「マイクロソフトリサーチがAIコンパイラを1つではなく、2つでもなく、4つも新たに紹介」
マイクロソフトリサーチが4つの新しいAIコンパイラを紹介
新しいコンパイラによって対応されている機能には、並列処理、計算、メモリ、ハードウェアアクセラレーション、および制御フローが含まれます。

私は最近、AIに特化した教育のニュースレターを始めました。すでに16万人以上の購読者がいます。TheSequenceは、5分で読める、ハイプやニュースを排除したML志向のニュースレターです。このニュースレターでは、機械学習のプロジェクト、研究論文、および概念について最新の情報を提供します。以下のリンクからぜひ購読してみてください:
TheSequence | Jesus Rodriguez | Substack
機械学習、人工知能、およびデータの最新動向について最適な情報源です…
thesequence.substack.com
コンパイラは、生成型AIの時代において復活しています。AIの文脈において、コンパイラはニューラルネットワークのアーキテクチャを特定のハードウェアトポロジーに実行可能なコードに変換する責任を持っています。モデルとハードウェアアーキテクチャの両方において、革新が爆発的に進んでおり、AIコンパイラは頻繁に時代遅れになっています。
AIコンパイルにおける課題は多岐にわたり、ハードウェアアクセラレーションから計算およびメモリ効率まで様々なものがあります。マイクロソフトリサーチはAIコンパイラ研究の最前線にあり、最近、ディープニューラルネットワーク(DNN)の領域における特定の課題に対応するための最先端のAIコンパイラの4種類を発表しました。リストは以下のコンパイラを含みます:
- この人工知能(AI)の研究では、SAMを医療用2D画像に適用するための最も包括的な研究である、SAM-Med2Dを提案しています
- このAI研究は、「ComCLIP:組成画像とテキストの整列におけるトレーニングフリーな方法」を公開しています
- 「UCSCとTU Munichの研究者が、余震を予測するための新しいディープラーニングベースのモデルであるRECASTを提案する」
· Rammer:並列処理用
· Roller:計算用
· Welder:メモリ用
· Grinder:制御フローとハードウェアアクセラレーション用
それぞれについて詳しく見ていきましょう。
Rammer:並列ハードウェアの先駆的な利用
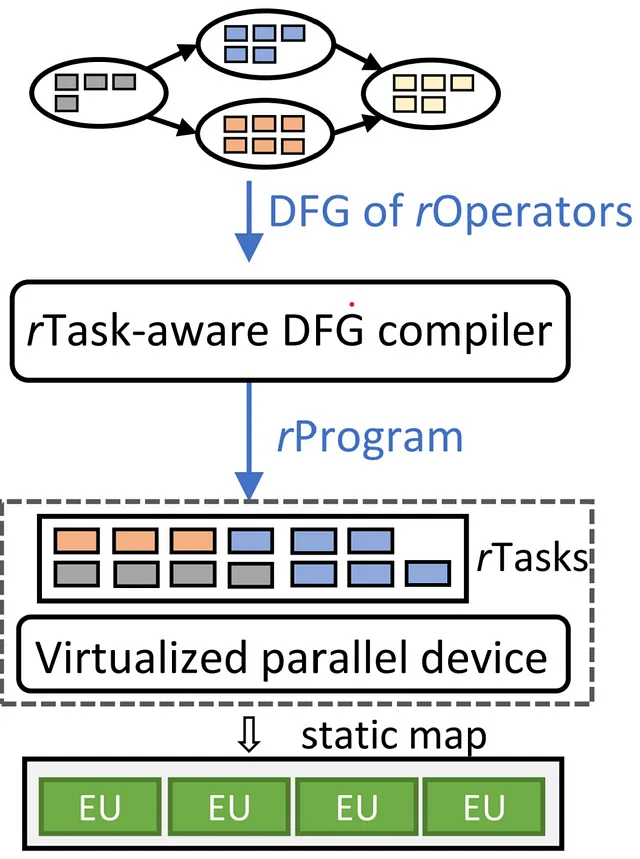
ディープニューラルネットワーク(DNN)は、画像分類から自然言語処理まで、さまざまな知能タスクで重要な役割を果たしています。そのパワーを引き出すために、CPU、GPU、および特殊なDNNアクセラレータなど、さまざまな計算デバイスが使用されています。DNNの計算効率に影響を与える重要な要素は、スケジューリングです。これは、ハードウェア上での計算タスクの実行順序を制御するプロセスです。従来のAIコンパイラでは、DNNの計算を、DNNオペレータを表すノードを持つデータフローグラフとして表現し、それぞれをアクセラレータ上で独立して実行するようにスケジュールします。しかし、この方法ではスケジューリングのオーバーヘッドが大きく、ハードウェアリソースの利用効率が低下します。
Rammerは、スケジューリング空間を二次元の平面と見なすDNNコンパイラです。ここでは、計算タスクはさまざまな形状やサイズのレンガのようなものです。Rammerの使命は、これらのレンガを二次元の平面上でぴったりと配置し、シームレスな壁を構築することです。ハードウェアの利用効率と実行速度を最適化するために、隙間を許容しません。Rammerは、この空間領域内でコンパクターとして効果的に機能し、異なる計算ユニットにDNNプログラムのレンガを効率的に配置することで、ランタイムのスケジューリングオーバーヘッドを軽減します。さらに、Rammerは、計算タスクとハードウェアアクセラレータに対するハードウェア非依存の抽象化を導入し、スケジューリング空間を広げ、より効率的なスケジュールを可能にします。
Roller:計算効率の向上
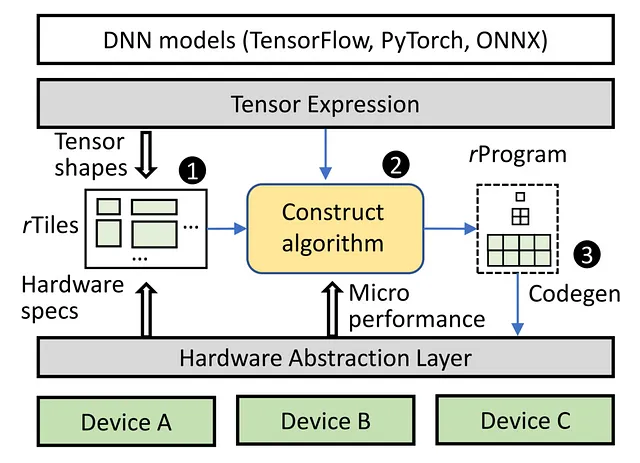
並列計算ユニットと複雑なメモリ階層を持つアクセラレータは、体系的なデータ転送手法を必要とします。データはメモリ層を通過し、各ステップで小さなレンガに分割され、計算のための最上位プロセッサに到達する前に上昇します。課題は、大きなレンガをメモリ空間に分割して埋めることで、メモリの利用効率と効率を最適化することです。現在のアプローチでは、レンガの分割戦略に機械学習を使用しており、アクセラレータで評価される多くの探索ステップが必要です。この長いプロセスには、AIモデル全体をコンパイルするために数日から数週間かかる場合があります。
ローラーは、最適な計算効率を維持しながらコンパイルを迅速化します。ローラーの中核には、ロードローラーの動作に似たユニークなコンセプトがあります。この革新的なシステムは、高次元のテンソルデータを巧みに二次元のメモリ構造に配置します。まるで床を緻密にタイリングするかのようにです。また、特定のメモリ属性に基づいて、理想的なタイルサイズを的確に把握します。同時に、ローラーはテンソルの形状を知的にカプセル化し、基盤となるアクセラレータのハードウェアの微妙なニュアンスに適合させます。この戦略的なアライメントにより、コンパイルプロセスが大幅にスムーズ化され、形状オプションの範囲が制約されるため、非常に効率的な結果が得られます。
Welder: メモリアクセスの効率化
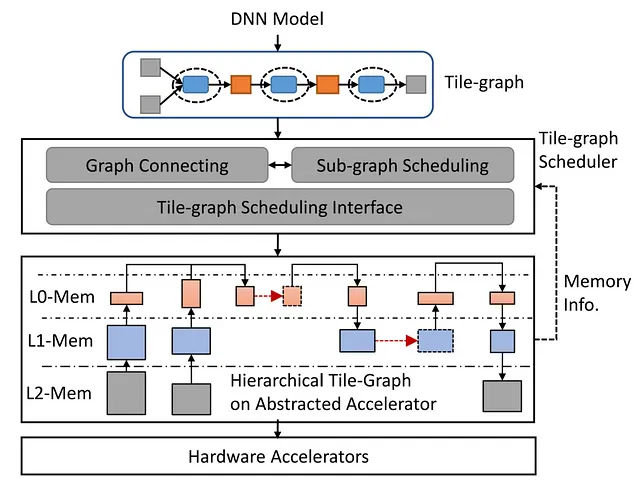
DNNモデルがますます高精度のデータと高速な計算コアを要求する現代のハードウェアアクセラレータでは、メモリ帯域幅のボトルネックが発生しています。これに対処するため、ディープラーニングコンパイラであるWelderは、エンドツーエンドのDNNモデルのメモリアクセス効率を包括的に最適化します。このプロセスでは、入力データが異なるオペレータやメモリレイヤーを通過するブロックに分割されます。Welderは、このプロセスを効率的なアセンブリラインに変換し、異なるオペレータとデータブロックを溶接し、下位レベルのメモリレイヤーでのメモリアクセストラフィックを削減します。
Grinder: 制御フローの効率化
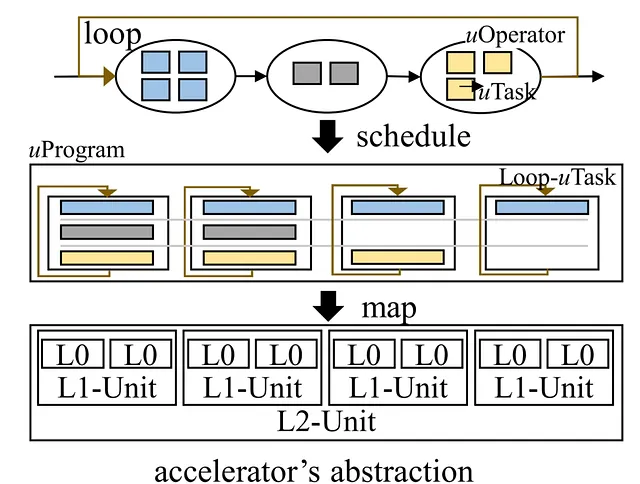
AI計算では、データブロックの移動に複雑な制御ロジックが伴うことがあります。現在のAIコンパイラは、主にデータフローの実行効率に焦点を当てており、制御フローの効率的なサポートを無視しています。Grinderは、制御フローをデータフローにシームレスに統合することで、アクセラレータ上での効率的な実行を可能にします。Grinderは、AIモデルの表現をuTaskという新しい抽象化に統一し、ヒューリスティックな戦略を活用してハードウェアの並列性レベル全体で制御フローの実行を最適化します。Grinderは、効率的に制御フローをデバイスカーネルに移動させることで、制御フローの境界を超えたパフォーマンスの最適化を実現します。
要約すると、Microsoft ResearchのAIコンパイラの四つの要素であるRammer、Roller、Welder、Grinderは、DNNワークロードの最適化、メモリアクセスの効率化、ハードウェアアクセラレータ上での制御フロー実行の向上に向けた道を切り開き、AIコンパイラ技術の大きな飛躍をもたらしています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「ハロー効果:AIがサンゴ礁保護に深く関与する」
- バイトダンスとUCSDの研究者は、与えられたテキストからオブジェクト/シーンのセットのマルチビュー画像を生成することができるマルチビュー拡散モデルを提案しています
- 「リサーチアナリストになるには? 職務内容、必要なスキル、給与」
- マイクロソフトリサーチがAIコンパイラの「ヘビーメタルカルテット」である「Rammer」「Roller」「Welder」「Grinder」をリリースしました
- 韓国の研究者がVITS2を提案:自然さと効率性の向上のためのシングルステージのテキスト読み上げモデルにおける飛躍的な進歩
- このAI研究は、OpenAIの埋め込みを使用した強力なベクトル検索のためのLuceneの統合を提案します
- 「NTUシンガポールの研究者が、3Dポイントクラウドからの正確な人間のポーズと形状の推定のためのAIフレームワークであるPointHPSを提案する」という文です






