しました。
2番目のアプローチでは、デフォルトのランダムフォレストと重み付けランダムフォレストを使用して、3つの異なる映画のステータスを予測しました。
モデルのパフォーマンスを向上させるための提案を提供しました。この記事が有益であることを願っています。
初心者レベルのプロジェクトをお探しの場合は、当社の記事「初心者向けのデータサイエンスプロジェクトアイデア」をチェックしてください。Nate Rosidiはデータサイエンティストであり、製品戦略に携わっています。また、実践的な面接問題を含むインタビュー準備を支援するプラットフォームであるStrataScratchの創設者でもあります。Twitter: StrataScratchまたはLinkedInで彼と繋がることができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
