マルコフ報酬の表現力について
マルコフ報酬の表現力について
報酬は強化学習(RL)エージェントの駆動力です。RLにおいて中心的な役割を果たすため、報酬は一般的な表現力を持つことが期待されています。これはSuttonとLittmanの報酬仮説によって要約されます:
「…我々が目標と目的を意味するもののすべては、受け取ったスカラー信号(報酬)の累積和の期待値を最大化すると考えることができる」 – SUTTON(2004)、LITTMAN(2017)
私たちの研究では、この仮説の体系的な研究への第一歩を踏み出します。そのために、アリスという設計者とボブという学習エージェントを含む以下の思考実験を考えます:
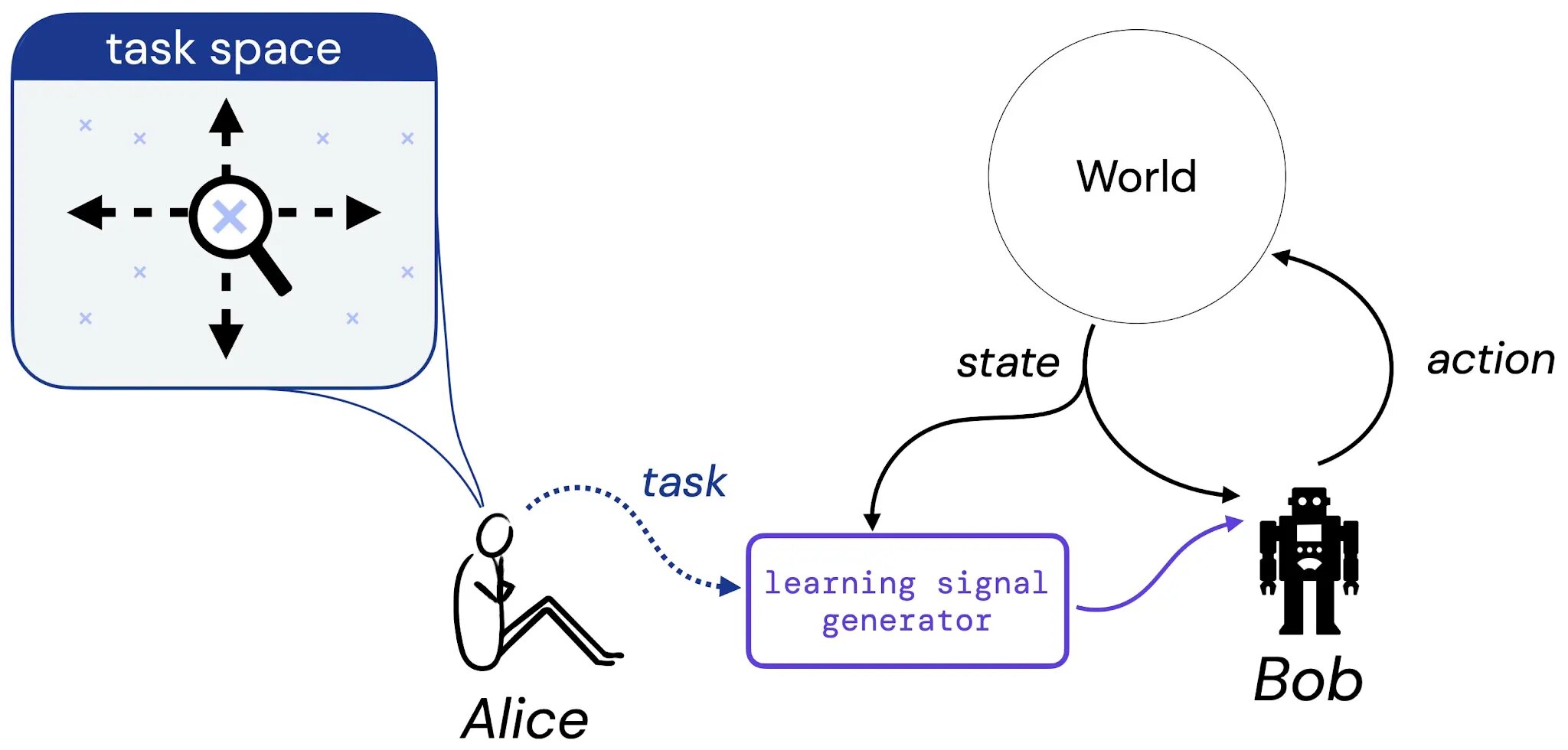
アリスは、ボブに学習して解決してほしいタスクを考えます。このタスクは自然言語の説明(「このポールをバランスさせる」)、想像上の状況(「チェス盤の勝利構成のいずれかに到達する」)などの形式であるか、報酬や価値関数のようなより伝統的なものであるかもしれません。その後、アリスはタスクの選択をいくつかの生成器に翻訳し、ボブ(学習エージェント)に学習信号(報酬など)を提供することができるようにします。そして、報酬仮説の研究を根拠付けるために、以下の問いに取り組みます:アリスのタスクの選択に対して、常にボブに伝えることのできる報酬関数は存在するのでしょうか?
タスクとは何か?
この問いに対する研究を具体化するために、まず私たちは3つの種類のタスクに焦点を絞ります。具体的には、エージェントが学習して解決することを望むタスクの合理的な種類を捉えると考える3つのタスクタイプを紹介します:1)許容可能な方策の集合(SOAP)、2)方策の順序(PO)、および3)軌道の順序(TO)。これらの3つのタスク形式は、エージェントに学習して解決してほしいタスクの具体的なインスタンスを表します。
.jpg)
次に、報酬が有限な環境でこれらのタスクタイプを捉えることができるかどうかを研究します。重要なことは、私たちはマルコフ報酬関数にのみ注目します。たとえば、グリッドワールドの(x,y)のペアのようなタスクを形成するのに十分な状態空間が与えられた場合、この同じ状態空間に依存する報酬関数でそのタスクを捉えることができるでしょうか?
第一の主な結果
私たちの最初の主な結果は、3つのタスクタイプのそれぞれについて、タスクを捉えることができるマルコフ報酬関数が存在しない環境タスクのペアが存在することを示しています。典型的なグリッドワールドでの「グリッドを時計回りまたは反時計回りに一周する」タスクは、そのようなペアの一例です:
.jpg)
このタスクは、青色の「時計回り」方策と紫色の「反時計回り」方策からなるSOAPで自然に捉えられます。このタスクを表現するために、マルコフ報酬関数は他のすべての決定論的な方策よりもこれらの2つの方策を厳密に高い価値にする必要があります。しかし、そのようなマルコフ報酬関数は存在しません:単一の「時計回りに移動する」アクションの最適性は、エージェントが過去にその方向に移動していたかどうかに依存します。報酬関数はマルコフである必要があるため、このような情報を伝えることはできません。同様の例が、マルコフ報酬がすべての方策順序と軌道順序を捉えることができないことを示しています。
第二の主な結果
いくつかのタスクは捉えることができる一方で、いくつかは捉えることができないことがわかったので、次に、与えられた環境で報酬によってタスクが捉えられるかどうかを判定するための効率的な手順が存在するかどうかを探求します。さらに、タスクを捉える報酬関数が存在する場合、そのような報酬関数を出力できることが理想的です。私たちの第二の結果は、任意の有限な環境タスクのペアについて、与えられた環境でマルコフ報酬によってタスクを捉えることができるかどうかを判定する手続きが存在し、また、そのような関数が存在する場合には望ましい報酬関数を出力することができるという肯定的な結果です。
この研究は、報酬仮説の範囲を理解するための初期の道筋を築いていますが、有限な環境、マルコフ報酬、および「タスク」と「表現力」という単純な概念を超えてこれらの結果を一般化するためにはまだ多くの作業が必要です。この研究が報酬とその強化学習における位置について新しい概念的な視点を提供することを願っています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






