ビデオゲームの世界でインタラクティブなエージェントを構築する
ビデオゲームのためのインタラクティブなエージェントを作る
人間の指示を理解し、オープンエンドの状況で行動するAIエージェントを作成するためのフレームワークの紹介
人間の行動は非常に複雑です。例えば、「ボールを箱の近くに置いてください」という単純な要求でも、その意図と言語の状況を深く理解する必要があります。『近く』という言葉の意味は明確にするのが難しいかもしれません – ボールを箱の中に置くことが技術的に最も近い場所かもしれませんが、話者はおそらくボールを箱の隣に置きたいのでしょう。要求に適切に対応するためには、状況と周囲の文脈を理解し判断できる能力が必要です。
ほとんどの人工知能(AI)の研究者は、現在、実際の相互作用の微妙なニュアンスを捉えることは不可能だと考えています。代わりに、現代の機械学習(ML)の研究者は、これらの相互作用についてデータから学ぶことに焦点を当てています。学習ベースのアプローチを探求し、人間の指示を理解し、オープンエンドの条件で安全に行動できるエージェントを素早く構築するために、私たちはビデオゲーム環境内に研究フレームワークを作成しました。
今日、私たちは論文とビデオのコレクションを公開し、人間の概念を理解できるビデオゲームAIの初期の取り組みを紹介しています。したがって、彼らは自分たちの条件で人々と対話を始めることができます。
最近のビデオゲームAIのトレーニングの進歩の多くは、ゲームのスコアを最適化することに依存しています。StarCraftやDotaの強力なAIエージェントは、コンピュータコードによって計算された明確な勝利/敗北に基づいてトレーニングされました。ゲームスコアの最適化ではなく、私たちは人々にタスクを考え出してもらい、進捗を判断してもらいます。
このアプローチを用いて、私たちは人間との具体的でオープンエンドの相互作用を通じてエージェントの行動を改善する研究パラダイムを開発しました。まだ初期段階ではありますが、このパラダイムにより、エージェントはリアルタイムで聞く、話す、質問する、ナビゲートする、検索と取得する、オブジェクトを操作するなど、多くの活動を行うことができます。
このコンピレーションは、人間の参加者によって提出されたタスクに従ってエージェントが行動する様子を示しています:

「遊び場」での学習
私たちのフレームワークは、人々がビデオゲームの世界で他の人々と相互作用することから始まります。模倣学習を使用して、エージェントに幅広いが未精製な行動セットを与えました。この「行動の事前条件」は、人間によって判断できる相互作用を可能にするために重要です。この初期の模倣フェーズがないと、エージェントは完全にランダムであり、実質的には対話することが不可能です。さらに、エージェントの行動の人間による評価とこの評価の強化学習(RL)による最適化により、より良いエージェントが生み出され、さらに改善されることができます。
最初に、子供の「遊び場」のコンセプトに基づいたシンプルなビデオゲームの世界を作りました。この環境は、人間とエージェントが相互作用するための安全な設定を提供し、大量の相互作用データを迅速に収集することが容易でした。この家には、さまざまな部屋、家具、オブジェクトがあり、各相互作用ごとに新しい配置で構成されていました。また、相互作用のためのインターフェースも作成しました。
人間とエージェントの両方には、ゲーム内で移動し、環境を操作するためのアバターがあります。彼らはリアルタイムでお互いとチャットすることもでき、物を運んだりお互いに手渡したり、ブロックの塔を作ったり、一緒に部屋を掃除したりするなどの活動を協力して行うこともできます。人間の参加者は、世界を移動し、目標を設定し、エージェントに対して質問をしたりすることで、相互作用の文脈を設定します。総計で、このプロジェクトはエージェントと数百人の(人間の)参加者との間で25年以上にわたるリアルタイムの相互作用データを収集しました。
生じる行動の観察
訓練したエージェントは、予想されていなかったさまざまなタスクを実行する能力を持っています。たとえば、これらのエージェントは、2つの交互に色を変えたオブジェクトの列を作成したり、ユーザーが持っている他のオブジェクトに類似した家からオブジェクトを取得したりすることができることがわかりました。
これらの驚きは、言語が単純な意味の組み合わせによってほぼ無限のタスクと質問を可能にするために生じます。また、私たち研究者がエージェントの行動の詳細を指定しません。代わりに、相互作用に参加する数百人の人間が、これらの相互作用の過程でタスクや質問を考え出しました。
これらのエージェントを作成するためのフレームワークの構築
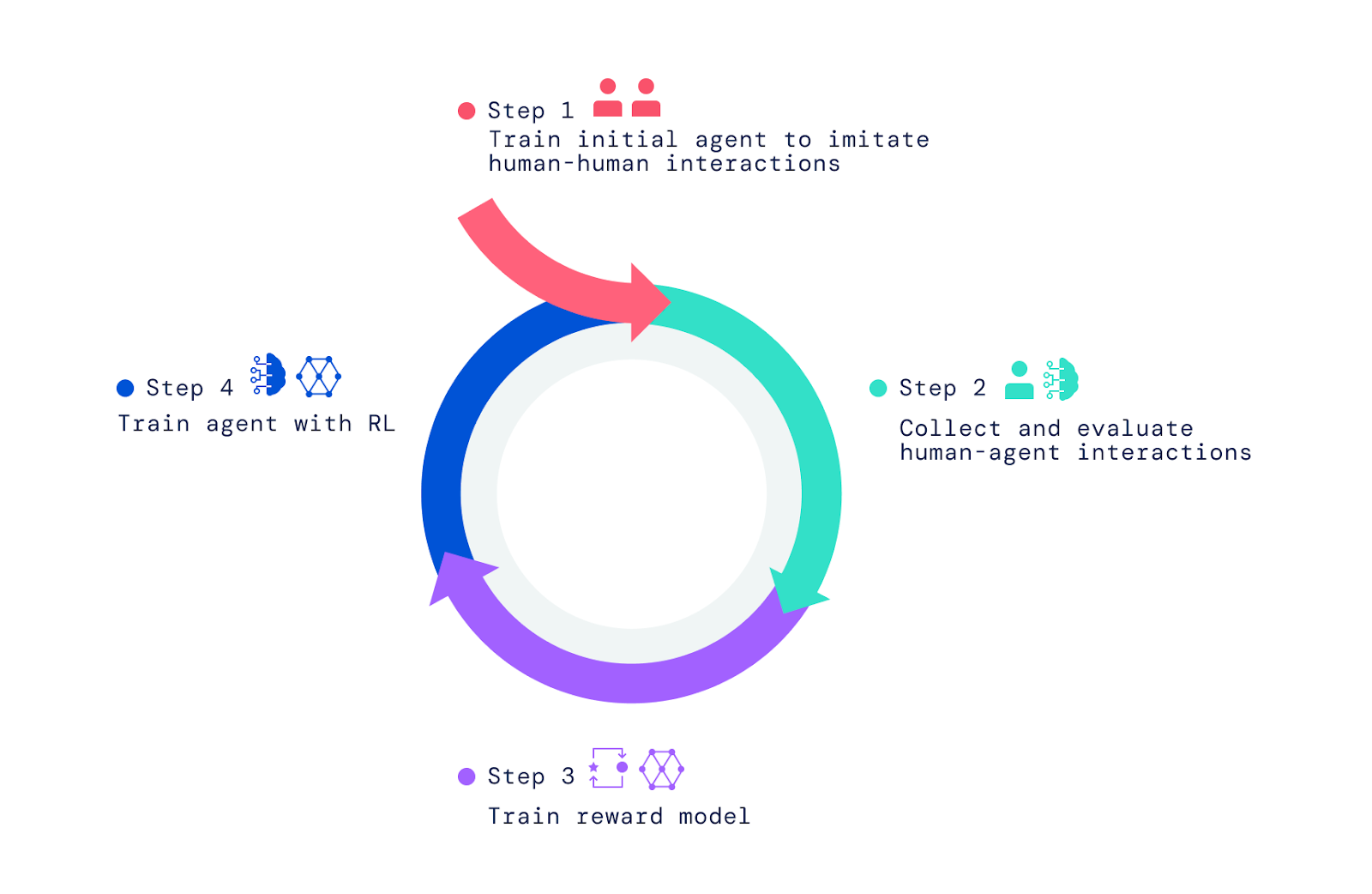
AIエージェントを作成するために、3つのステップを適用しました。まず、人間が何かを頼んだり質問したりするシンプルな人間の相互作用の基本要素を模倣するようにエージェントを訓練しました。このフェーズを「行動の事前学習」と呼びます。この事前学習によって、エージェントは高頻度で人間と意味のある相互作用を行うことができます。この模倣フェーズがないと、エージェントはランダムに動き回り、無意味なことを話します。エージェントとの相互作用はほとんど不可能で、フィードバックを与えることもさらに困難です。このフェーズは、私たちの以前の2つの論文「Imitating Interactive Intelligence」と「Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning」で取り上げられています。
模倣学習を超えて
模倣学習は興味深い相互作用をもたらしますが、各相互作用の瞬間を同じ重要視しています。効率的な目標指向の行動を学ぶためには、エージェントが目標を追求し、特定の瞬間における動きや意思決定をマスターする必要があります。たとえば、模倣ベースのエージェントは、平均的な人間プレイヤーよりも効率的にショートカットを取ったり、タスクを実行したりすることができません。
ここでは、模倣学習ベースのエージェントとRLベースのエージェントが同じ人間の指示に従っている様子を示しています。
模倣だけでは実現できない目的意識をエージェントに与えるために、私たちはRLを利用しました。RLは、試行錯誤とパフォーマンスの測定を組み合わせた反復的な改善によって動作します。エージェントがさまざまな行動を試みる中で、パフォーマンスを向上させた行動は強化され、パフォーマンスを低下させた行動は罰せられます。
Atari、Dota、Go、StarCraftなどのゲームでは、スコアが改善すべきパフォーマンスの尺度となります。スコアの代わりに、私たちは人間に状況を判断しフィードバックを提供してもらい、これがエージェントが報酬のモデルを学ぶのに役立ちました。
報酬モデルの訓練とエージェントの最適化
報酬モデルを訓練するために、人間に、現在の指示された目標に向かって目立つ進歩を示すイベントや目立つエラーやミスを観察したかどうかを判断してもらいました。そして、これらのポジティブなイベントとネガティブなイベントとをポジティブな優先順位とネガティブな優先順位に対応づけました。時間を跨いで行われるため、これらの判断を「時間的な」と呼んでいます。私たちはニューラルネットワークを訓練して、これらの人間の優先順位を予測し、人間のフィードバックを反映した報酬(または効用/スコアリング)モデルを得ました。
人間の優先順位を使って報酬モデルを訓練した後、エージェントを最適化するためにそれを使用しました。私たちはエージェントをシミュレータに配置し、質問に答えたり指示に従ったりするようにしました。彼らが環境で行動し話すとき、私たちの訓練された報酬モデルは彼らの行動を評価し、RLアルゴリズムを使用してエージェントのパフォーマンスを最適化しました。
では、タスクの指示や質問はどこから来るのでしょうか?これについて、2つのアプローチを試しました。まず、人間のデータセットで提起されたタスクと質問を再利用しました。次に、人間がタスクを設定し質問をする方法を模倣するようにエージェントを訓練しました。以下のビデオでは、タスクを設定し質問をする方法を模倣するように訓練されたエージェント(青)と指示に従い質問に答えるエージェント(黄)がお互いに相互作用しています。
エージェントの評価と繰り返し改善
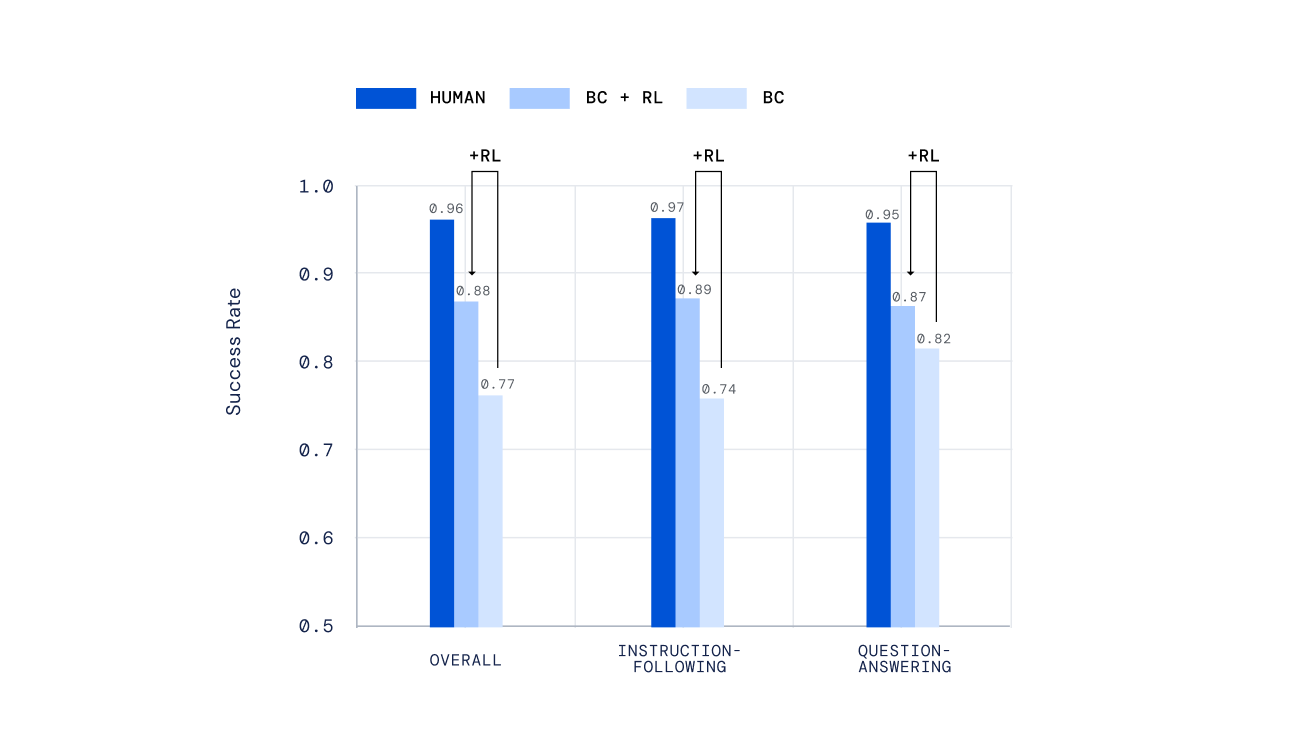
私たちは、エージェントの評価にさまざまな独立したメカニズムを使用しました。ハンドスクリプトを使用したテストから、私たちの以前の研究で開発されたオープンエンドタスクのオフライン人間スコアリングの新しいメカニズムまで、さまざまな手法を用いました。重要なことは、人々にリアルタイムで私たちのエージェントと対話し、そのパフォーマンスを判断してもらったことです。強化学習によってトレーニングされたエージェントは、単に模倣学習だけでトレーニングされたエージェントよりもはるかに優れたパフォーマンスを発揮しました。
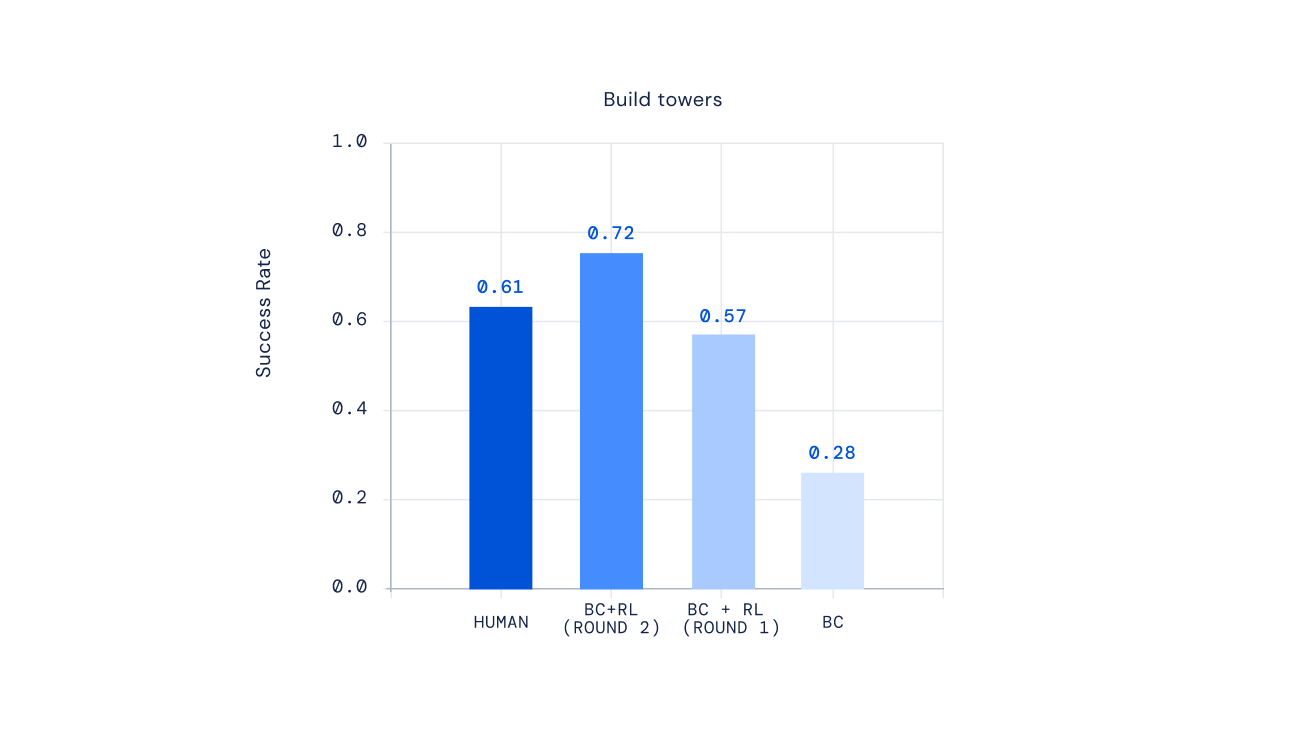
最後に、最近の実験では、強化学習プロセスを繰り返すことでエージェントの振る舞いを改善できることが示されています。強化学習によってエージェントがトレーニングされた後、私たちは人々にこの新しいエージェントと対話し、その振る舞いを注釈し、報酬モデルを更新し、さらに強化学習の繰り返しを行いました。このアプローチの結果、ますます能力のあるエージェントが生まれました。一部の複雑な指示については、人間プレイヤーを平均して上回るエージェントを作成することさえ可能でした。
人間の状況に基づくAIのトレーニングの未来
人間の好みを報酬として使用してAIをトレーニングするアイデアは長い間存在しています。Deep reinforcement learning from human preferencesでは、研究者たちはニューラルネットワークベースのエージェントを人間の好みに合わせる最近のアプローチを先駆的に開拓しました。ターンベースの対話エージェントを開発するための最近の取り組みでは、人間のフィードバックから強化学習でアシスタントをトレーニングするという同様のアイデアが探索されました。私たちの研究は、これらのアイデアを適応・拡張し、人々との多様なモード、具現化、リアルタイムの相互作用をマスターする柔軟なAIを構築することに取り組んでいます。
私たちは、私たちのフレームワークが手スクリプトの行動計画に頼らず、私たちが自然に表現した意味に応答するゲームAIの創造につながることを願っています。私たちのフレームワークは、日常的に人々と対話するためのデジタルおよびロボットアシスタントの構築にも役立つ可能性があります。私たちは、このフレームワークの要素を適用して本当に役立つ安全なAIを作成する可能性を探求することを楽しみにしています。
さらに学びたいですか?最新の論文をご覧ください。フィードバックやコメントを歓迎します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- AIに人間の価値観をどのように組み込むことができるのでしょうか?
- DeepMindの最新研究(ICLR 2023)
- あなたのオープンソースのLLMプロジェクトはどれくらいリスクがあるのでしょうか?新たな研究がオープンソースのLLMに関連するリスク要因を説明しています
- このAI研究は、大規模言語モデル(LLM)における合成的な人格特性を説明しています
- HuggingFace Researchが紹介するLEDITS:DDPM Inversionと強化された意味的なガイダンスを活用したリアルイメージ編集の次なる進化
- MITの科学者たちは、生物学の研究のためのAIモデルを生成できるシステムを構築しました
- Covid-19への闘いを加速する:研究者がAIによって生成された抗ウイルス薬を検証し、将来の危機における迅速な薬剤開発の道を開拓