「ファインチューニング中に埋め込みのアニメーションを作成する方法」
ファインチューニング中の埋め込みアニメーション作成方法
Cleanlab、PCA、およびProcrustesを使用してCIFAR-10上のViTファインチューニングを視覚化する
機械学習の分野では、Vision Transformers(ViT)は画像分類に使用されるモデルの一種です。従来の畳み込みニューラルネットワークとは異なり、ViTは画像を処理するために元々自然言語処理のタスクに設計されたトランスフォーマーアーキテクチャを使用します。これらのモデルを最適なパフォーマンスでファインチューニングすることは複雑なプロセスです。
以前の記事では、埋め込みのファインチューニングプロセス中の変化をアニメーションで示しました。これは埋め込みに対して主成分分析(PCA)を実行することによって達成されました。これらの埋め込みは、ファインチューニングのさまざまな段階とそれに対応するチェックポイントから生成されました。
![Projection of embeddings with PCA during fine-tuning of a Vision Transformer (ViT) model [1] on CIFAR10 [3]; Source: created by the author — Published before in Changes of Embeddings during Fine-Tuning](https://miro.medium.com/v2/resize:fit:640/1*jYdWl_8UM6ecV1ux8_qr1Q.gif)
このアニメーションは200,000回以上表示されました。多くの読者から興味を持って受け入れられ、その作成方法についての関心が高まりました。この記事は、これらの読者と同様の視覚化を作成に興味がある他の人々をサポートするためにここにあります。
この記事では、次の手順について詳細なガイドを提供し、このようなアニメーションを作成する方法について説明します:ファインチューニング、埋め込みの作成、外れ値の検出、PCA、Procrustes、レビュー、アニメーションの作成。
- Google AIは、環境の多様性と報酬の指定の課題に対処するための、普遍的なポリシー(UniPi)を提案します
- 私の物理学の博士号へのオード
- 「バイオメトリクスをサイバーセキュリティの手法としての利用」というテキストです
アニメーションの完全なコードは、GitHubの付属のノートブックでも利用できます。
準備:ファインチューニング
最初のステップは、事前学習されたgoogle/vit-base-patch16–224-in21k Vision Transformer(ViT)モデル[1]をファインチューニングすることです。これにはCIFAR-10データセット[2]を使用し、10の異なるクラスに分類された60,000枚の画像が含まれています:飛行機、車、鳥、猫、鹿、犬、カエル、馬、船、トラック。
トランスフォーマーを使用した画像分類のHugging Faceチュートリアルの手順に従って、CIFAR-10に対してもファインチューニングプロセスを実行することができます。さらに、TrainerCallbackを使用して、トレーニング中の損失値をCSVファイルに保存して後でアニメーションで使用します。
from transformers import TrainerCallbackclass PrinterCallback(TrainerCallback): def on_log(self, args, state, control, logs=None, **kwargs): _ = logs.pop("total_flos", None) if state.is_local_process_zero: if len(logs) == 3: # skip last row with open("log.csv", "a") as f: f.write(",".join(map(str, logs.values())) + "\n")アニメーションのためにチェックポイントの保存間隔を増やすために、TrainingArgumentsでsave_strategy="step"とsave_stepに低い値を設定することが重要です。アニメーションの各フレームは1つのチェックポイントに対応しています。トレーニング中に各チェックポイントとCSVファイルのためのフォルダが作成され、さらなる使用に備えて準備されています。
埋め込みの作成
TransformersライブラリのAutoFeatureExtractorとAutoModelを使用して、異なるモデルのチェックポイントを使用してCIFAR-10データセットのテストセットから埋め込みを生成します。
各埋め込みは、10,000のテストイメージのうち1つを表す768次元ベクトルです。これらの埋め込みは、チェックポイントと同じフォルダに保存することで、良好な概要を維持することができます。
外れ値の抽出
各チェックポイントの埋め込みに基づいて外れ値を特定するために、Cleanlabライブラリが提供するOutOfDistributionクラスを使用することができます。その結果得られるスコアは、アニメーションのトップ10の外れ値を特定することができます。
from cleanlab.outlier import OutOfDistributiondef get_ood(sorted_checkpoint_folder, df): ... ood = OutOfDistribution() ood_train_feature_scores = ood.fit_score(features=embedding_np) df["scores"] = ood_train_feature_scoresPCAとプロクラステス解析の適用
scikit-learnパッケージのPrincipal Component Analysis(PCA)を使用して、768次元のベクトルを2次元に削減することで、埋め込みを2D空間で可視化します。各タイムステップでPCAを再計算すると、軸の反転や回転によるアニメーションの大きなジャンプが発生する場合があります。この問題に対処するために、SciPyパッケージの追加のプロクラステス解析[3]を適用し、各フレームを最後のフレームに幾何学的に変換します。この変換では、平行移動、回転、一様なスケーリングのみが行われます。これにより、アニメーション内でよりスムーズな遷移が可能となります。
from sklearn.decomposition import PCAfrom scipy.spatial import procrustesdef make_pca(sorted_checkpoint_folder, pca_np): ... embedding_np_flat = embedding_np.reshape(-1, 768) pca = PCA(n_components=2) pca_np_new = pca.fit_transform(embedding_np_flat) _, pca_np_new, disparity = procrustes(pca_np, pca_np_new)Spotlightでのレビュー
アニメーション全体を最終的に確定する前に、Spotlightでレビューを行います。このプロセスでは、最初と最後のチェックポイントを使用して埋め込み生成、PCA、および外れ値検出を行います。結果のDataFrameをSpotlightにロードします:
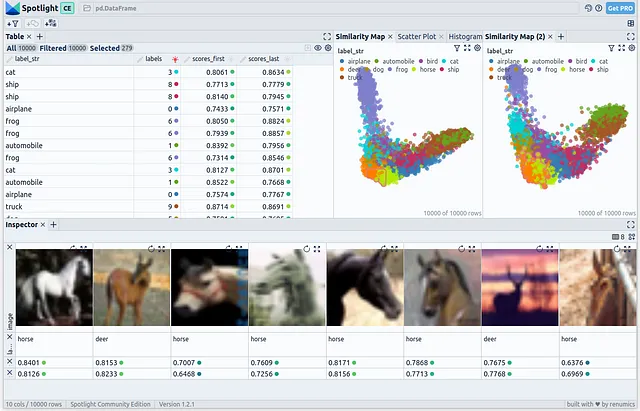
Spotlightは、データセットに存在するすべてのフィールドを示す包括的なテーブルを左上に表示します。右上には2つのPCA表現が表示されます:最初のチェックポイントを使用して生成された埋め込みの1つと最後のチェックポイントの1つです。最後に、下部セクションには選択した画像が表示されます。
免責事項:この記事の著者はSpotlightの開発者の一人でもあります。
アニメーションの作成
各チェックポイントごとに、対応するチェックポイントとともに画像を作成して保存します。
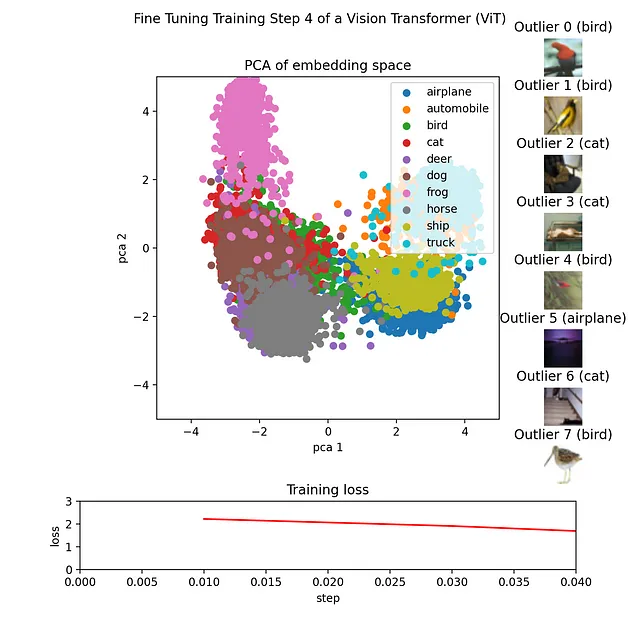
これは、埋め込みを表す2Dポイントを生成するmake_pca(...)および外れ値を抽出するget_ood(...)関数を利用することによって実現されます。2Dポイントは、それぞれのクラスに対応する色でプロットされます。外れ値はスコアに基づいてソートされ、その対応する画像がハイスコアのリーダーボードに表示されます。トレーニングの損失はCSVファイルから読み込まれ、折れ線グラフとしてプロットされます。
最後に、すべての画像はimageioなどのライブラリを使用してGIFにまとめることができます。


結論
この記事では、Vision Transformer(ViT)モデルのファインチューニングプロセスを可視化するアニメーションの作成方法について詳細に説明しました。埋め込みの生成と分析、結果の可視化、これらの要素を結びつけるアニメーションの作成の手順を追いました。
このようなアニメーションの作成は、ViTモデルのファインチューニングプロセスの複雑さを理解するのに役立つだけでなく、他の人にこれらの概念を伝えるための強力なツールとなります。
アニメーションの完全なコードは、GitHub上の付属のノートブックで利用可能です。
私は、非構造化データのインタラクティブな探索のための高度なソフトウェアソリューションを作成する専門家です。非構造化データについて書き、強力な可視化ツールを使用して分析し、的確な意思決定を行います。
参考文献
[1] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby, An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale (2020), arXiv
[2] Alex Krizhevsky, Learning Multiple Layers of Features from Tiny Images (2009), University Toronto
[3] Gower, John C. Generalized procrustes analysis (1975), Psychometrika
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「LLMsの信頼性のあるフューショットプロンプトの選択を確保する」
- 「LLMsとメモリは間違いなく必要なものです:Googleはメモリを補完したLLMsが任意のチューリングマシンをシミュレートできることを示しています」
- このAI論文では、ChatGPTに焦点を当て、テキスト注釈タスクにおける大規模言語モデル(LLM)のポテンシャルを探求しています
- GPT-4のようなモデルは、行動能力を与えられた場合に安全に振る舞うのか?:このAI論文では、「MACHIAVELLIベンチマーク」を導入して、マシン倫理を向上させ、より安全な適応エージェントを構築することを提案しています
- 「FreedomGPT」という名称のAI技術をご紹介しますこの技術はオープンソースであり、アルパカ上に構築され、倫理的な考慮事項を認識し優先するようにプログラムされています何の検閲フィルターもなく、自由な議論を可能にします
- 「AIイメージジェネレータとは何ですか?2023年のトップAIイメージジェネレータ」
- もう1つの大規模言語モデル!IGELに会いましょう:指示に調整されたドイツ語LLMファミリー





