ルシーンの内部 – 整数のエンコーディングと圧縮の取り扱い
'ルシーンの内部 - 整数のエンコーディングと圧縮'
PackedInts、VInt、FixedBitSet、およびRoaringDocIdSet(Roaring Bitmaps)に深入りする

以前に、類似性検索のための製品量子化を使用したベクトルの圧縮について学びました。
類似性検索のための製品量子化
非対称距離計算を使用した類似性検索のために、巨大なベクトルセットをメモリに圧縮して適合させる方法…
towardsdatascience.com
この記事では、整数がどのようにエンコードおよび圧縮されるかについて、Luceneで中心的な役割を果たす逆インデックスの世界を探求し、洞察を得ます。
Luceneの簡単な紹介
Luceneは、Javaで書かれたオープンソースの検索エンジンライブラリです。Doug Cuttingによって1999年に作成され、フルテキスト検索とインデックス作成でよく知られています。
- Excel vs Tableau – どちらが優れたツールですか?
- あなたが作るものはあなたそのものです:コードをより人間的にする方法
- オムニヴォアに出会おう:スタートアップが開発したアプリは、スマートフォンだけでオブジェクトを3Dモデルに変換することができます
このApacheソフトウェア財団のオープンソースソフトウェアプロジェクトは、20年以上にわたり活発な開発が行われています。これまでに進化し成長し、強力で完全に機能した高性能な検索エンジンライブラリとなりました。
Luceneの成功は、その強力なコミュニティとコミッターによる信じられないほどの貢献のおかげです。彼らの参加と協力により、Luceneは現在の地位に至りました。SolrやElasticsearchなどの人気のあるエンタープライズ検索プラットフォームやソリューションは、Luceneの上に構築されています。
「オープンソースプロジェクトとしては、20年は長い時間です。疑いの余地なく、Luceneの長寿は、そのコミュニティの強さと多様性を示しています」- Apache Luceneの20周年を祝う
逆インデックス
逆インデックスはLuceneの中心に位置しています。逆インデックスは2つのパートで構成されます- 左側には用語の辞書があり、右側には各用語の頻出リストがあります。
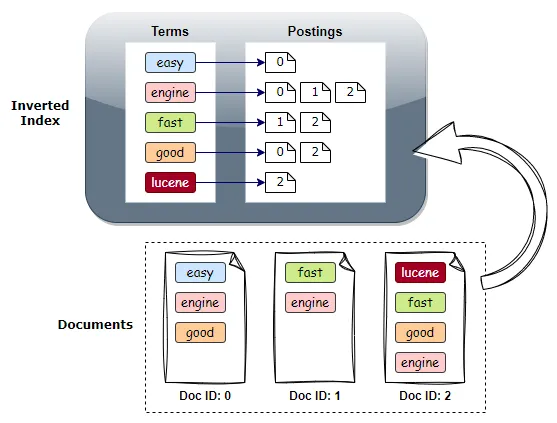
頻出リストには、用語が文書内に出現する情報が含まれています。頻出リストには、文書のドキュメントIDが含まれています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






