パンダの力を解放する:.locと.ilocの深いダイブ
パンダの力を解放する:.locと.ilocの深いダイブ
Pandasを使ったデータ分析の強化:正確なデータ選択のための.locと.ilocのマスタリング

Pythonプログラミング言語は、ユーザーフレンドリーな性質と強力なライブラリにより、データサイエンスと分析において重要な資産です。その中でもPandasというライブラリは、柔軟性と強力なデータ操作ツールを提供し、世界中のデータサイエンティストに人気の選択肢となっています。
データ分析のプロセスでは、効率的にデータを管理・操作する能力が重要であり、それがPandasの得意とするところです。Pandasが提供するさまざまなツールの中でも、loc、iloc、ixの3つがその汎用性により際立っています。
これらのメソッドは、Pandasにおけるデータ選択において重要であり、loc、iloc、ixを使用することで、Pandas DataFrame内のデータに対して驚くべき柔軟性を提供します。
データ選択は、データ分析において欠かせないステップであり、分析、可視化、または機械学習アルゴリズムの入力として、データセットから特定のデータを選択することを指します。
なぜloc、iloc、またはixを使用するのですか?
データサイエンティストは、しばしばデータセットの一部のみを必要とします。その際、loc、iloc、およびixメソッドは非常に重要であり、DataFrameの位置や特定の条件に基づいて効率的にデータを選択することができます。
この記事では、これら3つの重要なPandasメソッドについて、使用例や詳細を掘り下げて説明します。
私たちは、同じコードを再現できるように事前に作成されたデータセットを使用し、目標はPandasを使用してPythonで任意のデータセットを操作・ナビゲートするための知識と自信を身につけることです。
Pandasのメソッドについてさらに読みたい場合は、17のPandasトリックをご覧ください。また、コードの記述が面倒な場合はPandaSAIを使用してプロンプトを記述することもできます。
では、準備はできましたか?探索を始めましょう。
Pandasにおけるデータ選択の理解
データ選択のプロセスは、データ分析やデータサイエンスのタスクにおける基礎的な側面です。
データを分析したり、可視化したり、機械学習アルゴリズムに適用する前に、大きなデータセットから必要なデータを選択する必要があります。
データの一部を選択して処理せずにアルゴリズムを実行すると、処理速度が非常に遅くなったり、実際に重要なデータを除外してしまう可能性があります。
Pandasにおけるデータ選択は、単に列や行を選び出すことを超えて、特定の条件に基づいてデータの特定の部分集合を選択することを意味します。Pandasでは、行と列を持つテーブルのようなデータ構造であるデータフレームをよく扱います。
データフレームの行は異なる観測値を表し、列はさまざまな特徴または変数を表します。Pandasの柔軟性の一環として、強力なデータ選択メソッドを使用することで、私たちは自分のニーズに応じてこれらのデータフレームの特定のセグメントを迅速に分離することができます。
データ選択の理解は非常に重要です。それにより、データを探索し理解する機会が得られます。
適切なテクニックを用いることで、特定の条件に基づいて特定の行を選択したり、分析に重要な列を選択したりすることができます。
Pythonにおけるデータ選択の方法
Pandasでは、データ選択には主に3つのメソッドが使用されます:loc、iloc、およびix。それぞれのメソッドにはそれぞれの利点があり、輝く特定の使用例があります。
locメソッドは、ラベルベースのデータ選択に使用され、ilocは整数ベースの選択に使用され、ixはラベルと整数の両方の選択をサポートするより汎用的なメソッドです。
これらのメソッドは、さまざまな方法でデータフレームからデータを選択するのに役立ちます。
次のセクションでは、事前に作成されたデータセットを使用して、これらのメソッドを詳しく調べていきます。
これにより、データ選択に関する豊富な知識が得られます。それは、熟練したデータアナリストまたは科学者になるための重要なステップです。
では、次のセクションでlocメソッドを使ったこれらの選択方法について詳しく見ていきましょう。
locを使ったデータの選択
locメソッドは、Pandasライブラリで使われる強力なツールで、ラベルベースのデータ選択に使用されます。実際のインデックスや列名のラベルを使用してデータを選択することができるため、直感的に使用することができます。
locを活用するために、seabornライブラリの組み込みデータセットである「タイタニック」データセットを使用します。このデータセットには、遭難したタイタニック号の乗客データが含まれており、各乗客の年齢、性別、運賃、生存したかどうかなどの情報が含まれています。 locメソッドを使用することで、このデータセットに深く入り込んで洞察に富んだ情報を引き出すことができます。
まず、必要なライブラリをインポートしてデータを読み込みましょう。
import seaborn as sns
import pandas as pd
# seabornから「タイタニック」データセットを読み込む
titanic = sns.load_dataset('titanic')
# データの最初の数行を表示する
titanic.head()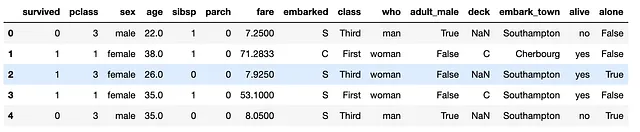
では、locメソッドを使ってみましょう。 locコマンドの書式は次のとおりです:dataframe.loc[行, 列] .
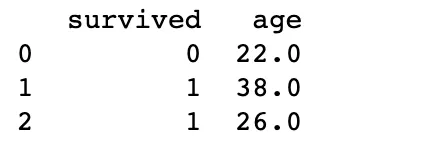
たとえば、データフレームの最初の乗客を選択したいとします。
この場合、インデックスラベルを指定することで選択することができます。ここにコードがあります。
# 最初の行とすべての列を選択する
first_passenger = titanic.loc[0, :]
print(first_passenger)以下は出力結果です。

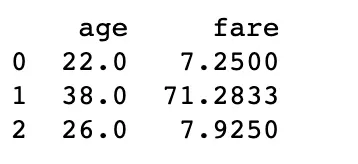
この柔軟性は行の選択で終わりません。特定の列も選択することができます。たとえば、最初の3人の乗客の「年齢」と「運賃」に興味があるとします。 locを使用してこのデータを選択する方法は次のとおりです。
# 最初の3行と特定の列を選択する
first_three_passengers_data = titanic.loc[[0, 1, 2], ['age', 'fare']]
print(first_three_passengers_data)以下は出力結果です。
これはlocメソッドの機能の一部に過ぎません。 locはブール条件も扱うことができ、特定の条件を満たす行を選択することができます。たとえば、18歳未満のすべての乗客を見つけたい場合、locを使用して簡単に実現できます。
# 18歳未満のすべての乗客を選択する
under_18_passengers = titanic.loc[titanic['age'] < 18, :]
under_18_passengers以下は出力結果です。

locメソッドは、ラベルに基づいてデータを選択する際に多目的で直感的で効果的です。ただし、ラベルではなく位置に基づいてデータを選択する必要がある場合もあります。それがilocメソッドの役割であり、次のセクションで説明します。
位置に基づくデータの選択
locは、ラベルに基づく選択に強力なツールとして機能しますが、Pandasは純粋に整数ベースの位置選択のためのilocメソッドも提供しています。 ilocメソッドを使用すると、データフレームの行と列に、それぞれの整数位置を指定してアクセスできます。
‘titanic’データセットでの探索を続けましょう。 ilocを使用して、インデックスラベルや列名に関係なく、整数位置に基づいて特定の行または列を選択できます。
ilocの構文はlocと非常に似ています:dataframe.iloc[行, 列]。違いは、行と列の指定方法です。 ilocでは、ラベルではなく整数位置を使用します。
たとえば、データフレームの最初の行(つまり、0番目の位置)を選択します:
# 最初の行とすべての列を選択するfirst_row = titanic.iloc[0, :]print(first_row)出力は次のとおりです。

ilocは、複数の行や列を一度に選択するのにも役立ちます。
たとえば、最初の3つの行と1番目(0番目の位置)と4番目(3番目の位置)の列を選択する場合は、次のようにします:
# 最初の3つの行と特定の列を選択するselected_data = titanic.iloc[0:3, [0, 3]]print(selected_data)出力は次のとおりです。
ilocを使用してスライスする場合、開始バウンドは含まれますが、停止バウンドは含まれません。これは、locを使用したラベルベースのスライスとは異なります。したがって、0:3は整数位置0、1、2の行を選択します。
ilocでは、locとは異なり、負のインデックスも機能します。これは、最後の行または列を選択するためにインデックスとして-1を使用できることを意味します:
# 最後の行とすべての列を選択するlast_row = titanic.iloc[-1, :]print(last_row)出力は次のとおりです。

locとilocの間で、データフレームからデータを選択する方法には多くの柔軟性があります。ラベル、整数位置、またはその両方に基づいて選択することができます。これらの関数を使用するタイミングと方法を知ることは、データ操作のスキルを大幅に向上させることができます。ただし、これら2つの関数だけでなく、Pandasには他のメソッドもあります。次のセクションでは、データの選択に使用する別のメソッドであるatとiatについて見ていきます。
より高速なアクセスのためのatおよびiatの使用
データ選択のためのlocおよびilocは確かに強力なツールですが、大規模なデータセットを扱う場合など、さらに高速なメソッドが必要な場合があります。ここで登場するのがatおよびiatです。両方のatおよびiatは、locおよびilocに比べてより高速なデータアクセスを提供します。
この速度のトレードオフとして、atおよびiatは一度に単一の値にアクセスすることしかできません。これらはDataFrameまたはSeries内の単一の値を取得または設定するために使用され、ブールインデックスや複数の値への同時アクセスには使用できません。
それでは実際の動作を見てみましょう。’titanic’データセットを引き続き使用して、最初の行の乗客の’fare’にすばやくアクセスしたいとします:
# `at`を使用する場合fare_at = titanic.at[0, 'fare']print(fare_at)# `iat`を使用する場合fare_iat = titanic.iat[0, 8]print(fare_iat)
最初の例では、atがラベルインデックス(この場合は0)に基づいて’fare’の値にアクセスするために使用されます。
2番目の例では、iatが行内の整数位置(8)に基づいて’fare’の値にアクセスするために使用されます。
Pandasでこれらのデータ選択のすべての方法をカバーしたので、データセットを扱う際に適切なツールを使用していることを確認するためのベストプラクティスについて説明して結論付けましょう。
最後に
loc、iloc、at、およびiatの理解は、Pandasでデータを扱う際の効率と効果を大幅に向上させます。
これらのメソッドは、柔軟で強力なデータ選択オプションを提供し、遭遇する可能性のあるほぼすべてのデータ選択タスクを処理することができます。
これらのツールで練習を続ければ、すぐにPandasのプロになることができます。
記事をお読みいただきありがとうございました。
こちらは私のAIとデータサイエンスに関するデイリーニュースレターです。
こちらは私のNumPyチートシートです。
こちらは「 億万長者になる方法 」データプロジェクトのソースコードです。
こちらは「 Pythonを使用した6つの異なるアルゴリズムによる分類タスク 」データプロジェクトのソースコードです。
こちらは「 エネルギー効率分析における決定木 」データプロジェクトのソースコードです。
こちらは「 DataDrivenInvestor 2022 記事分析 」データプロジェクトのソースコードです。
VoAGIのメンバーでなく、読書を通じて知識を拡大したい場合は、こちらが私の参照リンクです。
こちらは私のE-Bookです: ChatGPTで機械学習を学ぶ方法?
「機械学習は人類が行う最後の発明です。」- ニック・ボストロム
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
