モジラのコモンボイスでの音声言語認識 — Part I.
モジラのコモンボイスでの音声言語認識 — Part I.' Condensed モジラのコモンボイスでの音声言語認識 — Part I.
最も困難なAIのタスクの1つは、後続の音声テキスト変換のために話者の言語を識別することです。たとえば、同じ家庭に住んでいて異なる言語を話す人々がガレージのロックやスマートホームシステムなどの同じ音声制御デバイスを使用する場合にこの問題が発生するかもしれません。
この記事シリーズでは、Mozilla Common Voice(MCV)データセットを使用して、話された言語の認識精度を最大化しようとします。具体的には、ドイツ語、英語、スペイン語、フランス語、ロシア語の間を識別するために訓練されたいくつかのニューラルネットワークモデルを比較します。
この最初のパートでは、データの選択、前処理、埋め込みについて説明します。
データの選択
MCVは、112の言語で構成される短いレコード(平均時間=5.3秒)を含む、現在公開されている最大の音声データセットです。
言語識別のタスクでは、ドイツ語、英語、スペイン語、フランス語、ロシア語の5つの言語を選択します。ドイツ語、英語、スペイン語、フランス語では、MCVで「Deutschland Deutsch」、「United States English」、「España」、「Français de France」としてラベル付けされたアクセントのみを考慮します。各言語について、検証済みサンプルの中から成人のレコードのサブセットを選択します。
各言語について、言語ごとに40,000件のトレーニングセット、5,000件のバリデーションセット、5,000件のテストセットを使用しました。客観的な評価を得るために、スピーカー(client_id)が3つのセット間で重複しないようにしました。データを分割する際には、まずテストセットとバリデーションセットを、データが不十分に表現されているスピーカーのレコードから埋め、その後残りのデータをトレーニングセットに割り当てました。これにより、val/testセットのスピーカーの多様性が向上し、一般化エラーのより客観的な推定が可能となりました。また、トレーニングセットで1人のスピーカーが支配しないように、client_idごとのレコードの最大数を2000に制限しました。平均的には、1人のスピーカーごとに26件のレコードがありました。また、女性のレコード数と男性のレコード数が一致するようにしました。最後に、トレーニングセットのレコード数が40,000件を下回る場合は、トレーニングセットをアップサンプリングしました。最終的なカウントの分布は、以下の図に示されています。
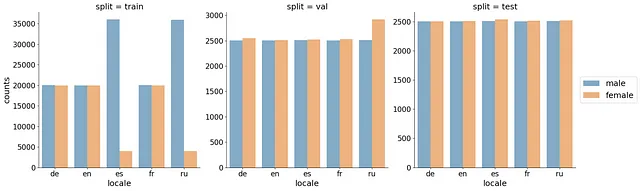
分割を示した結果のデータフレームは、こちらでご覧いただけます。
データの前処理
すべてのMCVオーディオファイルは.mp3形式で提供されています。しかし、.mp3は音楽のコンパクトな保存には適していますが、音声処理ライブラリ(例:pythonのlibrosaなど)では広くサポートされていません。そのため、まずすべてのファイルを.wav形式に変換する必要があります。さらに、元のMCVサンプリングレートは44kHzです。これは、最大エンコード周波数が22kHz(ナイキストの定理による)を意味します。これは、話された言語の識別タスクにとってはオーバーキルです。たとえば、英語では、会話の中でのほとんどの音素は3kHzを超えません。そのため、サンプリングレートを16kHzまで低下させることもできます。これにより、ファイルサイズが削減されるだけでなく、埋め込みの生成が加速されます。
これらの操作は、ffmpegを使用して1つのコマンドで実行することができます:
ffmpeg -y -nostdin -hide_banner -loglevel error -i $input_file.mp3 -ar 16000 $output_file.wav特徴量エンジニアリング
オーディオクリップから関連情報を抽出するためには、埋め込みを計算することが一般的です。音声認識/話された言語認識タスクにおいては、メルスペクトログラム、MFCC、RASTA-PLP、GFCCなどの特徴量が一般的に使用されます。
メルスペクトログラム
メルスペクトログラムに関する原理は、VoAGIで広く議論されています。メルスペクトログラムとMFCCに関する素晴らしいステップバイステップのチュートリアルもこちらで見つけることができます。
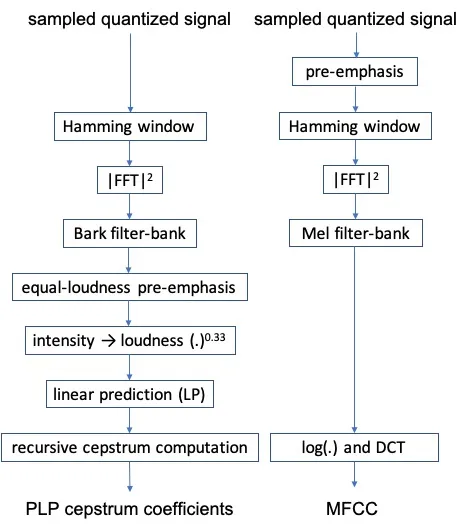
メルスペクトログラムを取得するためには、まず入力信号にプリエンファシスフィルタリングが適用されます。次に、得られた波形に対して連続的に適用されるスライディングウィンドウ上でフーリエ変換が行われます。その後、周波数スケールは人間の知覚に合わせたメルスケールに変換されます。最後に、メルスケール上のパワースペクトルに重なり合う三角フィルタのフィルタバンクが適用され、音の知覚に近づけられます。
MFCC
メル係数は高い相関を持っているため、一部の機械学習アルゴリズムでは望ましくない場合があります(たとえば、ガウス混合モデルでは対角共分散行列がより便利です)。メルフィルタバンクを非相関にするために、メル周波数ケプストラム係数(MFCC)は対数フィルタバンクエネルギーに離散コサイン変換(DCT)を適用して得られます。通常、最初の数個のMFCCのみが使用されます。詳細な手順はこちらに記載されています。
RASTA-PLP
知覚線形予測(PLP)(Hermansky and Hynek, 1990)は、音楽クリップの埋め込みを計算する別の方法です。
PLPとMFCCの違いは、フィルタバンク、等強度プリエンファシス、強度から音量への変換、および線形予測の適用にあります(Hönig et al, 2005)。
PLPは、トレーニングデータとテストデータの間に音響的不一致がある場合に、MFCCよりも堅牢であると報告されています(Woodland et al., 1996)。
PLPに比べて、RASTA-PLP(Hermansky et al., 1991)は、通信チャネルによって導入される線形スペクトルの歪みに対してより堅牢な対数スペクトル領域での追加フィルタリングを行います。
GFCC
ガンマトーン周波数ケプストラム係数(GFCC)は、MFCCに比べてノイズに敏感ではないと報告されています(Zhao, 2012; Shao, 2007)。GFCCは、メルスケールではなく等価の長方形の帯域幅スケールでガンマトーンフィルタを計算し、DCTを計算する前に立方根演算を適用します。
以下の図は、例の信号とその異なる埋め込みを示しています:
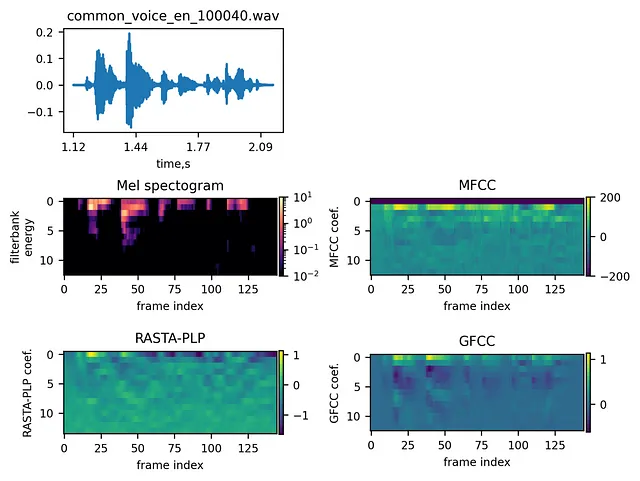
埋め込みの比較
最も効率的な埋め込みを選ぶために、De Andrade et al.(2018)のAttention LSTMネットワークをトレーニングしました。時間の制約のため、ニューラルネットワークは5,000クリップのみでトレーニングされました。
以下の図は、すべての埋め込みに対する検証精度を比較しています。
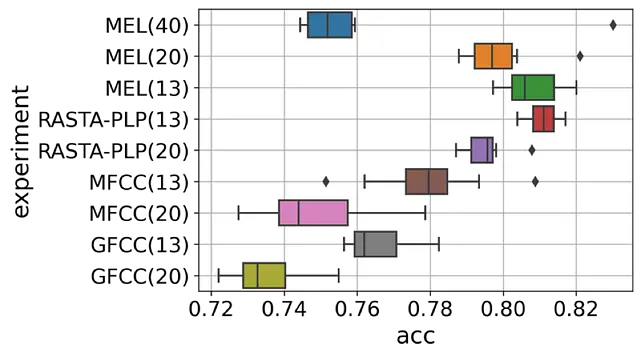
したがって、最初の13個のフィルタバンクを持つメルスペクトログラムは、model_order=13のRASTA-PLPとほぼ同等の性能を発揮します。
興味深いことに、メルスペクトログラムはMFCCよりも優れた性能を発揮します。これは、メルスペクトログラムがニューラルネットワーク分類器にとってより良い選択肢であるという以前の主張(こちらとこちら)と一致しています。
もう一つの観察結果は、係数の数が増えるほど性能が低下する傾向があることです。これは、高次の係数がしばしば話者関連の特徴を表し、異なる話者が選択されるテストセットには一般化できないため、過学習の結果として起こる可能性があります。
時間の制約のため、埋め込みの組み合わせをテストしていませんが、以前の観察結果では、これらの組み合わせが優れた精度を提供する可能性があるとされています。
メルスペクトログラムはRASTA-PLPよりも計算速度がはるかに速いため、今後の実験ではこれらの埋め込みを使用します。
第II部では、複数のニューラルネットワークモデルを実行し、最も言語を分類するモデルを選択します。
参考文献
- De Andrade, Douglas Coimbra, et al. “A neural attention model for speech command recognition.” arXiv preprint arXiv:1808.08929 (2018).
- Hermansky, Hynek. “Perceptual linear predictive (PLP) analysis of speech.” the Journal of the Acoustical Society of America 87.4 (1990): 1738–1752.
- Hönig, Florian, et al. “Revising perceptual linear prediction (PLP).” Ninth European Conference on Speech Communication and Technology. 2005.
- Hermansky, Hynek, et al. “RASTA-PLP speech analysis.” Proc. IEEE Int’l Conf. Acoustics, speech and signal processing. Vol. 1. 1991.
- Shao, Yang, Soundararajan Srinivasan, and DeLiang Wang. “Incorporating auditory feature uncertainties in robust speaker identification.” 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07. Vol. 4. IEEE, 2007.
- Woodland, Philip C., Mark John Francis Gales, and David Pye. “Improving environmental robustness in large vocabulary speech recognition.” 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings. Vol. 1. IEEE, 1996.
- Zhao, Xiaojia, Yang Shao, and DeLiang Wang. “CASA-based robust speaker identification.” IEEE Transactions on Audio, Speech, and Language Processing 20.5 (2012): 1608–1616.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「NeRFたちが望むヒーローではないが、NeRFたちに必要なヒーロー:CopyRNeRFは、NeRFの著作権を保護するAIアプローチです」
- 「50以上の最新AIツール(2023年8月)」
- 「作者の正体を暴く:AIか人間か?IBMの革新的なテキスト検出ツールを用いたAIフォレンジックスの出現を探る」
- FHEを用いた暗号化された大規模言語モデルに向けて
- 「機械学習におけるモデルの解釈性においてSHAP値の使用」
- 「AWSとAccelが「ML Elevate 2023」を立ち上げ、インドのAIスタートアップエコシステムを力強く支援」
- 「業界アプリケーションにおける大規模言語モデルを評価するための4つの重要な要素」






