あなたのモデルは良いですか?Amazon SageMaker Canvasの高度なメトリクスについての詳細な調査
モデルの評価:Amazon SageMaker Canvasのメトリクス調査
もしビジネスアナリストであれば、顧客の行動を理解することはおそらく最も重要なことの一つでしょう。顧客の購買意思決定の背後にある理由やメカニズムを理解することは、収益成長を促進することができます。しかし、顧客の喪失(一般的には顧客離反と呼ばれる)は常にリスクを伴います。顧客が去る理由を洞察することは、利益と収益を維持するために同じくらい重要です。
機械学習(ML)は貴重なインサイトを提供できますが、MLの専門家が顧客離反予測モデルを構築する必要がありましたが、Amazon SageMaker Canvasの導入によりそれが可能になりました。
SageMaker Canvasは、コードを一行も書かずに多くのビジネス問題を解決することができるMLモデルを作成できる、ローコード/ノーコードのマネージドサービスです。また、データサイエンティストのように高度なメトリクスを使用してモデルを評価することも可能です。
この記事では、SageMaker Canvasで作成された分類離反モデルをビジネスアナリストが評価し理解する方法を高度なメトリクスタブを使用して示します。メトリクスの説明と、データを処理してより良いモデルのパフォーマンスを得るためのテクニックも紹介します。
- 「Amazon SageMakerを使用して、薬剤探索を加速するためのタンパク質折り畳みワークフローを構築する」
- 「米国は、アメリカの軍事作戦を妨害する可能性のある中国のマルウェアを追跡しています」
- 「私たちが恐れていたロボットは既にここにいる」
前提条件
この記事で説明されているタスクの全てまたは一部を実装するには、SageMaker CanvasにアクセスできるAWSアカウントが必要です。SageMaker Canvas、離反モデル、およびデータセットに関する基本事項については、Amazon SageMaker Canvasを使用したノーコード機械学習による顧客離反の予測を参照してください。
モデルのパフォーマンス評価の概要
モデルのパフォーマンスを評価する必要がある場合、新しいデータを見たときにモデルが何をどれくらい正確に予測するかを測定しようとしています。この予測を推論と呼びます。既存のデータを使用してモデルをトレーニングし、モデルに既に見たことのないデータの結果を予測するように求めます。モデルがこの結果をどれだけ正確に予測するかが、モデルのパフォーマンスを理解するための指標です。
モデルが新しいデータを見ていない場合、予測が良いか悪いかを誰が知ることができるでしょうか?実際には、結果が既にわかっている過去のデータを使用して、予測値をモデルの予測値と比較することができます。これは、モデルがこれらの値に対して予測した結果を、訓練データの一部を予測値と比較するために確保することによって実現されます。
顧客離反の例(これはカテゴリ分類問題です)では、顧客の属性(レコードごとに1つ)を持つ過去のデータセットから始めます。Churnと呼ばれる属性の1つはTrueまたはFalseになり、顧客がサービスを離れたかどうかを説明します。モデルの正確性を評価するために、このデータセットを分割し、一部(トレーニングデータセット)を使用してモデルをトレーニングし、もう一部(テストデータセット)を使用して結果を予測します(顧客をChurnまたは非Churnとして分類します)。その後、モデルの予測値をテストデータセットに含まれる正解と比較します。
高度なメトリクスの解釈
このセクションでは、SageMaker Canvasの高度なメトリクスについて説明し、モデルのパフォーマンスを理解するのに役立ちます。
混同行列
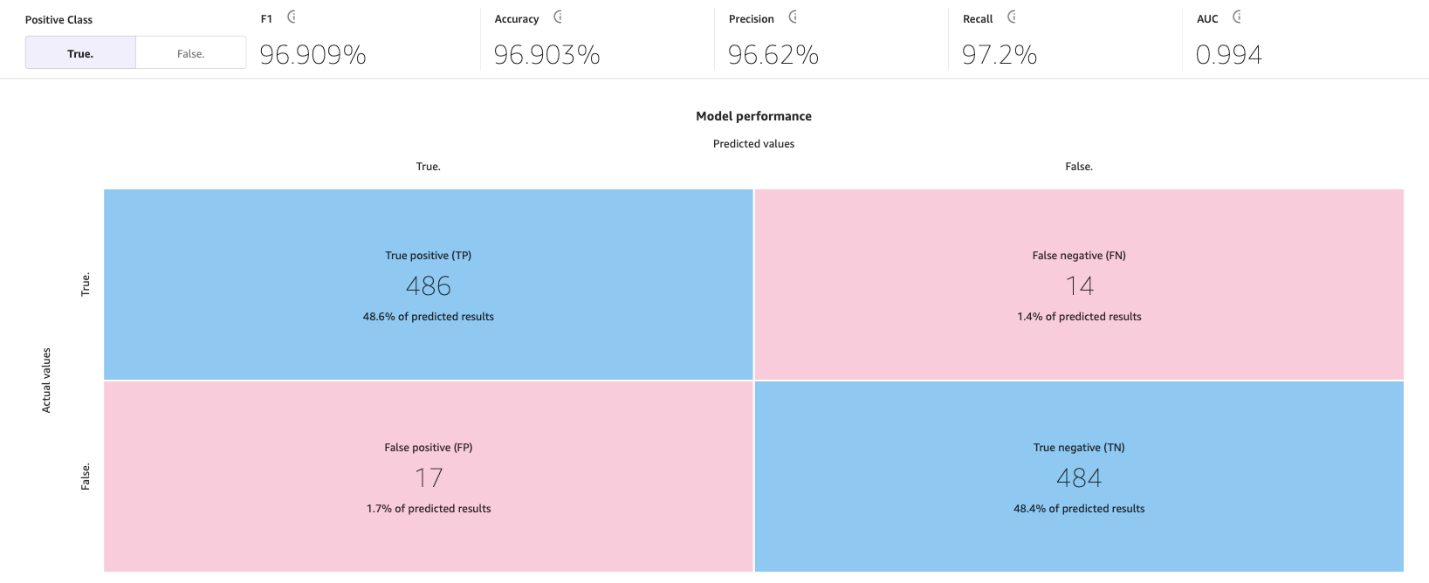
SageMaker Canvasでは、混同行列を使用してモデルが予測を正しく生成する場合を視覚化するのに役立ちます。混同行列では、予測値と実際の履歴(既知の)値を比較するために結果が配置されます。以下の例は、正と負のラベルを予測する二つのカテゴリ予測モデルに対して混同行列がどのように機能するかを説明しています:
- 真陽性 – 真のラベルが正の場合にモデルが正しく正と予測した
- 真陰性 – 真のラベルが負の場合にモデルが正しく負と予測した
- 偽陽性 – 真のラベルが負の場合にモデルが誤って正と予測した
- 偽陰性 – 真のラベルが正の場合にモデルが誤って負と予測した
以下の画像は、二つのカテゴリに対する混同行列の例です。私たちの離反モデルでは、実際の値はテストデータセットから取得し、予測値はモデルに尋ねて取得します。
正確性
正確性は、テストセットのすべての行またはサンプルの中で正しく予測された予測の割合です。真のサンプルはTrueと予測されたものと、Falseと正しく予測された偽のサンプルの合計数で割ったものです。
それは最も重要なメトリックの1つであり、モデルが正しく予測した割合を示していますが、いくつかの場合には誤解を招くことがあります。例えば:
- クラスの偏り – データセットのクラスが均等に分布していない場合(1つのクラスのサンプル数が他のクラスよりも非比例に多く、他のクラスのサンプル数が非常に少ない場合)、正確性は誤解を招く可能性があります。このような場合、すべてのインスタンスに対して単に多数のクラスを予測するモデルでも高い正確性を達成することができます。
- コストに敏感な分類 – 一部のアプリケーションでは、異なるクラスの誤分類のコストが異なる場合があります。例えば、特定の薬が状態を悪化させるかどうかを予測する場合、偽陰性(例えば、実際には薬が悪化させる可能性があるのに、薬が悪化させないと予測する)は偽陽性(例えば、実際には薬が悪化させない可能性があるのに、薬が悪化させると予測する)よりもコストが高い場合があります。
適合率、再現率、およびF1スコア
適合率は、すべての予測陽性(TP + FP)のうち真陽性(TP)の割合です。これは実際に正しい予測となる陽性予測の割合を測定します。
再現率は、すべての実際の陽性(TP + FN)のうち真陽性(TP)の割合です。これはモデルによって正しく陽性と予測された陽性インスタンスの割合を測定します。
F1スコアは、適合率と再現率を組み合わせて、両者のトレードオフをバランスする単一のスコアを提供します。F1スコアは、適合率と再現率の調和平均として定義されます:
F1スコア = 2 * (適合率 * 再現率) / (適合率 + 再現率)
F1スコアは0から1までの範囲であり、より高いスコアはより良いパフォーマンスを示します。完璧なF1スコア1は、モデルが完璧な適合率と完璧な再現率の両方を達成していることを示し、スコア0はモデルの予測が完全に間違っていることを示します。
F1スコアは、モデルのパフォーマンスのバランスの取れた評価を提供します。適合率と再現率を考慮し、陽性インスタンスの正しい分類と偽陽性および偽陰性を回避する能力を反映したより具体的な評価メトリックを提供します。
例えば、医療診断、詐欺検出、感情分析では、特にF1スコアが重要です。医療診断では、特定の疾患や状態の存在を正確に特定することが重要であり、偽陰性や偽陽性が重大な結果をもたらすことがあります。F1スコアは適合率(陽性ケースを正しく識別する能力)と再現率(すべての陽性ケースを見つける能力)の両方を考慮し、疾患の検出能力をバランスの取れた評価として提供します。同様に、詐欺検出では、実際の詐欺ケースの数が非詐欺ケースに比べて比較的低い(クラスの偏り)ため、正確性だけでは誤った結果をもたらす場合があります。F1スコアは、適合率と再現率の両方を考慮し、詐欺と非詐欺の両方のケースを検出するモデルの能力を包括的に評価します。また、感情分析では、データセットが偏っている場合、正確性はポジティブ感情クラスのインスタンスを分類するモデルのパフォーマンスを正確に反映しない場合があります。
AUC(曲線下面積)
AUCメトリックは、2つのクラス間を区別するバイナリ分類モデルの能力を、すべての分類の閾値で評価します。閾値は、モデルが2つの可能なクラスの間での判断を行うために使用する値であり、サンプルがクラスの一部である確率を2つのクラスの間のバイナリ判断に変換します。AUCを計算するために、真陽性率(TPR)と偽陽性率(FPR)をさまざまな閾値設定でプロットします。TPRは、すべての実際の陽性から真陽性の割合を測定し、FPRは、すべての実際の陰性から偽陽性の割合を測定します。結果として得られる曲線は、受信者動作特性(ROC)曲線と呼ばれ、異なる閾値設定でのTPRとFPRの視覚的な表現を提供します。範囲が0から1のAUC値は、ROC曲線の下の面積を表します。より高いAUC値は、より良いパフォーマンスを示し、完璧な分類器はAUC 1を達成します。
次のプロットは、TPRをY軸、FPRをX軸とするROC曲線を示しています。曲線がプロットの左上隅に近づくほど、モデルはデータをカテゴリに分類するのに優れた性能を発揮します。
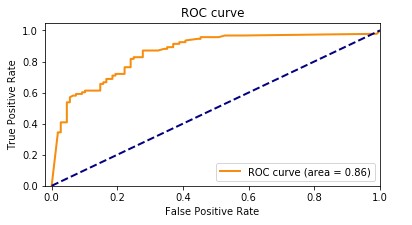
明確にするために、例を見てみましょう。不正検知モデルについて考えてみましょう。通常、これらのモデルは不均衡なデータセットから訓練されます。これは、通常、データセットのほとんどのトランザクションが不正ではなく、ごくわずかなものが不正とラベル付けされているためです。この場合、正確さだけではモデルの性能を適切に評価することができないかもしれません。なぜなら、非不正ケースの豊富さによって正確さスコアが誤解を招くほど高くなる可能性があるからです。
この場合、AUCはモデルの性能を評価するためにより適切な指標です。AUCは、不正と非不正のトランザクションを区別する能力を包括的に評価する指標です。異なる分類の閾値で真陽性率と偽陽性率のトレードオフを考慮に入れた、より微細な評価を提供します。
F1スコアと同様に、データセットが不均衡な場合に特に有用です。TPRとFPRのトレードオフを測定し、両クラスを均等に考慮しながらモデルが2つのクラスを区別できるかどうかを示します。つまり、1つのクラスが他よりも著しく小さくても、ROC曲線は両クラスを同様に考慮することで、モデルの性能をバランスよく評価します。
追加の主要なトピック
高度なメトリックは、MLモデルの性能を評価および改善するために利用できる重要なツールだけではありません。データの準備、特徴量エンジニアリング、および特徴量の影響分析は、モデル構築において重要な技術です。これらの活動は、生データから意味のある洞察を抽出し、モデルの性能を向上させ、堅牢で洞察に富んだ結果を得るために重要な役割を果たします。
データの準備と特徴量エンジニアリング
特徴量エンジニアリングは、生データから変数(特徴量)を選択、変換、および作成するプロセスであり、MLモデルの性能向上に重要な役割を果たします。利用可能なデータから最も関連性の高い変数や特徴量を選択することは、モデルの予測力に寄与しない無関係または冗長な特徴量を削除することを意味します。データの特徴量を適切な形式に変換することには、スケーリング、正規化、欠損値の処理が含まれます。そして最後に、既存のデータから新しい特徴量を作成することは、数学的な変換、異なる特徴量の組み合わせや相互作用、またはドメイン固有の知識からの新しい特徴量の作成を通じて行われます。
特徴量の重要度分析
SageMaker Canvasはデータセットの各列がモデルに及ぼす影響を説明する特徴量の重要度分析を生成します。予測を生成する際に、各予測において最も影響力のある列を示す列の影響度を確認できます。これにより、どの特徴量が最終モデルの一部となる価値があり、どの特徴量が破棄されるべきかについての洞察を得ることができます。列の影響度は、他の列に対して予測における列の重みがどれだけあるかを示すパーセンテージスコアです。25%の列の影響度の場合、Canvasはその列に対して予測を25%、他の列に対して予測を75%と重み付けします。
モデルの精度を改善するアプローチ
モデルの精度を改善するための複数の方法がありますが、データサイエンティストやML実践者は通常、このセクションで説明されたツールとメトリックのいずれかのアプローチを使用します。
モデル中心のアプローチ
このアプローチでは、データは常に同じままであり、望ましい結果を得るためにモデルを反復的に改善するために使用されます。このアプローチで使用されるツールには、以下が含まれます:
- 複数の関連するMLアルゴリズムを試す
- アルゴリズムおよびハイパーパラメータの調整と最適化
- 異なるモデルアンサンブル手法
- 事前にトレーニングされたモデルの使用(SageMakerは、ML実践者をサポートするためにさまざまな組み込みまたは事前にトレーニングされたモデルを提供します)
- Amazon SageMaker Autopilotを使用して、バックグラウンドで行うAutoML(上記のすべてを網羅)
データ中心のアプローチ
このアプローチでは、データの準備、データ品質の向上、およびパフォーマンスの改善のためにデータを反復的に変更することに焦点が当てられます:
- モデルのトレーニングに使用されるデータセットの統計情報の調査(探索的データ分析(EDA)とも呼ばれます)
- データ品質の向上(データクリーニング、欠損値の補完、外れ値の検出と管理)
- 特徴量の選択
- 特徴量エンジニアリング
- データ拡張
Canvasを使用してモデルのパフォーマンスを向上させる
データ中心のアプローチから始めます。モデルプレビュー機能を使用して初期のEDAを実行します。これにより、データ拡張を実行し、新しいベースラインを生成し、最終的なモデルを構築するためのモデル中心のアプローチを使用して最良のモデルを得ることができます。
私たちは、電気通信携帯電話キャリアからの合成データセットを使用しています。このサンプルデータセットには5,000件のレコードが含まれており、各レコードは顧客プロファイルを説明するために21の属性を使用しています。完全な説明については、Amazon SageMaker Canvasを使用したノーコードの機械学習を使用して顧客の離反を予測するを参照してください。
データ中心のアプローチによるモデルのプレビュー
最初のステップとして、データセットを開き、予測する列を「Churn?」として選択し、プレビューモデルを選択してプレビューモデルを生成します。
プレビューモデルパネルでは、プレビューモデルが準備されるまでの進捗状況が表示されます。
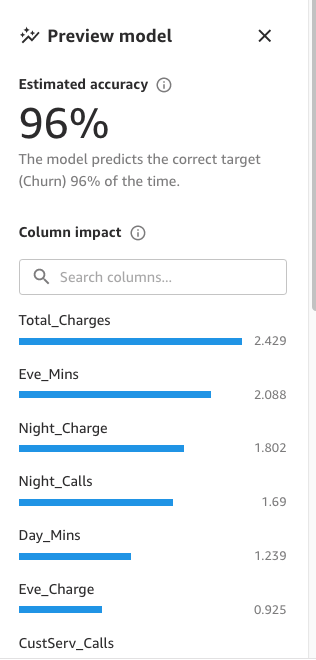
モデルが準備できたら、SageMaker Canvasは特徴の重要度分析を生成します。
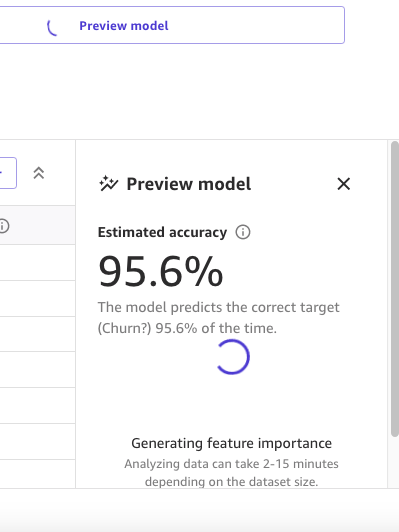
最後に、完了したら、パネルにはモデルへの影響度に基づいた列のリストが表示されます。これらは、特徴が予測にどれだけ関連しているかを理解するのに役立ちます。列の影響度は、他の列と比較して予測における列の重みを示すパーセンテージスコアです。次の例では、「Night Calls」列について、SageMaker Canvasは予測を列に対して4.04%、他の列に対して95.9%の重みを付けます。値が高いほど、影響度も高くなります。
プレビューモデルは95.6%の正確性を持っていることがわかります。データ中心のアプローチを使用してモデルのパフォーマンスを改善してみましょう。データの準備と特徴エンジニアリングの技術を使用してパフォーマンスを向上させます。
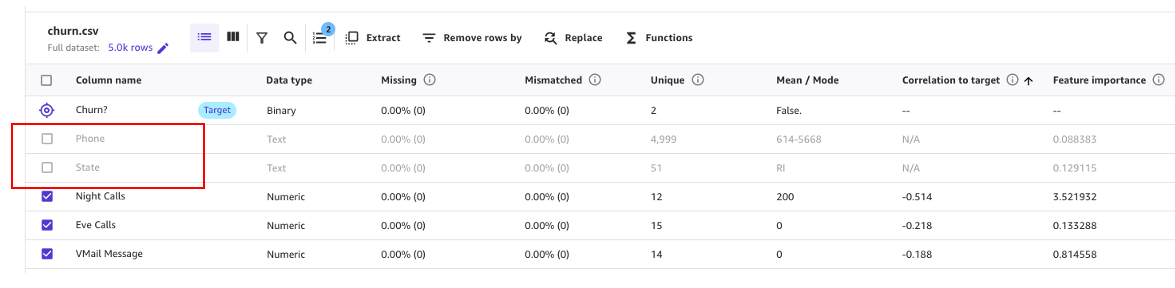
次のスクリーンショットに示すように、PhoneおよびStateの列が予測にほとんど影響を与えていないことがわかります。したがって、この情報を次のフェーズ、データの準備のための入力として使用します。

SageMaker Canvasでは、データのクリーニング、変換、データのモデル構築のための準備を行うためのMLデータ変換が提供されています。これらの変換は、コードなしでデータセットに適用することができ、データの準備が行われたモデルレシピに追加されます。
使用するデータ変換は、モデルの構築時にのみ入力データを変更し、データセットや元のデータソースを変更しませんので、注意してください。
SageMaker Canvasで利用可能な次の変換を使用して、データの準備を行うことができます:
- 日時の抽出
- 列の削除
- 行のフィルタリング
- 関数と演算子
- 行の管理
- 列の名前の変更
- 行の削除
- 値の置換
- 時系列データのリサンプリング
まず、予測にほとんど影響を与えないことがわかった列を削除してみましょう。
たとえば、このデータセットでは、電話番号はアカウント番号と同等のものであり、他のアカウントの離反の可能性を予測するのには無意味であるか、むしろ有害です。同様に、顧客の州もモデルにほとんど影響を与えません。PhoneおよびStateの列をColumn nameの下で選択解除して削除しましょう。
さて、さらなるデータ変換と特徴エンジニアリングを行いましょう。
たとえば、前回の分析でわかったように、顧客への請求金額は離反に直接影響します。したがって、Charge、Mins、Day、Eve、Night、Intlの各要素を組み合わせて顧客への総請求金額を計算する新しい列を作成しましょう。これには、SageMaker Canvasのカスタム式を使用します。
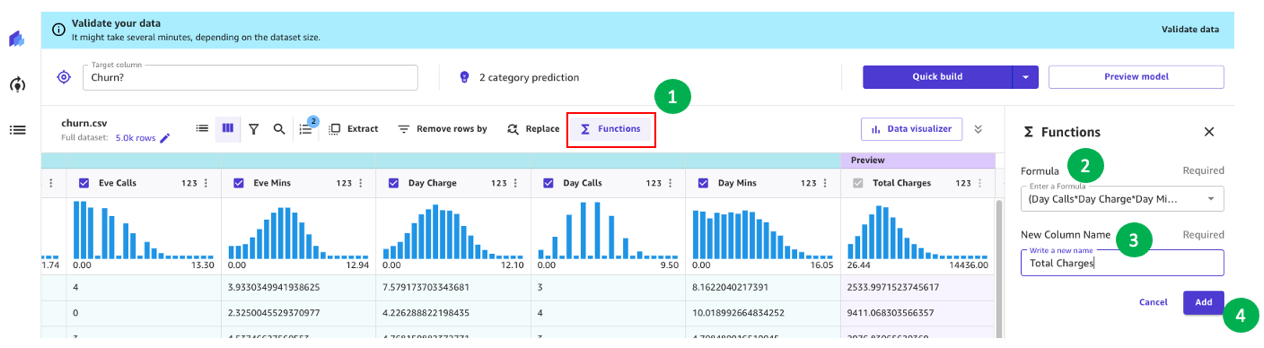
まずは関数を選んで、次に以下のテキストを数式テキストボックスに追加します:
(日の通話数*日の料金*日の通話時間)+(夜の通話数*夜の料金*夜の通話時間)+(国際通話数*国際通話料金*国際通話時間)
新しい列に名前を付け(例えば、総料金とします)、プレビューが生成された後に追加を選択します。モデルのレシピは次のスクリーンショットのように表示されます。
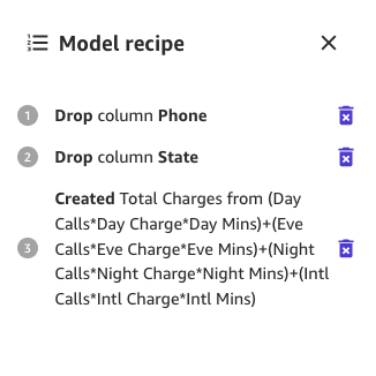
このデータの準備が完了したら、モデルの改善を確認するために新しいプレビューモデルをトレーニングします。再びモデルのプレビューを選択すると、右下のペインに進捗状況が表示されます。

トレーニングが完了すると、予測精度を再計算し、新しい列の影響分析も作成します。
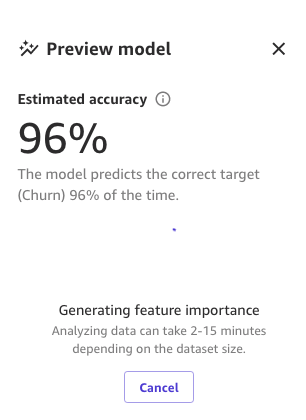
最後に、全プロセスが完了すると、以前に見たのと同じペインが表示されますが、新しいプレビューモデルの精度が表示されます。モデルの精度が0.4%(95.6%から96%)向上していることに注意してください。
前の画像の数値は、MLによってモデルのトレーニングプロセスにいくつかの確率論が導入されるため、異なるビルドで異なる結果が得られる場合があります。
モデル重視のアプローチでモデルを作成する
Canvasでは、2つのモデル作成オプションがあります:
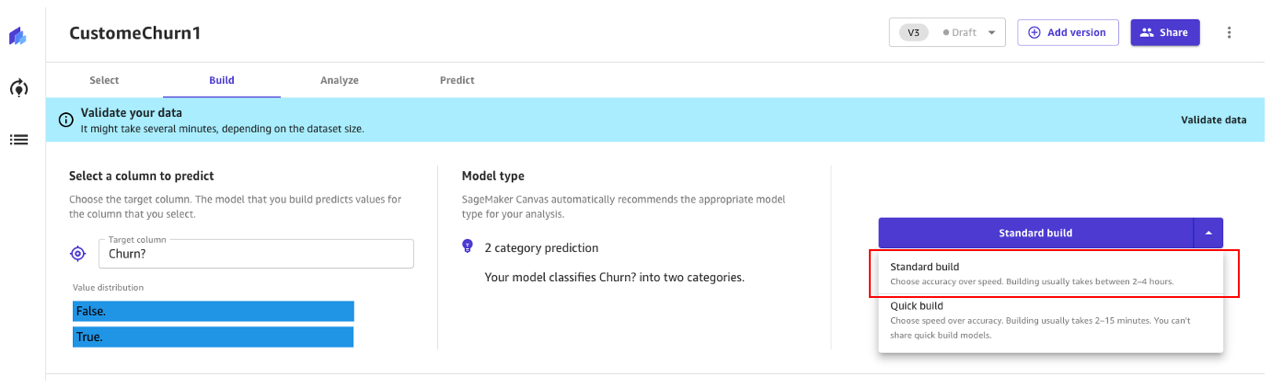
- 標準ビルド – 速度を犠牲にして精度を向上させる最適化プロセスから最適なモデルを構築します。Auto-MLを使用して、モデル選択、MLユースケースに関連するさまざまなアルゴリズムの試行、ハイパーパラメータのチューニング、モデルの説明性レポートの作成など、MLのさまざまなタスクを自動化します。
- クイックビルド – 標準ビルドに比べて簡単なモデルを短時間で構築しますが、精度は速度と引き換えになります。クイックモデルは、モデルの精度にデータの変更が与える影響をより速く理解するために反復する際に便利です。
標準ビルドアプローチを引き続き使用しましょう。
標準ビルド
先ほど見たように、標準ビルドは最適化プロセスから最良のモデルを構築します。
チャーンモデルのビルドプロセスには約45分かかります。この間、Canvasは何百もの候補パイプラインをテストし、最良のモデルを選択します。以下のスクリーンショットでは、予想されるビルド時間と進捗状況が表示されます。
標準ビルドプロセスにより、MLモデルの精度が96.903%に向上しました。これは大幅な改善です。

高度なメトリクスを探索する
「高度なメトリクス」タブを使用してモデルを探索しましょう。「スコアリング」タブで、「高度なメトリクス」を選択してください。

このページでは、以下の混同行列と共に、F1スコア、正解率、適合率、再現率、F1スコア、およびAUCという高度なメトリクスが表示されます。
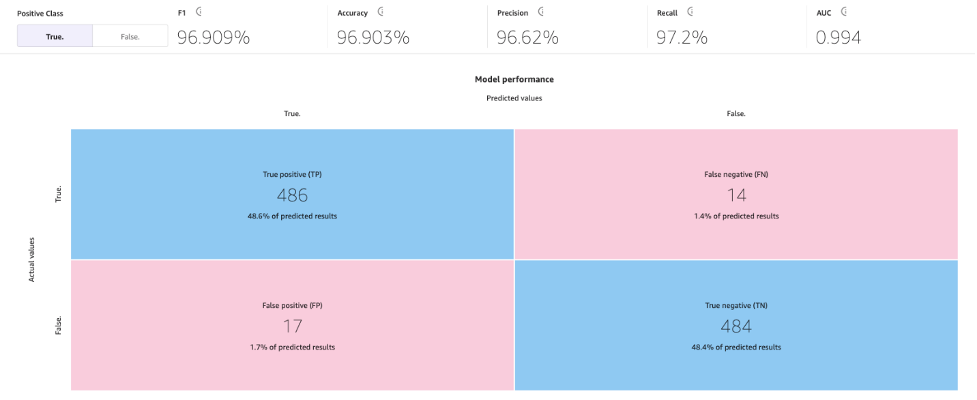
予測を生成する
メトリクスが良好に見えるので、バッチまたはシングル(リアルタイム)の予測を予測タブで実行できます。
2つのオプションがあります:
- このモデルを使用してバッチまたはシングルの予測を実行する
- データサイエンティストと共有するためにモデルをAmazon Sagemaker Studioに送信する
片付け
将来のセッション料金を発生させないために、SageMaker Canvasからログアウトしてください。

結論
SageMaker Canvasは、コーディングや専門的なデータサイエンスや機械学習の知識を必要とせずに、モデルの構築と精度の評価を可能にする強力なツールを提供します。顧客離反モデルの作成を通じて示したように、高度なメトリクスを使用したデータ中心およびモデル中心のアプローチを組み合わせることで、ビジネスアナリストは予測モデルを作成し評価することができます。ビジュアルインターフェースを使用することで、自分自身で正確な機械学習予測を生成することもできます。他の種類の機械学習問題にこれらの概念がどれくらい適用できるかを確認するために、参考文献を参照することをお勧めします。
参考文献
- Amazon SageMaker Canvasを使用したコードレス機械学習による顧客離反の予測
- ビジネスアナリストとデータサイエンティストがコードレスMLとAmazon SageMaker Canvasを使用して迅速な市場投入を実現する方法
- Amazon SageMaker Autopilotで生成されたモデルのカスタマイズと再利用
- Amazon SageMaker Canvas イマージョンデイワークショップ
- AWS Step FunctionsとAmazon SageMaker上のAutoGluonを使用したAutoMLワークフローの管理
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





