レコメンドシステムの評価指標 — 概要
レコメンドシステムの評価指標 — 概要' -> 'レコメンドシステムの評価指標概要
MLパッケージにおける一般的なメトリックの目的と機能の理解
最近、レコメンデーションシステムのプロジェクトで実験している際に、さまざまな評価メトリックを使用することがありました。そのため、役に立つメトリックのリストと、レコメンデーションシステムの評価時に考慮すべき他の要素をまとめました。これらのメトリックはMLパッケージでよく見られますが、その目的と機能を理解することは重要です。
Recall @K
Recall@Kは、上位K個の推薦アイテムの中にどれだけ関連するアイテムが含まれているかを測定する指標です。Kはユーザーに対して生成される推薦の数です。例えば、ユーザーごとに10個の映画を推薦する映画レコメンダーシステムを構築している場合、ユーザーが5つの映画を視聴しており、私たちの推薦リストにはそのうち3つが含まれている場合、ユーザーのRecall@10は3/5 = 0.6と計算されます。通常、評価のためにすべてのユーザーに対して平均が取られます。
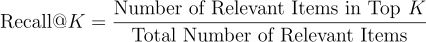
ビジネスの観点から見て、システムがユーザーの行動を予測するという意味でどれだけ優れているかを示すために、シンプルで重要なメトリックです。
- 「2023年に必要な機械学習エンジニアの10の必須スキル」
- 「DeepMindによるこのAI研究は、シンプルな合成データを使用して、大規模な言語モデル(LLM)におけるおべっか使用を減らすことを目指しています」
- 「ConDistFLとの出会い:CTデータセットにおける臓器と疾患のセグメンテーションのための革新的なフェデレーテッドラーニング手法」
範囲: 0–1
Precision @K
Precision@Kは、ユーザーに対して生成されるK個の推薦アイテムのうち、どれだけが関連しているかを測定する指標です。
例えば、ユーザーごとに10個の映画を推薦するレコメンデーションシステムの場合、ユーザーが5つの映画を視聴しており、そのうち3つを予測できた場合(推薦リストに3つの映画が含まれている場合)、Precision@10は3/10です。
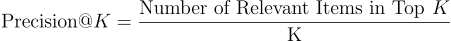
システムがユーザーに提供できる推薦の数には限りがあるため、スケールとランキングの観点から非常に重要なメトリックです。これは以下のように関連付けることができます:注意力(ユーザーは一目で関連する推薦を見ることができるようにしたいため、上位に関連する推薦が重要です)、およびメモリ要件(ユーザーごとに100個の推薦しか保存できない場合、選択する内容には正確さが求められます)。
範囲: 0–1
F1 @K
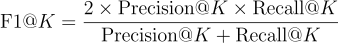
F1スコアは、適合率と再現率の調和平均を使用した指標です。これは通常のF1スコアと同じであり、レコメンデーションシステムの文脈では異なりません。調和平均の性質により、適合率または再現率のいずれかが非常に高い値を持つ場合、スコアを支配することはありません。F1スコアは、適合率と再現率の値が1に近い場合に高い値を持ちます。
範囲: 0–1
ランキング関連のメトリック:
先述のように、適合率について話す際には、上位に関連する推薦が重要です。関連する推薦が実際に上位にあるかどうかを測定するためのさまざまな方法があります。これらの測定は評価だけでなく、ランキングモデルの損失メトリックとしても使用されます。
Mean Average Precision @K
推薦リストがリスト内の位置に基づいて関連するアイテムを予測するのにどれだけ優れているかを測定する方法の1つは、「Mean Average Precision」を使用することです。まず、Average Precisionが何を意味するかを理解しましょう。K個のアイテムを推薦し、そのうちQ個が関連している場合、Average Precisionは次のように定義されます:
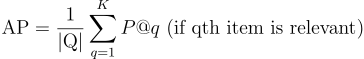
すべての関連するアイテムが上位にある場合、そのユーザーのAverage Precisionスコアは高くなります。
例:
推薦リスト:[「トップガン」、「アライバル」、「グラディエーター」]
正解:[「アライバル」、「グラディエーター」]
Precision @K:[0、1/2、2/3]
Average Precision(AP)=(1/3)[(1/2) + (2/3)] = 0.38
MAP(Mean Average Precision)は、すべてのユーザーにおける平均精度(AP)の値の平均です:

範囲:0〜1
平均逆順位(MRR)
平均逆順位(MRR)は、推薦リスト内で最初に見つかる関連アイテムの位置を測定します。逆順位(RR)は、最高ランクの結果の位置のみが重要な場合に使用されます。ここで、ランクは推薦リスト内のアイテムの位置です。
逆順位は有用です。なぜなら、ランクが低い(例:ランク20)アイテムは、逆数の値が非常に小さくなるため、スコアが低くなるからです。したがって、最も関連性の高いアイテムがリストの先頭に予測されると有利になります。
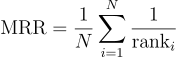
逆順位は最初の関連アイテムのみに関心があります。例:
推薦リスト:[「トップガン」、「アライバル」、「グラディエーター」]
正解:「アライバル」
すると、逆順位(RR)=(1/2)= 0.5
推薦システムのコンテキストでは、複数の値がある場合、MRRも使用できます。それらを平均化することができます。
推薦リスト:[「トップガン」、「アライバル」、「グラディエーター」]
正解:[「アライバル」、「グラディエーター」]
すると、平均逆順位(MRR)= 1/2 *((1/2)+(1/3))= 0.41
範囲:0〜1
正規化累積割引利得(NDCG)
正規化累積割引利得(NDCG)は、ランク付けされたリストの優れた度合いを測定する指標です。アイテムが関連性の高い順に並べられると、NDCGスコアは、最も関連性の高いアイテムがリストの先頭に推薦される場合に最大化されます。
次の例を使って詳しく説明しましょう:
前の例に沿って説明するために、ユーザーをアクション映画の視聴者として特定すると、関連性スコアは次のようになります:
「トップガン」、「グラディエーター」:2(最も関連性が高い)
「トイストーリー」:1
「ザ・ウェール」:0(最も関連性が低い)
推薦リスト:
[「トップガン」、「トイストーリー」、「ザ・ウェール」、「グラディエーター」] ⇒ [2, 1, 0, 2]
累積利得(CG):位置pにおける累積利得は、その位置の関連性スコアです。したがって、リスト全体における累積利得は、2 + 1 + 0 + 2 = 5です。
累積利得はアイテムの位置を考慮していません。したがって、最も関連性の高いアイテムがリストの最後にある場合(例:「グラディエーター」のように)、CGスコアには反映されません。
それを解決するために、割引累積利得(DCG)を導入します。ここでは、各位置にスコア/割引を割り当て、関連性スコアがペナルティを受けることになります。
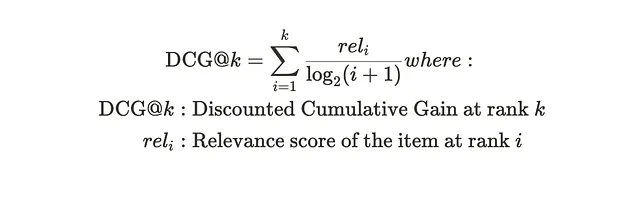
したがって、関連アイテムである「グラディエーター」などがリストの最後に推薦される場合、リストのサイズnに1 / log2(n)(nはリストのサイズです。0.2のような非常に小さな数値で乗算されるため、そのスコアへの貢献は非常に小さくなります)で割り引かれます。 DCGスコアは、関連性の高いアイテムがすべてトップにある場合に最大です。
アイテムの場合、セットA:[2, 1, 0, 2]:
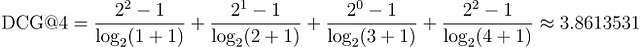
これをセットAと比較してみましょう:[3, 2, 1, 0]。関連するアイテムが上位にあります:
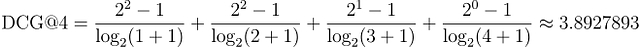
明らかに、セットBのDCGはセットAのDCGよりも高いです。また、セットBは私たちが理想的な順位でアイテムを完全にソートした場合のDCGを表す理想的な割引累積ゲイン(IDCG)です。
異なるサイズの2つのリストのDCGスコアを比較する場合はどうなるでしょうか?その場合、IDCGが登場します。DCGスコアをIDCGスコアで割り、0〜1の値を得ます。このスコアは正規化割引累積ゲイン(nDCG)と呼ばれます。
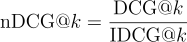
これで、異なるサイズの2つのリストのnDCGスコアを比較できます。
nDCGの範囲:0〜1
これは、レコメンダーシステムを評価するために広く使用されるいくつかのメトリックの概要です。
レコメンダーシステムを評価する際に考慮すべき事項:
これらのトピックについての記事をまとめる予定です。その場合は、ここにリンクを記載します。
- 人気バイアス
レコメンダーシステムには人気バイアスが大きく存在し、一般的なメトリックでは人気のあるアイテムが関連性が高くスコアが高いため、これを検出して修正するのは困難です。人気バイアスを測定し修正する方法はさまざまあり、それについての記事をまとめる予定です。

2. 位置バイアス
位置バイアスは、リストの上位に配置されたアイテムが実際の関連性に関係なくより多く表示または購入される傾向がある場合に発生します。その結果、ランキングが低いアイテムはより少ないエンゲージメントを受けます。これは他のメトリックにも影響を与える可能性があり、これを軽減する方法があります。
3. 退化フィードバックループ
ユーザーが提案されたアイテムとのやり取りに制限され、アルゴリズムがこれらの提案からのユーザーフィードバックに依存する場合、否定的なフィードバックループが発生する可能性があります。このループにより、以前に表示されたアイテムの表示が強化され、ユーザーがまだ発見していない関連性の高いアイテムの大部分が時間の経過とともに見つからない可能性があります。
参考文献:
Wikiwand – 平均逆順位
平均逆順位は、可能性のある応答のリストを生成する任意のプロセスを評価するための統計的尺度です…
www.wikiwand.com
レコメンダーシステムの平均平均精度(MAP)
おっ、パンが1つあります。これを読んでいるので、「平均平均精度」という用語に遭遇したことがあるかもしれません。
sdsawtelle.github.io
レコメンダーシステムの評価メトリック
レコメンダーシステムはオンライン小売業界でますます人気があります。使用されるいくつかのメトリックをご覧ください。
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「PUGに会ってください:メタAIによるアンリアルエンジンを使用したフォトリアルで意味的に制御可能なデータセットを用いた堅牢なモデル評価に関する新しいAI研究」
- USCとMicrosoftの研究者は、UniversalNERを提案します:ターゲット指向の蒸留で訓練され、13,000以上のエンティティタイプを認識し、43のデータセット上でChatGPTのNER精度を9%F1上回る新しいAIモデルです
- インフォグラフィックスでデータ可視化をどのように使用するか?
- 「データの可視化を改善するための4つの必須リソース」
- 高パフォーマンスなリアルタイムデータモデルの構築ガイド
- 「データサイエンスは難しいのか?現実を知ろう」
- Google AIは、ドキュメント理解タスクの進捗状況をより正確に追跡するためのデータセットである「Visually Rich Document Understanding (VRDU)」を導入しました
