パンダのプレイブック:7つの必須の包括的なデータ関数
パンダのプレイブック:7つの必須なデータ関数

データ分析と機械学習の領域において、Pandasライブラリは強力なツールとして存在します。200以上の関数とメソッドを持つため、データの整形や変換が可能ですが、その複雑さのためにデータの整形や変換ができないこともあります。それは二刀流の剣です。
そのため、Pandasの最も一般的で便利な関数とメソッドを探求していきます。これを知ることで、Pandasを学ぶ他の初心者よりも先んじることができます。
この論文全体で疑似データセットを利用します。
最初のステップは、pandasをpdとしてインポートすることです。これはpandasをインポートするためのベストプラクティスの一つであり、pdはpandasのよく知られた略称です。
- 1日に150億のログを処理し、ビッグクエリを1秒以内に完了させる方法
- 「ブラックボックスの解除:ディープニューラルネットワークにおけるデータ処理の理解のための定量的法則」
- 「トップデータプライバシーツール2023」
import pandas as pdデータのインポート
データの操作を行う前に、データをインポートする必要があります。 read_csv()関数はPandasのDataFrameにデータセットを読み込むためのエントリーポイントです。ファイルパスを指定することで、この関数はデータを生き返らせ、データの探索と分析を始めることができます。
インポートするには、以下の構文に従い、データセットのファイルパスを入力します。
In[*] car_sales = pd.read_csv("./data/car-sales.csv") car_sales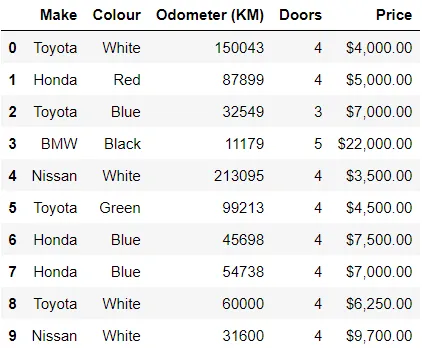
データの一部を見る
DataFrameの最初の数行または最後の数行について知りたいですか? head()と tail()は、データセットの構造と内容を評価するのに役立つ、簡単な一部を提供します。データ変換に入る前の予備的な理解に理想的です。表示したいアイテム数を指定するために、head(9)やtail(9)に引数を入力することができます。デフォルトは5つのアイテムです。
<p例を示すために、以下にコードの入力と出力を示します。
In[*] car_sales.head()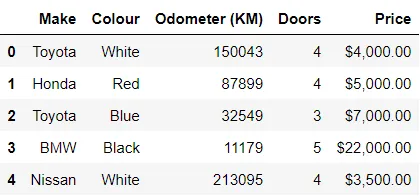
In[*] car_sales.tail()
データを完全に理解する
info()関数はデータの探偵です。データフレームの非nullエントリ数、データ型、メモリ使用量など、包括的なサマリーを提供します。このクイックな概要は、データのクリーニングと準備の取り組みをガイドすることができます。
In[*] car_sales.info()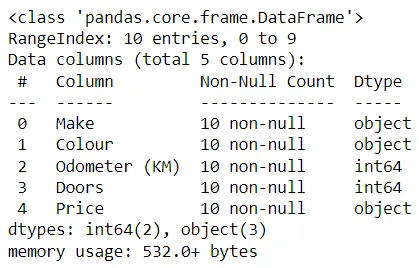
記述統計を解明する
統計的な洞察は、関数のひとつ先にあります。 describe()関数は、平均、中央値、最小値、最大値、四分位数を含む、多くの記述統計情報を提供します。数値データの分布のスナップショットを取得し、潜在的な外れ値を見つけることができます。ただし、describe()は意味のある情報を表示しない場合があります。それは常にデータセットに依存します。
In[*] car_sales.describe()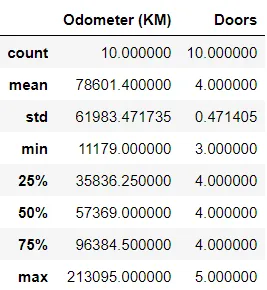
インサイトへのグループ化
特定の属性でグループ化されたデータは、より豊かなストーリーを伝えることがあります。 groupby() 関数は、データを特定の列に基づいてセグメント化することを可能にし、データセット内のトレンドを集計、要約、可視化するための重要なツールです。
In[*] car_sales.groupby(["Make"]).mean()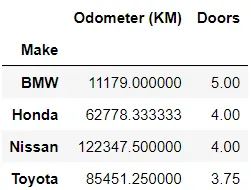
カスタム変換の強化
時には、既製の関数だけでは十分ではありません。 apply() 関数を使用すると、カスタム関数をデータに適用する自由が得られます。 この柔軟性により、特定のニーズに合わせたデータ変換やクリーニングが可能になります。
この例では、価格の $、,、および .00 を削除し、意味のある関数を実行するために int に変換するために lambda 関数を適用します。 価格の BEFORE と AFTER を参照してください。
In[*] car_sales["Price"] = car_sales["Price"].apply (lambda x: x.replace(".00", '')).str.replace('[\$\,]', '').astype(int) car_sales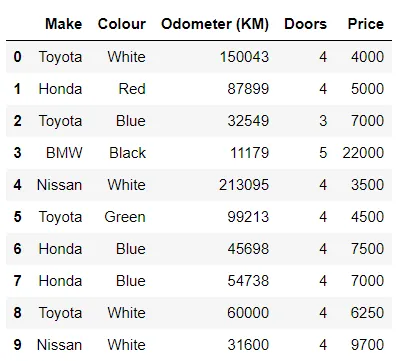
欠損データの処理
欠損データの処理は一般的な課題です。 fillna() 関数を使用すると、欠損値を置き換えることができ、 dropna() 関数を使用すると、欠損データを含む行または列を削除することができます。 これらの関数により、分析が完全かつ正確な情報に基づいて行われます。
例として、欠損データが含まれる新しいデータセットをインポートしましょう。
In[*] car_sales_missing = pd.read_csv("./data/car-sales-missing-data.csv") car_sales_missing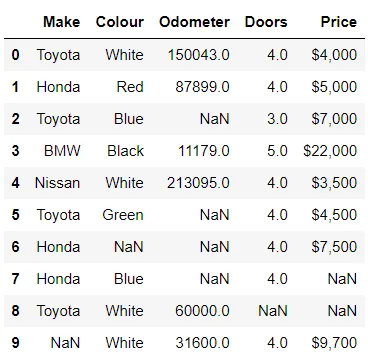
明らかに、Odometer の一部のデータには NaN の値があります。これを使用して、 fillna() を使って Odometer の欠損値を平均値で埋めます。
In[*] car_sales_missing["Odometer"] = car_sales_missing["Odometer"].fillna(car_sales_missing["Odometer"].mean())
今、Colours、Doors、および Price は NaN のみで、それぞれインデックス 6、7、8、9 にあります。 dropna() を使用して NaN を含む行と列を削除します。
In[*] car_sales_missing = car_sales_missing.dropna() car_sales_missing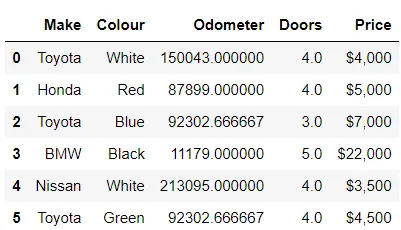
Pandasは単なるライブラリ以上のものであり、効果的なデータ操作と分析のゲートウェイです。 これらの重要な関数を備えていることで、現実世界のデータの課題や機械学習の問題に自信を持って取り組むことができます。 データサイエンティスト、アナリスト、または機械学習エンジニアであるかどうかに関係なく、Pandasはメッセージなデータセットを価値あるインサイトに変換する力を与えてくれます。 ですから、潜入して、実験して、Pandasの無限の可能性をデータ駆動の取り組みに解放してください。
好奇心を持ち続けて、分析的な思考を刺激し続けましょう!
Pandasについてもっと探求したい場合は、公式のドキュメンテーションを参照してみてください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
