ピクセルを説明的なラベルに変換する:TensorFlowを使ったマルチクラス画像分類のマスタリング
ピクセルを説明的なラベルに変換する:TensorFlowを使った画像分類のマスタリング
ビジュアルワールドを見て理解する知的システムの構築

今日のビジュアルに重点を置いたデジタル環境では、正確な画像の分類能力はこれまで以上に重要です。ヘルスケア、eコマース、自動運転車など、ビジュアルデータを扱う任意の分野であれば、ピクセルの言語を理解することは不可欠であり、画像の分類の技術を習得することで競争力を持つことができます。
ですので、ピクセルが生命を持ち、画像がその秘密を明らかにする冒険に参加する準備はできていますか?もう探す必要はありません!このブログ投稿では、マルチクラス画像分類の複雑さを解き明かし、データの準備、モデルの作成、評価の基本的な概念をカバーすることで、周囲の世界を認識する知的システムを作成する力を与えます。最後まで進むと、TensorFlowを使用して堅牢な画像分類モデルを構築する方法を十分に理解できるようになります。
カスタム画像分類モデルのトレーニングにはいくつかのステップが必要です。以下に概念を構造化します。
マルチクラス画像分類の理解データの準備畳み込みニューラルネットワーク(CNN)モデルの構築画像分類モデルでの予測
さあ、言葉にはせずにこの魅力的な旅に飛び込みましょう。
- 「Pythonデコレーターは開発者のエクスペリエンスをスーパーチャージします🚀」
- 「オーディオ機械学習入門」
- 「Retroformer」をご紹介します:プラグインの回顧モデルを学習することで、大規模な言語エージェントの反復的な改善を実現する優れたAIフレームワーク
セクション1:画像分類って何?
画像分類は、画像の内容を事前に定義されたクラスやラベルに分類することによって、コンピュータビジョンの基本的なタスクです。
画像分類の機械学習モデルは、人間の脳の認識能力を模倣します。
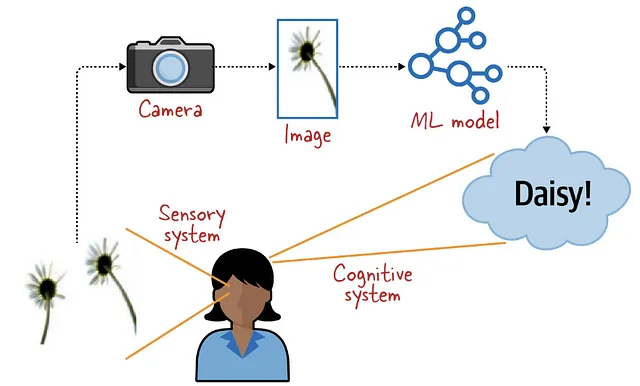
画像分類に関しては、通常、異なるクラスやラベル(有名な猫や犬など)でラベル付けされたデータセットを使用して、機械学習モデルを教えることから始まります。モデルは画像から重要な特徴を抽出し、これらの特徴を数学的な計算の連続を通じて対応するラベルに関連付ける能力を獲得します。最終的な目標は、これらのトレーニング済みモデルを使用して、視覚的な属性に基づいて未知の画像に正確なラベルを割り当てることです。
& マルチクラス画像分類とは?
マルチクラス分類では、2つのカテゴリ(0または1)の区別ではなく、複数のクラスの同時識別を扱います。例えば、動物を分類するマルチクラス分類タスクでは、「犬」「猫」「鳥」「馬」などのクラスが存在するかもしれません。

提供されたスナップショットはCIFAR-10データセットを示しており、101の食品カテゴリで構成されています。各カテゴリには1,000の画像が含まれており、合計で101,000の画像があります。このデータセットには、果物、野菜、デザート、料理など、さまざまな料理からのさまざまな食品が含まれています。このデータセットは、マルチクラス画像分類モデルの効果を評価するための広く認識されたベンチマークとして使用されています。データセットの探索が完了したので、次のセクションであるデータの準備に移りましょう。
セクション2:データとの親しみ
このセクションでは、包括的な食品画像のコレクションであるFood-101データセットを使用してデータの準備に焦点を当てます。Food-101データセットには101の食品カテゴリと101,000の画像が含まれていますが、より管理しやすいモデルを作成し、計算時間を節約するために5つの食品カテゴリを選択します。
まず、Food-101データセットをダウンロードし、構造化されたフォルダ階層に整理します。ルートフォルダ内にデータディレクトリを作成し、画像フォルダを以下のように配置します👇
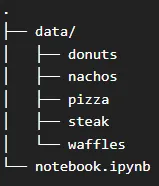
このような構成にすることで、効率的なデータ処理とトレーニングおよび評価段階での簡単なアクセスが容易になります。
次に、TensorFlowのtf.dataモジュールを活用して、データパイプラインを構築し、データセットからシームレスに食品画像をストリーミングします。Kerasのimage_dataset_from_directoryAPIを使用し、画像ファイルを含むディレクトリ構造からTensorFlowのtf.data.Datasetを作成します。このAPIは、サブディレクトリ名に基づいてラベル付けされたデータセットを自動的に生成します。各サブディレクトリ内の画像ファイルは、対応するラベルと関連付けられています。また、バッチサイズ、画像サイズ、シャッフル、拡張などのパラメータを設定するオプションも提供されています。コードを書いてみましょう。
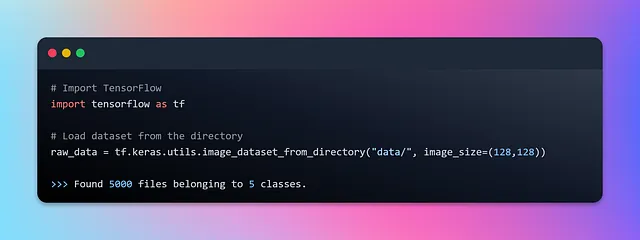
では、生のデータセットについて詳しく調べ、このAPIが画像とラベルをどのように変換し、バッチを構築するかを理解していきましょう。デフォルトでは、APIは32セットのバッチで画像を処理します。また、画像はサイズ(256, 256)にリサイズされます。ただし、すべての画像がそのサイズ以上であることを保証するために、安全なサイズを最小の次元として考慮することをお勧めします。
生のデータセットを見てみましょう。

ここでraw_dataは、要素が2つのコンポーネントを含むタプルで構成されるバッチデータセットです。バッチデータセットの各要素の最初のコンポーネントは、可変バッチサイズ(Noneで示される)、高さと幅が128ピクセルで、カラーチャンネルが3(RGB)であるテンソルです。バッチデータセットの各要素の2番目のコンポーネントは、可変バッチサイズ(Noneで示される)のラベルを表すテンソルです。ラベルは画像ファイルパスのアルファベット順に並べられます。より深く理解するために、1つのバッチとその最初の要素を見てみましょう。
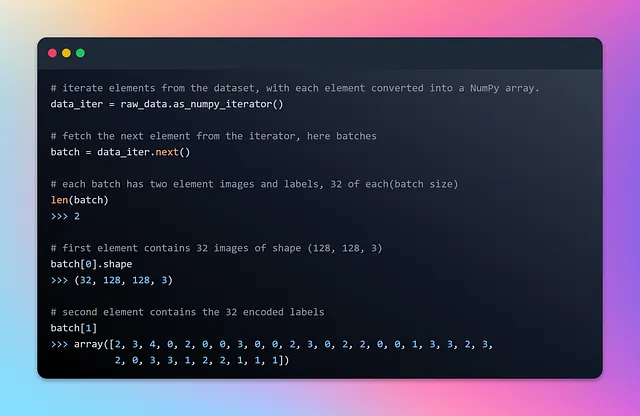
イテレーション中にバッチデータセットがどのようにストリーミングされるかについていくつかの理解を得たので、データの正規化を行い、データセットをトレーニングセットとテストセットに分割しましょう。この分割により、モデルはデータの一部から学習し、未知の食品画像でテストされます。この評価プロセスにより、モデルが新しい食品アイテムに対して一般化し、正確にパフォーマンスを評価する能力が向上します。
この前処理ステップにより、データがニューラルネットワークにフィードするための適切な形式になることが保証されます。
各画像配列を255で割ることで、ピクセル値を0から1の範囲に正規化します。この正規化は、ピクセル値が似た尺度であることを保証するために一般的に行われ、データからの学習をニューラルネットワークにとって容易にします。
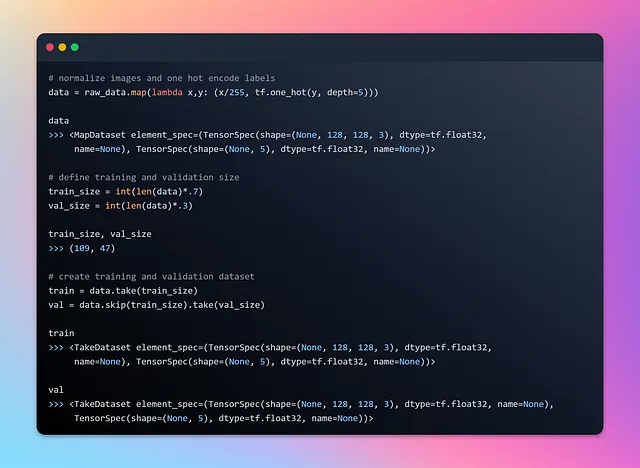
tf.one_hot()関数は、各ラベルを長さがdepthパラメータ(この場合は5)と等しいバイナリベクトルで表すワンホットエンコーディングを作成するために使用されます。ワンホットエンコーディングは、マルチクラス分類問題でカテゴリカルなラベルをニューラルネットワークに適した形式で表現するためによく使用されます。
データ作成プロセスが完了し、トレーニングセットと検証セットをニューラルネットワークに入力する準備が整いました。時間を無駄にせず、次のセクションに進みましょう。ここでは、ゼロからネットワークを構築します。
セクション3:効果的な画像分類のためのCNNアーキテクチャの作成
畳み込みニューラルネットワーク(CNN)を使用した分類ネットワークの構築に身を投じることで、スリリングな冒険が始まります。経験豊富なプロまたはCNNの基礎を思い出したい方にもおすすめです。このセクションに入る前に、私のCNNの基礎に関するブログをチェックすることを強くお勧めします。そこで、CNNの基礎を復習し、CNNの力に慣れ親しむことができます。
畳み込みニューラルネットワークの理解 🧠:初心者のためのアーキテクチャへの旅 🚀
畳み込みニューラルネットワーク(CNN)とは何ですか?
VoAGI.com
知識と自信を持って、この興奮のある旅に乗り出しましょう。CNNを使用して信じられないほどの分類ネットワークを作成しましょう!
さあ、始めましょう ⚡
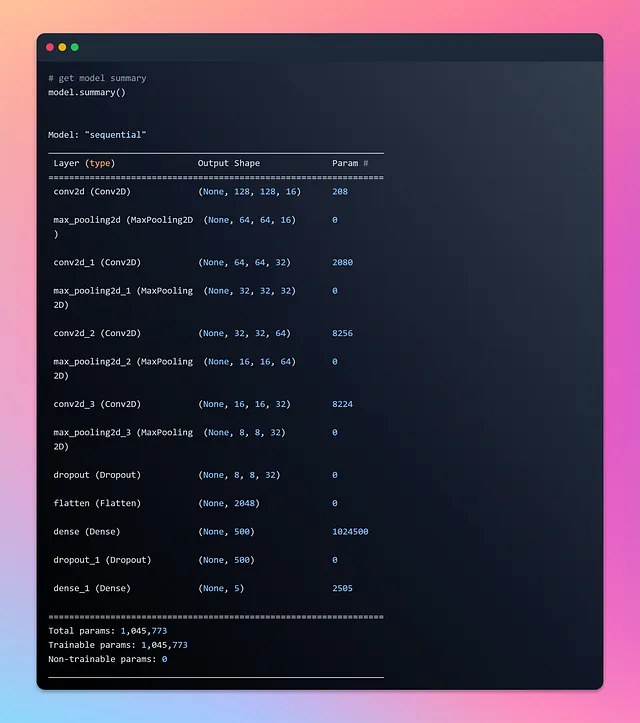
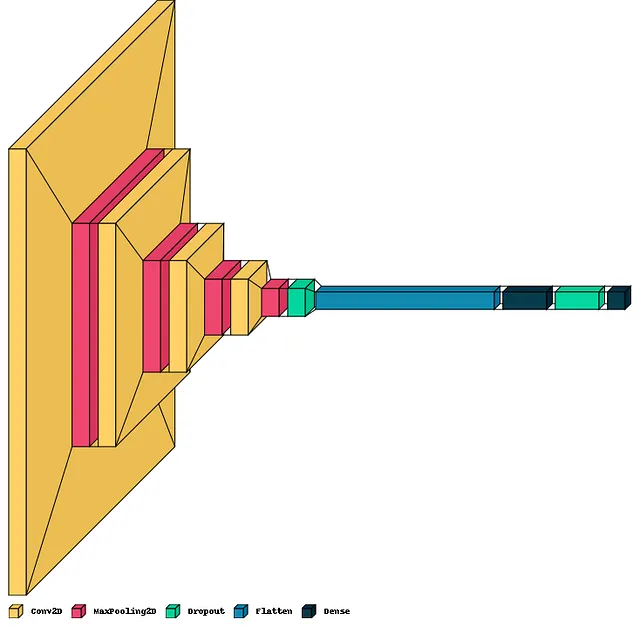
モデルの概要をチェックし、visualkerasを使用して可視化します。
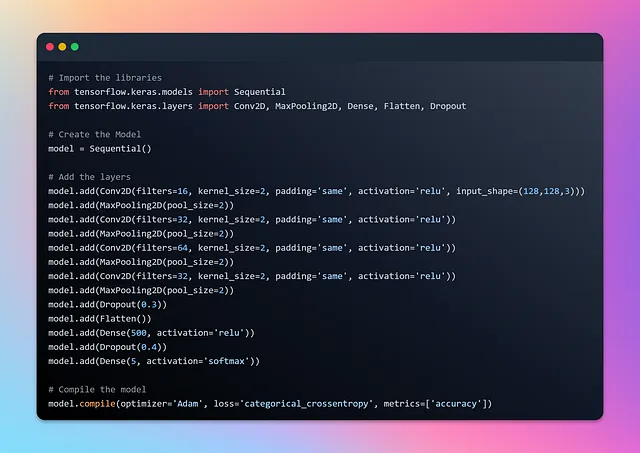
モデルの作成に成功したので、前のセクションで細心の注意を払って準備したデータをモデルに入力し、トレーニングを開始します。トレーニングの進行状況を追跡するために、トレーニング履歴を「history」という変数に保存します。TensorFlowデータセットを使用する利点は、トレーニング中にバッチサイズを明示的に定義する必要がないことです。データをモデルに入力してトレーニングする際に、データセットがバッチを自動的に生成してくれるのです。
100エポックの優れたトレーニングを目指し、トレーニングの旅に乗り出しましょう。モデルのトレーニング中に自動的にバッチが生成される便利さと効率性を活用しましょう。トレーニングを開始しましょう 🚀
ここで、モデルのトレーニングプロセスが終了します。トレーニングの進行状況を可視化するために、トレーニング履歴を使用して精度と損失のグラフをプロットしましょう。
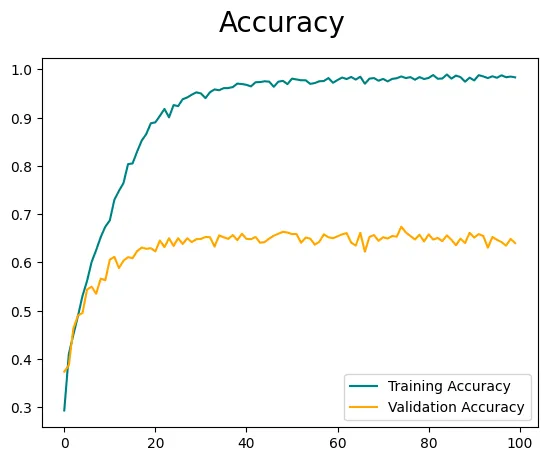
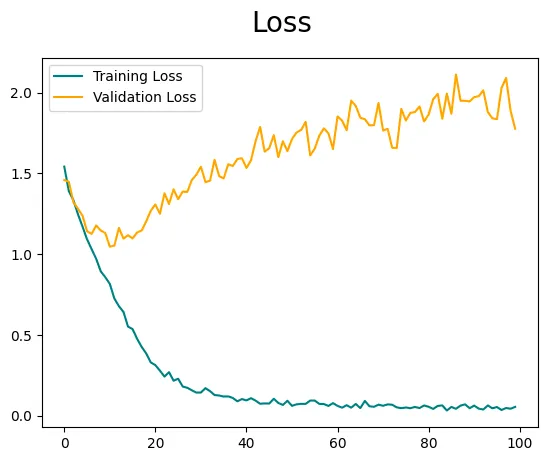
重要なことは、正確さと損失が最適でない場合があるということです。特徴エンジニアリングや画像拡張の技術を組み込まずに、画像をモデルに直接フィードしています。モデルのパフォーマンスをさらに向上させるには、ハイパーパラメータの調整が推奨されますが、それは別のブログの話題です。ただし、画像拡張を探求し理解することに興味がある場合は、以前のブログで既に取り上げています👇
レベルアップ 🚀 コンピュータービジョン 👀 ゲーム:画像拡張の潜在能力を活用する
パフォーマンスと堅牢性の向上
ai.plainenglish.io
これらの技術を実装することで、ビジョンモデルのパフォーマンスが確実に向上します。
さて、トレーニング済みのモデルの力を解放し、予測を行いピクセルに隠された真のラベルを明らかにする最後のセクションに移行しましょう。
セクション4:モデルを使用して予測する
予測の旅に出る前に、モデルにフィードする画像は、ニューラルネットワークの入力層と同じサイズである必要があることを覚えておくことが重要です。互換性を確保するために、予測に渡す前に画像のサイズを適切にリサイズします。モデルは確率の配列を生成し、各要素は対応するワンホットエンコードされたラベルの可能性を表します。NumPyのargmax関数を使用することで、予測されたラベルに対応するインデックスを抽出することができます。私はおいしそうなピザのランダムに選択された画像をロードし、トレーニング済みモデルをテストします。

リサイズ、予測、およびピクセル内に隠されたラベルを解明する魅力的なプロセスを目撃する準備をしてください!
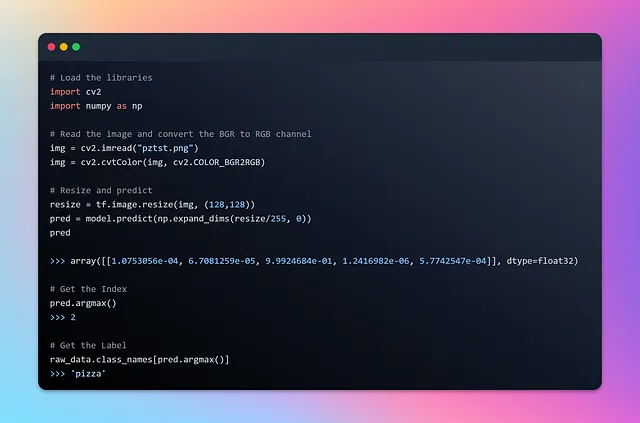
ボワッ!私たちのモデルは、ピンポイントの正確さで画像の真の正体を明らかにしました 💯
やりました!マルチクラスの画像分類のためにゼロからカスタムモデルを作成するという信じられない偉業を達成しました 🎉
完全なコードのリンクはこちらです 📜
このブログで一緒に旅をすることは、楽しい結末を迎えますが、心配しないでください。次の冒険でまた会いましょう。そこでは、他の魅力的なコンピュータービジョンの問題の謎を解き明かします。その間、探求し、独自の画像分類モデルをトレーニングし続けてください。さようなら 👋 また会う日まで!
この記事がお楽しみいただけたら幸いです!私のフォローをしていただければ、Afaque Umerによるさらに多くのこのような記事をご覧いただけます。
私は、より多くの機械学習/データサイエンスの概念を取り上げ、難しそうな用語や概念をよりシンプルなものに分解しようと努めます。
読んでくれてありがとう 🙏 学び続けてください 🧠 共有し続けてください 🤝 素晴らしいままでいてください 🤘
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「集団行動のデコード:アクティブなベイズ推論が動物グループの自然な移動を支える方法」
- このAI論文では、これらの課題に対処しながらMoEsの利点を維持するために、完全に微分可能な疎なTransformerであるSoft MoEを提案しています
- 「生成モデルを本番環境に展開する際の3つの課題」
- 「Javaプログラミングの未来:2023年に注目すべき5つのトレンド」
- 「人工知能(AI)とWeb3:どのように関連しているのか?」
- AWSは、大規模なゲーミング会社のために、Large Language Model (LLM) を使って有害なスピーチを分類するためのファインチューニングを行います
- AIの力による教育:パーソナライズされた成功のための学習の変革






