「拡散を支配するための1つの拡散:マルチモーダル画像合成のための事前学習済み拡散モデルの調節」
マルチモーダル画像合成のための事前学習済み拡散モデルの調節


画像生成AIモデルは、ここ数ヶ月でこの領域を席巻しています。おそらく、midjourney、DALL-E、ControlNet、またはStable dDiffusionなどについて聞いたことがあるかもしれません。これらのモデルは、与えられたプロンプトに基づいて写真のようなリアルな画像を生成することができます。与えられたプロンプトがどれほど奇妙であっても、ピカチュウが火星を走り回るのを見たいですか?これらのモデルのいずれかに依頼してみてください。きっと手に入るでしょう。
既存の拡散モデルは、大規模なトレーニングデータに依存しています。大規模と言っても本当に大きいです。たとえば、Stable Diffusion自体は、25億以上の画像キャプションのペアでトレーニングされました。ですので、自宅で独自の拡散モデルをトレーニングする予定がある場合は、計算リソースに関して非常に高額な費用がかかるため、再考することをお勧めします。
一方、既存のモデルは通常、非条件付きまたはテキストプロンプトのような抽象的な形式に基づいています。これは、画像を生成する際に1つの要素のみを考慮に入れることを意味し、セグメンテーションマップなどの外部情報を渡すことはできません。これは、大規模なデータセットに依存していることと組み合わさると、大規模な生成モデルがトレーニングされていないドメインでは、その適用範囲が制限されることを意味します。
この制限を克服するためのアプローチの1つは、特定のドメインに対して事前にトレーニングされたモデルを微調整することです。しかし、これにはモデルのパラメータへのアクセスと、フルモデルの勾配を計算するための膨大な計算リソースが必要です。さらに、フルモデルを微調整すると、その適用範囲と拡張性が制限されるため、新しいフルサイズのモデルが新しいドメインやモダリティの組み合わせごとに必要となります。また、これらのモデルのサイズが大きいため、微調整されたデータの小さなサブセットにすぐにオーバーフィットする傾向があります。
また、選択したモダリティに基づいてモデルをゼロからトレーニングすることも可能です。しかし、これはトレーニングデータの入手可能性によって制限され、モデルをゼロからトレーニングするのは非常に高価です。一方、推論時に事前にトレーニングされたモデルを目的の出力に向かってガイドする試みもあります。これには事前にトレーニングされた分類器やCLIPネットワークからの勾配を使用しますが、このアプローチは推論中に多くの計算を追加するため、モデルのサンプリングを遅くします。
では、非常に高価なプロセスを必要とせずに、既存のモデルを利用して条件を適用することはできないでしょうか?拡散モードを変更する手間のかかる時間のかかるプロセスに入る必要はありませんか?それでも条件を付けることは可能でしょうか?その答えは「はい」であり、それを紹介します。

提案されたアプローチ、多モーダルコンディショニングモジュール(MCM)は、既存の拡散ネットワークに統合できるモジュールです。これは、元の拡散ネットワークの予測を各サンプリングタイムステップで調整するためにトレーニングされた小規模の拡散のようなネットワークを使用します。これにより、生成された画像が提供された条件に従うようになります。
MCMは、元の拡散モデルを何らかの方法でトレーニングする必要はありません。トレーニングは、モジュレーションネットワークに対してのみ行われ、小規模でトレーニングコストがかからないです。このアプローチは計算的に効率的であり、大規模な拡散ネットワークの勾配を計算する必要がないため、拡散ネットワークをゼロからトレーニングするか既存の拡散ネットワークを微調整するよりも少ない計算リソースを必要とします。
さらに、MCMは、トレーニングデータセットが大規模でない場合でも、一般化能力があります。勾配の計算が必要ないため、推論プロセスを遅くすることはありません。唯一の計算オーバーヘッドは、小規模な拡散ネットワークの実行によるものです。
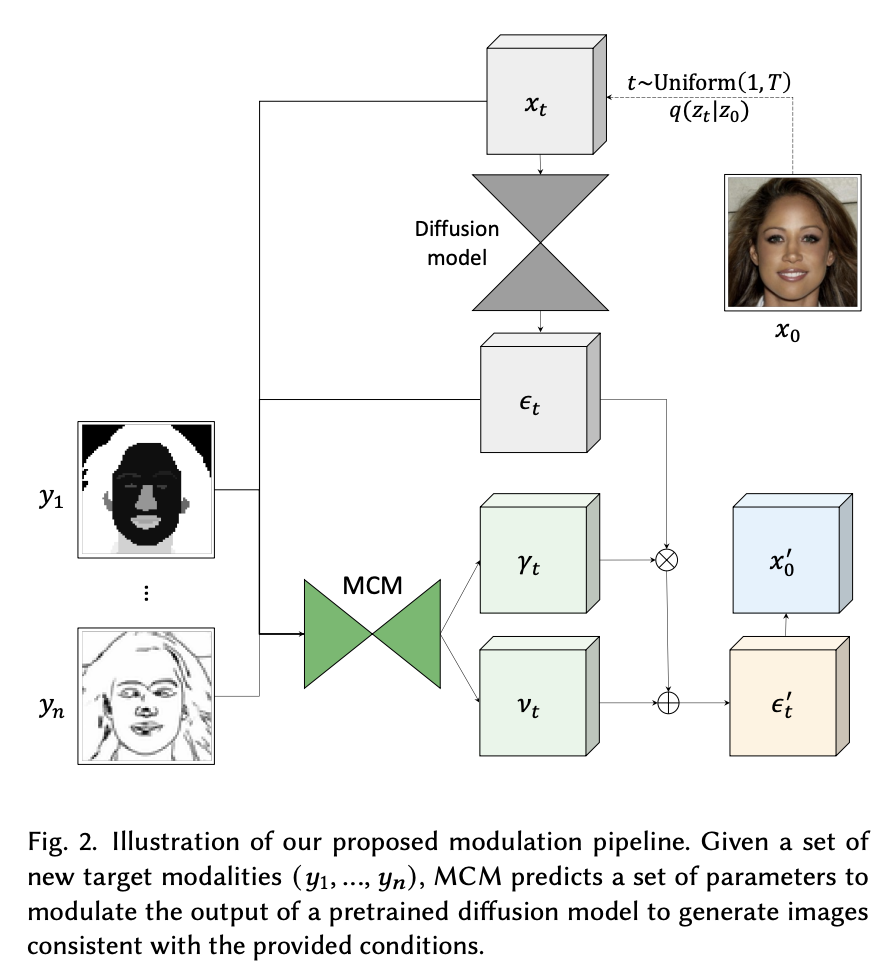
マルチモーダル調整モジュールの組み込みにより、セグメンテーションマップやスケッチなどの追加のモダリティによる条件付き画像生成に対して、より多くの制御が加わります。このアプローチの主な貢献は、マルチモーダル調整モジュールの導入です。これは、元のモデルのパラメータを変更せずに事前学習済みの拡散モデルを条件付き画像合成に適応させるための手法であり、ゼロからのトレーニングや大規模なモデルの微調整よりも安価でメモリ使用量も少なく、高品質かつ多様な結果を実現します。
論文とプロジェクトをチェックしてください。この研究に関しては、このプロジェクトの研究者に全てのクレジットがあります。また、最新のAI研究ニュース、素晴らしいAIプロジェクトなどを共有している26k+のML SubReddit、Discordチャンネル、メールニュースレターにもぜひ参加してください。
Tensorleapの説明可能性プラットフォームでディープラーニングの秘密を解き放つ
この投稿は「One Diffusion to Rule Diffusion: Modulating Pre-trained Diffusion Models for Multimodal Image Synthesis」をMarkTechPostで紹介しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles