ラマインデックスを使って、独自のパンダAIを作りましょう
ラマインデックスを使って、パンダAIを作りましょう

イントロダクション
Pandas AIは、一般的なデータ分析ライブラリであるPandasを強化するために、生成AIの力を活用するPythonライブラリです。シンプルなプロンプトだけで、Pandas AIを使用して、以前は複数行のコードが必要だった複雑なデータのクリーニング、分析、可視化が行えます。
数値の処理を超えて、Pandas AIは自然言語を理解します。簡単な英語でデータについての質問をすることができ、複雑なグラフや表を解読する手間を省いて、要約や洞察を提供します。
以下の例では、Pandasのデータフレームを提供し、生成AIにバーチャートの作成を依頼しました。その結果は印象的です。
pandas_ai.run(df, prompt='リリース年ごとのメディアの種類のバーチャートを作成し、異なる色で表示してください。')
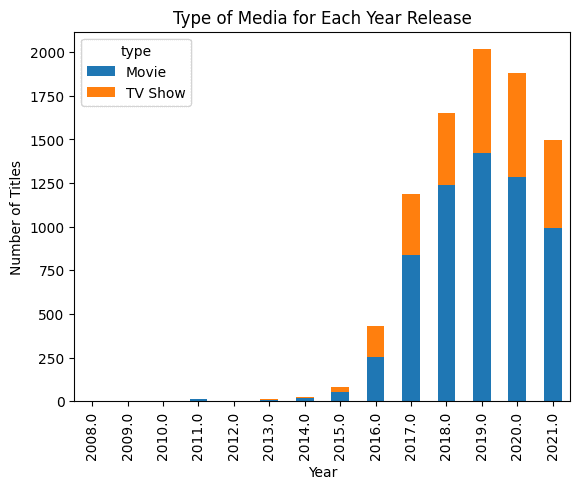
注意: このコード例は「Pandas AI: Generative AI-Powered Data Analysisチュートリアル」から取得しました。
この投稿では、LlamaIndexを使用して、上記のようなPandasデータフレームを理解し、複雑な結果を生成する類似のツールを作成します。
LlamaIndexは、チャットとエージェントを介したデータの自然言語クエリングを可能にします。新しいデータに対して再訓練することなく、大規模な言語モデルでプライベートデータをスケールで解釈することができます。さまざまなデータソースとツールと大規模な言語モデルを統合します。LlamaIndexは、わずか数行のコードでChat with PDFアプリケーションを簡単に作成できるデータフレームです。
設定
pipコマンドを使用してPythonライブラリをインストールできます。
pip install llama-index
LlamaIndexはデフォルトでOpenAIのgpt-3.5-turboモデルをテキスト生成に、text-embedding-ada-002を検索と埋め込みに使用します。コードを簡単に実行するために、OPENAI_API_KEYを設定する必要があります。新しいAPIトークンページで無料でAPIキーを登録して取得できます。
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxxxx"
Anthropic、Hugging Face、PaLMなどのモデルの統合もサポートしています。モジュールのドキュメントを読むことで、詳細をすべて学ぶことができます。
Pandasクエリエンジン
自分自身のPandasAIを作成するためのメイントピックに移りましょう。ライブラリをインストールし、APIキーを設定した後、都市名と人口を列とする単純な都市データフレームを作成します。
import pandas as pd
from llama_index.query_engine.pandas_query_engine import PandasQueryEngine
df = pd.DataFrame(
{"city": ["ニューヨーク", "イスラマバード", "ムンバイ"], "population": [8804190, 1009832, 12478447]}
)
PandasQueryEngineを使用して、データフレームをロードしてインデックスを作成するクエリエンジンを作成します。
その後、クエリを書き、応答を表示します。
query_engine = PandasQueryEngine(df=df)
response = query_engine.query(
"最も人口の少ない都市は何ですか?",
)
表示されているように、データフレームで最も人口の少ない都市を表示するためのPythonコードが開発されました。
> Pandasの指示:
```
eval("df.loc[df['population'].idxmin()]['city']")
```
eval("df.loc[df['population'].idxmin()]['city']")
> Pandasの結果: イスラマバード
応答を表示すると、「イスラマバード」と表示されます。シンプルですが印象的です。自分自身のロジックを考えたり、コードを試行錯誤する必要はありません。質問を入力するだけで答えが得られます。
print(response)
イスラマバード
また、応答のメタデータを使用して結果の背後にあるコードを表示することもできます。
print(response.metadata["pandas_instruction_str"])
eval("df.loc[df['population'].idxmin()]['city']")
グローバルYouTube統計分析
2番目の例では、KaggleからグローバルYouTube統計2023のデータセットを読み込み、いくつかの基本的な分析を行います。これは単純な例からのステップアップです。
データセットをクエリエンジンに読み込むためにread_csvを使用します。その後、欠損値を持つ列と欠損値の数だけを表示するプロンプトを書きます。
df_yt = pd.read_csv("Global YouTube Statistics.csv")
query_engine = PandasQueryEngine(df=df_yt, verbose=True)
response = query_engine.query(
"欠損値を持つ列と欠損値の数をリストアップします。欠損値のみの列を表示します。",
)
> Pandasの指示:
```
df.isnull().sum()[df.isnull().sum() > 0]
```
df.isnull().sum()[df.isnull().sum() > 0]
> Pandasの出力:category 46
Country 122
Abbreviation 122
channel_type 30
video_views_rank 1
country_rank 116
channel_type_rank 33
video_views_for_the_last_30_days 56
subscribers_for_last_30_days 337
created_year 5
created_month 5
created_date 5
Gross tertiary education enrollment (%) 123
Population 123
Unemployment rate 123
Urban_population 123
Latitude 123
Longitude 123
dtype: int64
次に、人気のあるチャンネルの種類に関する直接の質問をします。個人的には、LlamdaIndexクエリエンジンは非常に正確であり、まだ幻覚を引き起こしていません。
response = query_engine.query(
"最もビュー数の多いチャンネルの種類は何ですか。",
)
> Pandasの指示:
```
eval("df.groupby('channel_type')['video views'].sum().idxmax()")
```
eval("df.groupby('channel_type')['video views'].sum().idxmax()")
> Pandasの出力:エンターテイメント
エンターテイメント
最後に、バーチャートを可視化するように要求し、結果は素晴らしいです。
response = query_engine.query(
"上位10のYouTubeチャンネルをサブスクライバー数に基づいてバーチャートで可視化し、タイトルを追加します。",
)
> Pandasの指示:
```
eval("df.nlargest(10, 'subscribers')[['Youtuber', 'subscribers']].plot(kind='bar', x='Youtuber', y='subscribers', title='Top Ten YouTube Channels Based on Subscribers')")
```
eval("df.nlargest(10, 'subscribers')[['Youtuber', 'subscribers']].plot(kind='bar', x='Youtuber', y='subscribers', title='Top Ten YouTube Channels Based on Subscribers')")
> Pandasの出力:AxesSubplot(0.125,0.11;0.775x0.77)
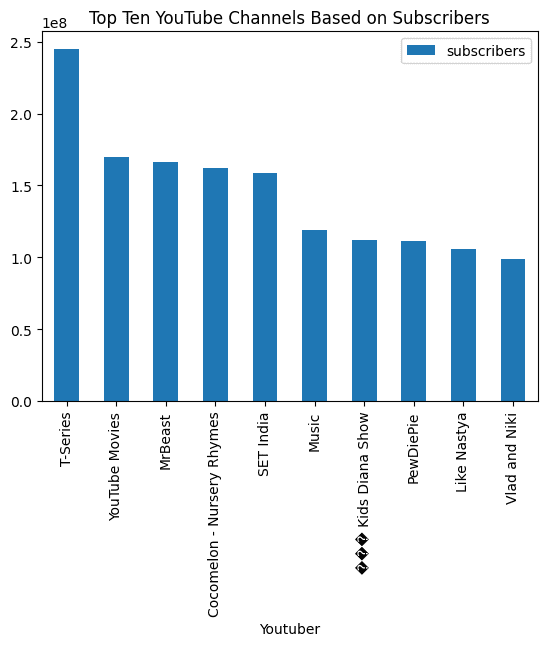
シンプルなプロンプトとクエリエンジンを使用することで、データ分析を自動化し、複雑なタスクを実行することができます。LamaIndexにはまだまだたくさんの機能があります。公式ドキュメントを読んで素晴らしいものを作ってみることを強くお勧めします。
結論
要約すると、LlamaIndexは開発者が独自のPandasAIを作成できる、大規模言語モデルの力を借りた直感的なデータ分析と会話のためのエキサイティングな新しいツールです。LlamaIndexでデータセットをインデックス化して埋め込むことにより、セキュリティを損なうことなくプライベートデータ上で高度な自然言語機能を可能にすることができます。
これは始まりに過ぎません。LlamaIndexを使用すると、ドキュメント上にQ&Aを構築したり、チャットボットや自動化AI、ナレッジグラフ、AI SQLクエリエンジン、フルスタックのWebアプリケーションを構築したり、プライベートな生成AIアプリケーションを構築したりすることができます。Abid Ali Awan(@1abidaliawan)は、機械学習モデルの構築が大好きな認定データサイエンティストです。現在はコンテンツ作成や機械学習やデータサイエンス技術に関する技術ブログの執筆に注力しています。Abidはテクノロジーマネジメントの修士号と通信工学の学士号を保持しています。彼のビジョンは、メンタルヘルスの問題を抱える学生向けにグラフニューラルネットワークを使用したAI製品を構築することです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






