ユーザーフィードバック – MLモニタリングスタックの欠けている部分
ユーザーフィードバック - MLモニタリングスタックの欠けている部分' can be condensed to 'ユーザーフィードバック - MLモニタリングスタックの欠点
ユーザー中心のAIの完全ガイド
AIモデルとユーザーの不一致
AIモデルを実装するために数ヶ月間、そしていくらお金を使っても、誰もそれを使わないことがありますか?採用の課題を乗り越えても、ユーザーの意思決定やクエリ、プロフェッショナルまたは日常の活動に価値を追加しているかどうかをどのように知ることができますか?
機械学習のパフォーマンスメトリクスやリアルタイムモニタリングツールは、モデルのパフォーマンスを計算するための優れた方法であり、技術的な観点から何かがうまくいかないときに特定することができます。しかし、ユーザーの関与や満足度を理解せずには、モデルが意図した目的で使用されているかどうかはわかりにくいです。
さらに、AIモデルのユーザーに耳を傾けることで、正しく予測されなかったエッジケースが明らかになる場合があります。また、私たちが期待したように説明しきれない説明アルゴリズムや、ユーザーがモデルとの関わり方に影響を与えるユーザーエクスペリエンスの欠陥があるかもしれません。
この記事の残りの部分では、AIモデルに対するユーザーフィードバックの重要性、さまざまなタイプのユーザーフィードバック、およびユーザーフィードバックを収集してモデルのパフォーマンスを改善し、ユーザーの採用を増やし、最終的にAIモデルをユーザーに合わせる方法について説明します。
目次
- AIモデルとユーザーの不一致
- AIにおけるユーザーフィードバックとは何か?
- なぜAIにおけるユーザーフィードバックが重要なのか?
- 異なるフィードバックのタイプとは?
- ユーザーフィードバックの収集ガイド
- まとめ
AIにおけるユーザーフィードバックとは何か?
ユーザーフィードバックとは、実装しているユースケースに応じて異なるユーザーを指します。たとえば、これは内部のビジネスユーザーや内部のMLベースの需要予測アプリケーションの利害関係者である場合もあります。また、医療腫瘍の検出に役立つMedTech製品を利用する医療腫瘍学者などの外部のドメインエキスパートである場合もあります。さらに、ジェネレーティブAIを利用して履歴書の作成や修正を支援する外部の求人アプリケーションアシスタントの最終ユーザーである場合もあります。
この記事で説明されている概念、方法、および利点は、これらのさまざまなユースケースに適用されます。ただし、ユースケースによっては、利点がより適用される場合や適用されない場合もありますので、ケースバイケースで考慮する必要があります。
この記事では、上記で説明した履歴書アシスタントを使用して、ユーザーフィードバックの利点を示します。
ユーザーフィードバックとは、間違った予測の再ラベリングや自動モデル再トレーニングのフィードバックループだけでなく、AIアプリケーションの有用性と採用状況を理解するためにユーザーが提供する情報を意味します。履歴書アシスタントの例では、ユーザーフィードバックにはユーザー満足度のスコアや生成された履歴書の満足度に関する洞察、また特定の問題を強調するためのコメントなどが含まれる可能性があります。
このようなフィードバックは、必ずしも自動再トレーニングパイプラインに直接プッシュするべきではありません。なぜなら、
- ユーザーフィードバックは通常、構造化されていないため、間違った予測の外の問題を強調し、そのフィードバックを直接的にモデルの再トレーニングに使用することはできない場合があるからです。たとえば、履歴書アシスタントが過度に形式的な言語を使用しているとユーザーが強調した場合、このフィードバックを直接使用せずに、トレーニングデータにより形式的でないテキストの例を追加する必要があるかもしれません。
- 正しい/間違った予測に焦点を当てることで、ユーザーが提供する貴重な情報が見落とされることがあります。ユーザーフィードバックを理解することで、AIチームはユーザーの経験と使用パターンに基づいてアプリケーションを改善することができます。
- 人間のフィードバックを用いた強化学習などのトレーニング戦略は、制御された環境内では非常にうまく機能します。しかし、現実世界のユーザーフィードバックはノイズが多く、潜在的に有害な場合があります。たとえば、ユーザーフィードバックを盲目的にトレーニングデータに組み込むと、悪意のあるユーザーがモデルを意図的に誤誘導するデータポイズニングが発生する可能性があります。
したがって、AIチームはユーザーフィードバックを見直し、異なる洞察を抽出して全体的なAIアプリケーションを改善するための次の最善の手段を決定する必要があります。
なぜAIにおけるユーザーフィードバックが重要なのか?
モデルの評価を可能にする
多くのAIモデルは基準の真実を欠いています。これにより、テストデータセットでの評価が困難になります。通常、これは通常ストーリーの一部しか伝えないプロキシメトリックスに基づいています。特にジェネレーティブモデルの場合、ユーザーがモデルの予測に満足しているかどうかを理解することが最も重要なメトリックスです。
モデルのパフォーマンス向上:
ユーザーフィードバックは、AIモデルのパフォーマンスを継続的に向上させるために利用することができます。ユーザーは、頑健なモデルを構築するために必要な優れたドメイン知識を持つ場合があります。さらに、ユーザーエンゲージメントのモニタリングにより、モデルのパフォーマンスが実世界の不良な表現によって低下している場合を特定するのに役立ちます。
ユーザーアライメントの向上:
ユーザーフィードバックは、モデルのうまく機能する面と摩擦を引き起こす要因を明らかにします。これにより、AIチームはユーザーエクスペリエンスを向上させ、モデルを直感的でユーザーフレンドリーにします。さらに、AIチームはモデルをすべてのユーザーに合わせることができます。たとえば、履歴書アシスタントが英語だけでなく、すべての言語で品質を維持するようにします。
ユーザーが自分の声が届いていると感じると、AIモデルを信頼し、関与し続ける可能性が高まり、ユーザーアライメントと採用が増加します。
AIの責任の向上:
ユーザーフィードバックを通じて、AIチームは安全性、バイアス、その他の倫理的な考慮事項に関連する懸念を特定し、対処することができます。この積極的なアプローチにより、より安全で責任あるAIモデルの開発が実現します。ユーザーフィードバックを求めて応答することで、AIチームは高品質で信頼性のあるAIソリューションの作成に対する責任と取り組みを示します。フィードバックによって、追加の教育資料やドキュメントが必要であることも明らかになる場合があります。これにより、ユーザーがモデルの能力を明確に理解し、ベストプラクティスを促進できるようにします。
要約すると、ユーザーの洞察を活用することで、AIチームはモデルを改善し、ユーザーエクスペリエンスを最適化し、倫理的な懸念を解決し、ユーザーの満足度と信頼性を向上させることができます。
ユーザーフィードバックの意味と利点を明確にしたところで、さまざまなフィードバックの種類とその使用方法について説明しましょう。
さまざまなフィードバックの種類は何ですか?
ユーザーフィードバックには、明示的なフィードバックと暗黙的なフィードバックの2つの主要なカテゴリがあります。これは、私たちの新しい親友であるChatGPT(以下の画像で説明されています)によってうまく説明されています。
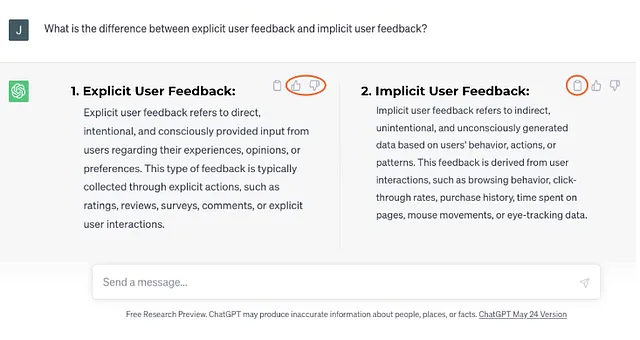
明示的なユーザーフィードバックは、ユーザーが意図的に提供する直接の入力であり、経験、意見、または好みに関するものです。ChatGPTのインターフェースで見たように、トンプスアップ/ダウンのフィードバックは明示的なフィードバックの一例です。
明示的なフィードバックは、さらに数量的フィードバックと質的フィードバックに分けることができます。数量的フィードバックには、トンプスアップ/ダウン、ユーザー満足度(5点リカートスケールとも呼ばれる)などの測定可能なスケール、またはユーザーの理解を理解するために最適なカスタムスケールなどが含まれます。
質的フィードバックは通常、テキストボックスを使用してユーザーが書面でフィードバックを提供できるようにするものです。数量的な尺度と質的なフィードバックを組み合わせることで、AIチームはユーザーのコメントの背後の「なぜ」を理解し、AIのバグ、ドメイン知識、ユーザーの好みなどの詳細を明らかにすることができます。
暗黙的なユーザーフィードバックは、ユーザーの行動、行動、またはパターンに基づいて間接的で意図しないデータを提供することを指します。ChatGPTのUIを再度見ると、「クリップボードにコピー」ボタンは、OpenAIが暗黙的なフィードバックを収集する方法の一例です。履歴書アシスタントの例では、ユーザーが生成された出力に行った編集を追跡することで、暗黙的なユーザーフィードバックも収集できます。
フィードバックの種類を選択する際には考慮が必要です。明示的なフィードバックは、ユーザーのフィードバックと意見をより明確に理解することができます。ただし、外部のユースケースでは、エンドユーザーが常に明示的なフィードバックを提供しない場合があります(利益を受ける方法を理解していない、または時間がないと感じるかもしれません)。この場合、暗黙的なフィードバックも、ユーザーが直接的なアクションを起こさなくても、AIアプリケーションの使用方法を理解するのに役立ちます。
アプリケーションと現在の課題に基づいて、実装する対策を検討する必要もあります。たとえば、モデルのパフォーマンス向上に重点を置いている場合は、トンプスアップ/ダウンの評価とコメントを使用してモデルの問題を特定することができます。ただし、採用を増やすことに重点を置いている場合は、ユーザー満足度スコアの方が適しているかもしれません。
ユーザーフィードバックの収集ガイド
このセクションでは、ユーザーフィードバックの収集とユーザーの洞察をMLモニタリングシステムに統合するための4つの主要なステップを説明します(以下に示すように)。
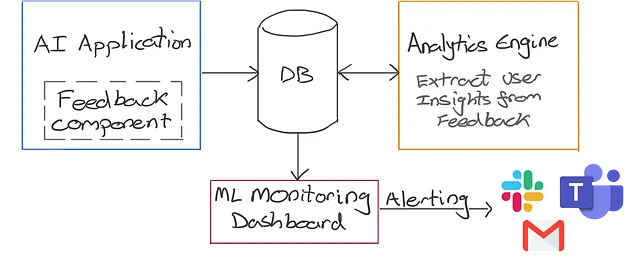
ステップ1:AIアプリ内でフィードバックコンポーネントを設計・構築する
ユーザーフィードバックの収集の目標を定義した後、要件に最も適したフィードバックの種類を決定することができます。ユーザーフィードバックは通常、モデルの出力が生成された後に実装されます。ただし、アプリケーションの特定の機能に対するフィードバックを得るために、アプリケーション全体でフィードバックを収集することもあります。
フィードバックコンポーネントを通じて提出されるすべてのフィードバックとともに、AIモデルのメタデータもキャプチャする必要があります。これには、モデルのバージョン、プロンプトまたはリクエスト、モデルの出力、およびユーザーのデモグラフィック情報(ユーザーIDや場所など)などが含まれます。
ステップ2:ユーザーフィードバックを理解するための分析機能を開発する
定量的なフィードバックの場合、ユーザー満足度(CSAT/NPS)や時間経過による平均的なポジティブ/ネガティブな応答などのプロットが含まれる場合があります。これらのメトリックを異なるモデルバージョン、ユーザー、または他のメタデータに対して比較する機能も必要です。
定性的なフィードバックの場合、MLを使用してユーザーコメントの感情を分析し、フィードバックをさまざまなカテゴリに分類します。これにより、コメントのさまざまなカテゴリにおける異なる感情/満足度メトリックを監視することができます。
ステップ3:AIの問題を特定する
分析機能を使用して、フィードバックでの再発するトピックやテーマを特定し、改善のための領域を分類することができます。その後、AIの問題を特定し、AIチームが解決するための最良の手段を決定します。
AIチームの役割は、モデルの問題だけでなく、ユーザーの問題も特定し、それらを解決するための最良の手段を決定することです。
ユーザーフィードバック内でAIチームが見つける可能性のある洞察の種類については、「AIにおけるユーザーフィードバックとは何ですか?」セクションを参照してください。
ステップ4:ユーザーフィードバックをMLモニタリングシステムに統合する
ユーザーフィードバックを現在のMLモニタリングシステムに統合することで、パフォーマンスモニタリングやドリフト検出と同様のアラート設定が可能になります。たとえば、グローバルなユーザー満足度のスコアがある閾値以下に低下した場合、アラートがトリガーされてAIチームに対して対策を取るように通知することができます。
さらに、ユーザーフィードバックの概要や日報をAIチームや関係者に送信することで、ユーザーフィードバックの概要を提供することもできます。
まとめ
要約すると、ユーザーフィードバックにより、AIチームはバグを特定し、モデルを微調整し、ユーザーに合わせることができます。
上記のことは、MLモニタリングシステムでも実現できます。ただし、ユーザーの視点からモデルを評価することで、従来のMLモニタリングシステムでは見逃されていた情報を特定することができます。
この記事がお役に立ち、AIアプリケーションのユーザーにリスニングし、向上させるための初期のアイデアを提供できれば幸いです。
AIに関するユーザーフィードバックの詳細を学びたい場合や、このトピックについて意見を共有・議論したい場合は、お気軽にLinkedInまたはメールでご連絡ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
