パンダのコピー・オン・ライトモードの詳細な調査:パートI
パンダのコピー・オン・ライトモードの調査:パートI
内部でCopy-on-Writeがどのように動作するかを説明する

イントロダクション
pandas 2.0は4月初旬にリリースされ、新しいCopy-on-Write(CoW)モードに多くの改善がもたらされました。この機能は、現時点では2024年4月に予定されているpandas 3.0でデフォルトになることが予想されています。レガシーまたは非CoWモードの予定はありません。
この連載では、Copy-on-Writeが内部でどのように動作するかを説明し、ユーザーが何が起こっているかを理解し、効果的に使用する方法を示し、コードを適応する方法を説明します。これには、メカニズムを最も効率的に利用するための例や、余分なボトルネックを引き起こすいくつかのアンチパターンも示されます。数ヶ月前にCopy-on-Writeについての短いイントロダクションを書きました。
pandasのデータ構造を説明する短い記事も書きました。これにより、CoWに必要な用語を理解するのに役立ちます。
私はpandasのコアチームの一員であり、これまでにCoWの実装と改善に大いに関与してきました。私はCoiledのオープンソースエンジニアであり、Daskに取り組んでおり、pandasとの統合を改善し、DaskがCoWに準拠していることを保証しています。
Copy-on-Writeがpandasの動作を変更する方法
多くの方は、pandasの次の注意点についておなじみかもしれません:
import pandas as pdf = pd.DataFrame({"student_id": [1, 2, 3], "grade": ["A", "C", "D"]})grade列を選択して、最初の行を"E"で上書きしましょう。
grades = df["grade"]grades.iloc[0] = "E"df student_id grade0 1 E1 2 C2 3 D残念ながら、これによりgradesだけでなくdfも更新され、見つけにくいバグが発生する可能性があります。CoWではこの動作は許可されず、dfのみが更新されるようになります。また、ここでは役に立たないSettingWithCopyWarningも表示されます。
何もしないChainedIndexingの例を見てみましょう:
df[df["student_id"] > 2]["grades"] = "F"df student_id grade0 1 A1 2 C2 3 Dこの例でもSettingWithCopyWarningが表示されますが、dfには何も起こりません。これらのすべての注意点は、pandasが内部で使用しているNumPyのコピーとビュールールに帰結します。pandasのユーザーは、これらのルールとpandasのDataFrameに適用される方法を理解するために、類似のコードパターンでも異なる結果が生じる理由を理解する必要があります。
CoWはこれらの不整合をすべて解消します。CoWが有効な場合、ユーザーは一度に1つのオブジェクトのみを更新できます。例えば、最初の例ではgradesのみが更新されるため、dfは変更されません。2つのオブジェクトを同時に更新することはできなくなり、例えば、前のオブジェクトのコピーとして動作するようになります。
これらのケースは他にも多くありますが、すべてを詳しく説明することはここでは範囲外です。
動作原理
Copy-on-Writeについて詳しく見て、知っておくと良いいくつかの事実を強調します。これがこの記事のメインパートであり、かなり技術的な内容です。
Copy-on-Writeは、どのような方法であれ、別のDataFrameまたはSeriesから派生した場合、常にコピーとして振る舞うことを約束します。つまり、1つの操作で複数のオブジェクトを修正することはできません。たとえば、最初の例ではgradesのみが修正されます。
非常に防御的なアプローチは、DataFrameとそのデータをすべての操作でコピーすることです。これにより、pandasのビューを完全に回避できます。これにより、CoWセマンティクスが保証されますが、大きなパフォーマンスペナルティが発生するため、実行可能なオプションではありませんでした。
次に、1つの操作で複数のオブジェクトが更新されないようにするメカニズムについて詳しく説明します。また、データが不必要にコピーされないようにします。これが実装を興味深くする要素です。
必要ないコピーを避けるために、コピーをトリガーするタイミングを正確に把握する必要があります。1つのpandasオブジェクトの値を変更する場合にのみ、潜在的なコピーが必要です。このオブジェクトのデータが他のpandasオブジェクトと共有されている場合、コピーをトリガーする必要があります。つまり、1つのNumPy配列が2つのDataFramesによって参照されているかどうかを把握する必要があります(一般的には、1つのNumPy配列が2つのpandasオブジェクトによって参照されているかどうかを把握する必要がありますが、簡単さのためにDataFrameという用語を使用します)。
df = pd.DataFrame({"student_id": [1, 2, 3], "grade": [1, 2, 3]})df2 = df[:]このステートメントはDataFrame df とそのDataFrameのビュー df2 を作成します。ビューとは、両方のDataFrameが同じ基礎となるNumPy配列をバックアップしていることを意味します。CoWで見ると、df は df2 が自身のNumPy配列を参照していることを知る必要があります。ただし、これだけでは不十分です。 df2 も df が自身のNumPy配列を参照していることを知る必要があります。両方のオブジェクトが同じNumPy配列を参照している別のDataFrameが存在することを認識している場合、いずれかのオブジェクトが変更された場合にコピーをトリガーできます。たとえば、次のように:
df.iloc[0, 0] = 100ここではdfがインプレースで変更されます。 dfは、同じデータを参照する別のオブジェクトが存在することを知っているため、コピーをトリガーします。どのオブジェクトが同じデータを参照しているかは知りませんが、他のオブジェクトが存在することだけを知っています。
これを達成する方法を見てみましょう。この情報を保持するために、内部クラスBlockValuesRefsを作成しました。これは、特定のNumPy配列を参照するすべてのDataFramesを指します。
次の3つの操作でDataFrameを作成できます:
- 外部データからDataFrameが作成される場合、
pd.DataFrame(...)やI/Oメソッドを介して作成されます。 - 元のデータのコピーをトリガーするpandasの操作によって新しいDataFrameが作成される場合、ほとんどの場合
dropnaがコピーを作成します。 - pandasの操作によって元のデータのコピーがトリガーされない場合に新しいDataFrameが作成される場合、例:
df2 = df.reset_index()。
最初の2つのケースは簡単です。DataFrameが作成されるとき、それをバックアップするNumPy配列は新しいBlockValuesRefsオブジェクトに接続されます。これらの配列は新しいオブジェクトにのみ参照されるため、他のオブジェクトの追跡は必要ありません。オブジェクトは、NumPy配列を包むBlockを指すweakrefを作成し、この参照を内部的に保存します。ブロックの概念についてはこちらをご覧ください。
weakrefは、Pythonオブジェクトへの参照を作成します。通常、オブジェクトがスコープを抜けるときにこのオブジェクトを生きたままにはしません。
import weakrefclass Dummy: def __init__(self, a): self.a = aIn[1]: obj = Dummy(1)In[2]: ref = weakref.ref(obj)In[3]: ref()Out[3]: <__main__.Dummy object at 0x108187d60>In[4]: obj = Dummy(2)この例では、Dummyオブジェクトとそのオブジェクトへの弱い参照が作成されます。その後、同じ変数に別のオブジェクト、つまり初期オブジェクトがスコープを抜けてガベージコレクトされます。弱い参照はこのプロセスに干渉しません。弱い参照を解決すると、元のオブジェクトではなく
Noneを指すようになります。
In[5]: ref()Out[5]: Noneこれにより、ガベージコレクションされるはずの配列を保持しないようにしています。
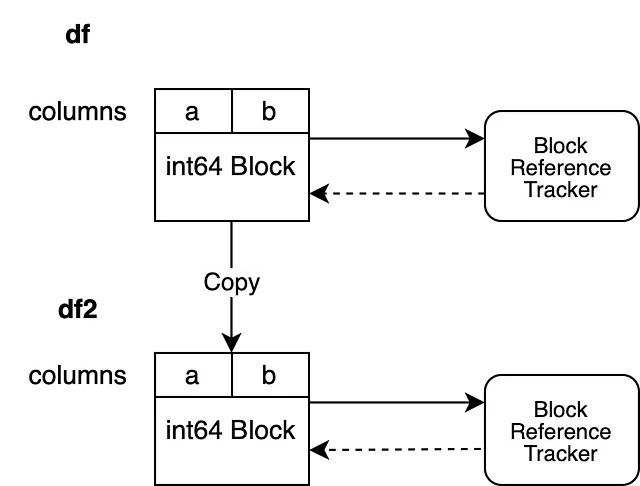
これらのオブジェクトがどのように組織されているかを見てみましょう:
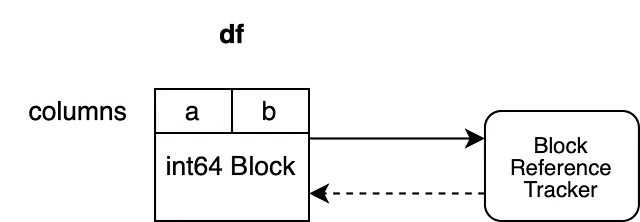
この例では、"a" と "b" の2つの列があり、どちらも "int64" のdtypeを持っています。これらの列は、データを保持するための1つのブロックによってバックアップされています。ブロックは、ブロックがガベージコレクションされない限り、参照トラッキングオブジェクトへのハードリファレンスを保持しています。参照トラッキングオブジェクトは、ブロックへの弱い参照を保持しています。これにより、オブジェクトはこのブロックのライフサイクルを追跡することができますが、ガベージコレクションは防ぎません。参照トラッキングオブジェクトは、まだ他のブロックへの弱い参照を保持していません。
これらは簡単なシナリオです。他の pandas オブジェクトが同じ NumPy 配列を共有していないことがわかっているため、単純に新しい参照トラッキングオブジェクトをインスタンス化することができます。
3番目のケースは少し複雑です。新しいオブジェクトは元のオブジェクトと同じデータを表示しています。つまり、両方のオブジェクトが同じメモリを指しています。この操作により、同じ NumPy 配列を参照する新しいブロックが作成されます。これを浅いコピーと呼びます。この新しいブロックを参照トラッキングメカニズムに登録する必要があります。新しいブロックを、古いオブジェクトに接続されている参照トラッキングオブジェクトに登録します。
df2 = df.reset_index(drop=True)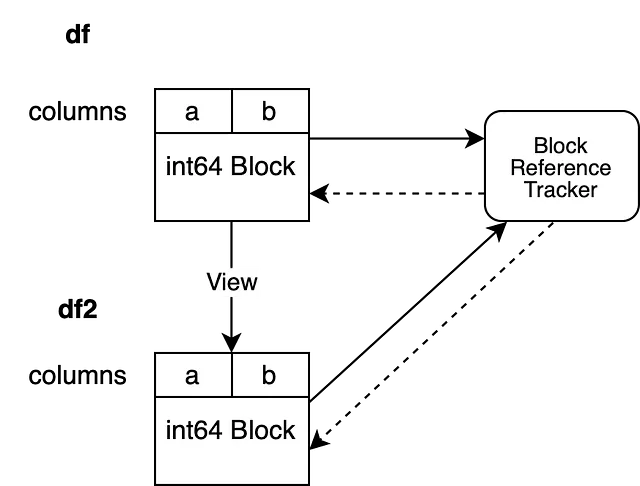
私たちの BlockValuesRefs は、最初の df をバックアップするブロックと df2 をバックアップする新しく作成されたブロックを指しています。これにより、同じメモリを指すすべての DataFrame について常に認識することができます。
これで、同じ NumPy 配列を参照する複数のブロックが生存しているかどうかを参照トラッキングオブジェクトに尋ねることができます。参照トラッキングオブジェクトは弱い参照を評価し、複数のオブジェクトが同じデータを参照していることを教えてくれます。これにより、それらのいずれかが場所を変更した場合に内部的にコピーをトリガーできます。
df2.iloc[0, 0] = 100df2 のブロックはディープコピーを介してコピーされ、独自のデータと参照トラッキングオブジェクトを持つ新しいブロックが作成されます。元の df2 をバックアップしていたブロックはガベージコレクションされることができるため、df と df2 のバックアップ配列はメモリを共有しません。
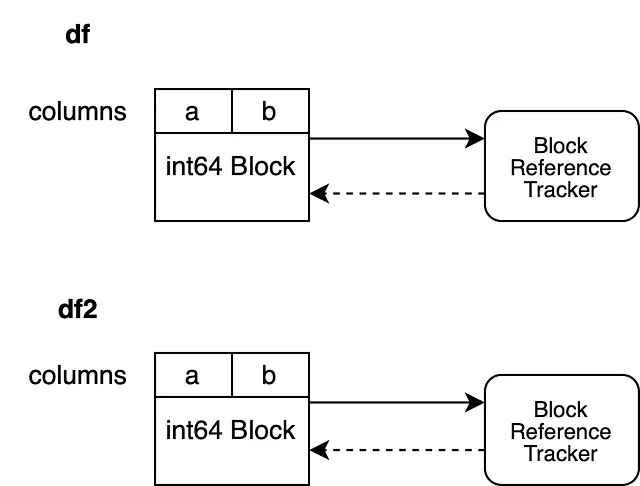
別のシナリオを見てみましょう。
df = Nonedf2.iloc[0, 0] = 100変更する前に df が無効になるため、df をバックアップしていたブロックを指す参照トラッキングオブジェクトの弱参照は None と評価されます。これにより、コピーをトリガーせずに df2 を変更することができます。
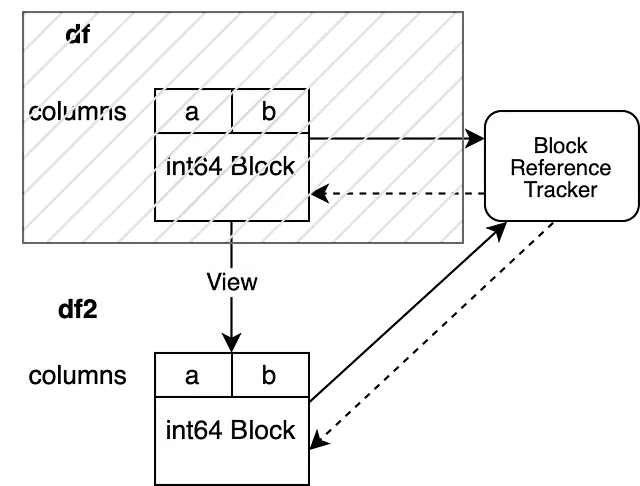
参照トラッキングオブジェクトは1つだけの DataFrame を指しているため、コピーをトリガーせずに操作をインプレースで実行することができます。
上記の reset_index はビューを作成します。内部的にコピーをトリガーする操作がある場合、メカニズムは少し単純化されます。
df2 = df.copy()これにより、DataFrame df2 のための新しい参照トラッキングオブジェクトがすぐにインスタンス化されます。
結論
Copy-on-Writeのトラッキングメカニズムがどのように機能し、いつコピーがトリガーされるのかを調査しました。このメカニズムは、非CoWの動作とはかなり異なり、パンダは可能な限りコピーを遅延させます。参照トラッキングメカニズムは、メモリを共有するすべてのDataFrameを追跡し、パンダでより一貫した動作を可能にします。
このシリーズの次の部分では、このメカニズムをより効率的にするために使用されるテクニックについて説明します。
読んでいただきありがとうございました。Copy-on-Writeに関するご意見やフィードバックをお寄せください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- VoAGIニュース、8月9日:ChatGPTを忘れて、この新しいAIアシスタントは遥かに進んでいます•データクリーニングと前処理技術の習得のための7つのステップ
- 「AIがキーストロークを聞く:新たなデータセキュリティの脅威」
- 「2つのPandas DataFrameを比較するための簡単な方法3つ」
- マシンラーニングエンジニアは、実際に何をしているのでしょうか?
- RecList 2.0 オープンソースによるMLモデルの体系的なテストシステム
- 「HaystackにおけるRAGパイプラインの拡張 DiversityRankerとLostInTheMiddleRankerの紹介」
- 「NVIDIA H100 Tensor Core GPUを使用した新しいMicrosoft Azure仮想マシンシリーズが一般利用可能になりました」
