13分でハミルトンを使用したメンテナブルでモジュラーなLLMアプリケーションスタックの構築
ハミルトンを使用した13分のメンテナブルなLLMアプリケーションスタックの構築
LLMアプリケーションはデータフローです。それらを表現するために特別に設計されたツールを使用してください

この投稿はThierry Jean氏との共同執筆であり、元の記事はこちらに掲載されています。
この投稿では、オープンソースのフレームワークであるHamiltonが、大規模言語モデル(LLM)アプリケーションスタックのモジュラーでメンテナブルなコードの記述にどのように役立つかを共有します。Hamiltonは、LLMパワードアプリケーションの構築時に行っているデータフローの記述に適しています。Hamiltonを使用すると、アプリケーションのコンポーネントの異なるプロバイダ/実装を簡単に切り替えて評価することができるため、堅牢なソフトウェアメンテナンスのエルゴノミクスを得ることができます。免責事項:私はHamiltonパッケージの著者の一人です。
以下の例では、テキストの知識をベクトルデータベースに入力するために実行される典型的なLLMアプリケーションワークフローを紹介します。具体的には、ウェブからデータを取得し、テキスト埋め込み(ベクトル)を作成し、それらをベクトルストアにプッシュする方法について説明します。
LLMアプリケーションのデータフロー
まず、典型的なLLMデータフローがどのようなものか説明しましょう。アプリケーションは小さなデータ入力(テキスト、コマンドなど)を受け取り、より大きなコンテキスト(チャット履歴、ドキュメント、状態など)内で操作します。このデータは異なるサービス(LLM、ベクトルデータベース、ドキュメントストアなど)を通じて移動し、操作を実行し、新しいデータアーティファクトを生成し、最終結果を返します。ほとんどのユースケースでは、異なる入力に対して反復しながら、このフローを複数回繰り返します。
一部の一般的な操作には、以下があります:
- テキストを埋め込みに変換する
- 埋め込みを保存/検索/取得する
- 埋め込みに最も近い隣接点を見つける
- 埋め込みのテキストを取得する
- プロンプトに渡すために必要なコンテキストを決定する
- 関連テキストのコンテキストでモデルをプロンプトする
- 結果を別のサービス(API、データベースなど)に送信する
- …
- それらを連鎖させる!
さて、これを本番環境の文脈で考えてみましょう。ユーザーがアプリケーションの出力に満足していない場合、問題の原因を特定したいとします。アプリケーションはプロンプトと結果の両方をログに記録しています。コードを使用して操作のシーケンスを特定できます。しかし、どこで問題が発生し、システムが望ましくない出力を生成したのかが全くわかりません… そのためには、データアーティファクトの起源とそれらを生成するコードを追跡することが重要です。これにより、このような状況を素早くデバッグすることができます。
LLMアプリケーションデータフローの複雑さを増すために、多くの操作は非決定論的です。つまり、同じ入力と設定にアクセスできる場合でも、テキストや画像の応答を生成するためのAPI呼び出しは再現不可能です(温度などのオプションで一部を緩和できます)。これは、「最も近い」などの特定のベクトルデータベース操作にも適用されます。本番環境では、コールを再現可能にするためにデータベースの状態をスナップショットすることは困難です。
これらの理由から、以下のような柔軟なツールを採用することが重要です。これにより、以下のことが可能になります:
- さまざまなコンポーネントを簡単にプラグインできる。
- コンポーネント同士の接続方法を確認できる。
- キャッシュ、検証、監視などの一般的な本番ニーズを追加してカスタマイズできる。
- 強力なエンジニアリングスキルセットを必要とせずに、フローの構造をニーズに合わせて調整できる。
- 伝統的なデータ処理と機械学習エコシステムに接続できる。
この投稿では、Hamiltonがポイント1、2、および4を満たす方法の概要を説明します。ポイント3および5については、ドキュメントを参照してください。
現在のLLMアプリケーション開発ツール
LLMスペースはまだ初期段階であり、使用パターンとツールは急速に進化しています。LLMフレームワークを使用することで開始できますが、現在のオプションは本番テストされていません。私たちの知る限り、既成のテック企業は現在の人気のあるLLMフレームワークを本番で使用していません。
言いたいことは、一部のツールはクイックな概念実証のために素晴らしいものです!ただし、2つの特定の領域で不十分だと考えています:
1. LLMアプリケーションのデータフローをモデル化する方法。私たちは、データフローの「アクション」をオブジェクト指向のクラスとライフサイクルではなく、関数としてモデル化することが最善だと強く信じています。関数は、理解、テスト、変更がはるかに簡単です。オブジェクト指向のクラスは非常に不透明になり、より多くの精神的負担を強いる可能性があります。
何かエラーが発生した場合、オブジェクト指向のフレームワークではオブジェクトのソースコードにまで掘り下げて理解する必要があります。一方、Hamilton関数では、明確な依存関係の系譜があり、どこを見るべきかを示し、何が起こったかを理解するのに役立ちます(以下で詳しく説明します)!
2. カスタマイズ/拡張。残念ながら、現在のフレームワークを変更するには強力なソフトウェアエンジニアリングのスキルセットが必要です。それが選択肢でない場合、特定のカスタムビジネスロジックのためにフレームワークの範囲外に出ることになり、結果として最初からフレームワークを使用しない場合よりもコードの表面積を維持することになります。
これらの2つのポイントについて詳しくは、ユーザーが詳しく話す以下のスレッド(ハッカーニュース、reddit)などを参照してください。
Hamiltonは現行のLLMフレームワークの完全な置換ではありません(たとえば、「エージェント」コンポーネントはありません)。ただし、LLMアプリケーションのニーズを満たすためのすべてのビルディングブロックを備えており、両方を併用できます。クリーンで明確でカスタマイズ可能な方法で本番コードを記述し、複数のLLMスタックコンポーネントを統合し、アプリケーションの可観測性を向上させるならば、次の数節に進みましょう!
Hamiltonを使用してビルドする
HamiltonはPythonでデータフローを記述するための宣言的なマイクロフレームワークです。それは新しいフレームワークではありません(3.5年以上前から存在しています)し、データモデリングと機械学習のデータフローの作成に長年使用されています。その強みは、データと計算のフローを作成および維持するのに非常に直感的な方法で表現できることです(SQLのようにDBTが行うのと同様)、これはLLMアプリケーションのデータと計算ニーズのモデリングをサポートするのに非常に適しています。
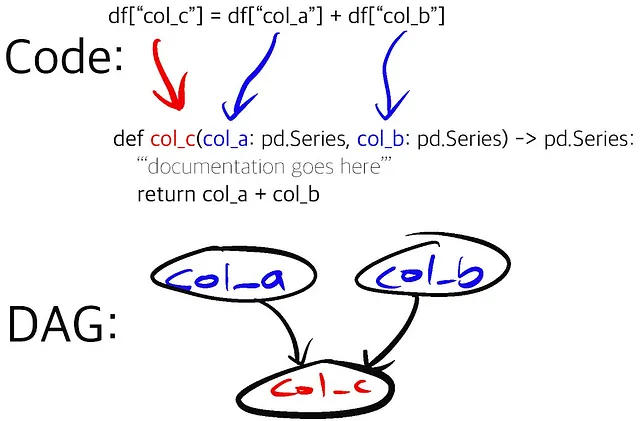
Hamiltonの基本はシンプルであり、さまざまな方法で拡張することができます。この投稿から価値を得るためにHamiltonを知る必要はありませんが、興味がある場合は以下をチェックしてください:
- tryhamilton.dev – ブラウザでの対話的なチュートリアル!
- HamiltonでのPandasデータ変換(5分)
- Lineage + Hamilton(10分)
- 本番用のHamilton + Airflow
私たちの例に移りましょう
いくつかのメンタルコンテキストを設定するために、次のような状況を想像してください。組織の文書と「チャット」するLLMアプリケーションを作成する小さなデータチームです。機能、パフォーマンスプロファイル、ライセンス、インフラ要件、コストの観点で候補アーキテクチャを評価することが重要だと考えています。最終的に、組織の主な関心事は最も関連性の高い結果と優れたユーザーエクスペリエンスを提供することです。これを評価する最良の方法は、プロトタイプを構築し、異なるスタックをテストし、その特性と出力を比較することです。その後、本番に移行する際には、システムが維持され、簡単に内省できることで、常に優れたユーザーエクスペリエンスを提供できることを確信したいと思います。
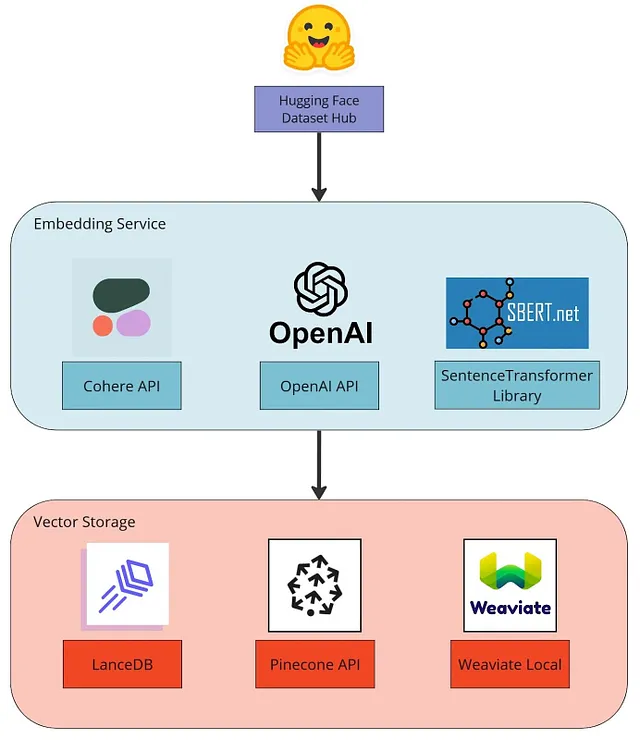
これを念頭に置いて、この例ではLLMアプリケーションの一部を実装します。具体的には、テキストをエンベディングに変換し、それらをベクトルデータベースに保存するデータインジェスチョンステップを実装します。これはいくつかの異なるサービス/テクノロジーを使用してモジュール化して実装します。全体の手順は次のとおりです:
- HuggingFace HubからSQuADデータセットをロードします。これは事前処理済みのドキュメントのコーパスに置き換える必要があります。
- Cohere API、OpenAI API、またはSentenceTransformerライブラリを使用してテキストエントリをエンベディングします。
- LanceDB、Pinecone、またはWeaviateのいずれかのベクトルデータベースにエンベディングを保存します。
埋め込みと検索について詳しく知りたい場合は、次のリンクを参照してください:
- テキスト埋め込みの説明 – Weaviate
- Pineconeを使用したセマンティックサーチの方法
この例を進めるにあたり、以下のことを考えて/念頭に置いておくと役立つでしょう:
- 私たちがお見せするものと、現在行っていることを比較してください。 Hamiltonがどのようにプロジェクトをキュレーションし、構造化することなく、明示的なLLM中心のフレームワークを必要とせずにプロジェクトを構築できるかを確認してください。
- プロジェクトとアプリケーションの構造。 Hamiltonがどのようにモジュラースタックの構築とメンテナンスを可能にする構造を強制するかを理解してください。
- 反復とプロジェクトの持続性への自信。 上記の2つのポイントを組み合わせることで、Hamiltonは誰が作成したかに関係なく、LLMアプリケーションをより簡単に本番環境で維持できるようにします。
まずは、概要を示す可視化から始めましょう:
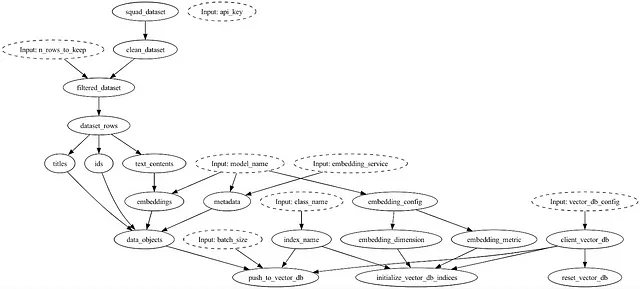
PineconeとSentence transformersを使用した場合のLLMアプリケーションのデータフローは、Hamiltonを使用すると、Hamiltonドライバオブジェクトのdisplay_all_functions()呼び出しと同じくらい簡単に接続関係を理解することができます。
モジュラーコード
コンテキストを持って、Hamiltonを使用してモジュラーコードを実装する2つの主要な方法を説明します。
@config.when
Hamiltonの焦点は可読性にあります。 @config.whenが何をするかを説明せずに、これが条件付きステートメントであり、条件を満たす場合にのみ含まれることがわかるでしょう。以下に、OpenAIとCohere APIを使用してテキストをエンベディングするための実装を示します。
@config.whenデコレータと同じ関数名embeddings(__cohere、__openai)のため、Hamiltonは2つの関数を代替実装として認識します。これらの関数のシグネチャは完全に同じである必要はありませんが、異なる実装を採用することは簡単で明確です。
embedding_module.py
このプロジェクトでは、3つの関数が各サービスごとに実装されているため、@config.whenデコレータを使用して同じファイルにすべての埋め込みサービスを実装することが合理的でした。ただし、プロジェクトが複雑になるにつれて、関数を別々のモジュールに移動し、次のセクションのモジュラリティパターンを代わりに使用することもできます。また、これらの関数のそれぞれは独立してユニットテストが可能です。特定のニーズがある場合、関数内にカプセル化してテストすることは容易です。
Pythonモジュールの切り替え
以下に、PineconeとWeaviateのベクトルデータベース操作の実装があります。スニペットはpinecone_module.pyとweaviate_module.pyから取得されており、関数シグネチャの類似点と相違点に注目してください。
pinecone_module.pyとweaviate_module.py
Hamiltonでは、関数名と関数の入力引数を使用してデータフローを結びつけます。したがって、類似の操作に対して関数名を共有することにより、2つのモジュールは簡単に交換可能です。LanceDB、Pinecone、およびWeaviateの実装が別々のモジュールに存在するため、ファイルごとの依存関係の数が減り、ファイルが短くなり、可読性と保守性が向上します。各実装のロジックはこれらの名前付き関数に明確にカプセル化されているため、各モジュールごとにユニットテストを実装するのは簡単です。別々のモジュールは同時にロードされないことを強調するため、同じ名前の複数の関数が見つかった場合、Hamiltonドライバは実際にエラーをスローします。
ドライバーの影響
Hamiltonコードを実行するためのキーパートは、run.py内で見つかるDriverオブジェクトです。CLIや一部の引数の解析のコードを除いて、次のようになります:
run.pyのスニペット
Hamiltonドライバーは、上記のコードスニペットで確認できるように、以下の3つの仕組みを介してモジュラリティを提供します:
- ドライバーの設定。これは、ドライバーがインスタンス化時に受け取る定数である辞書であり、使用するAPIや埋め込みサービスAPIキーなどの情報を含んでいます。これは、JSONや文字列(たとえば、Dockerコンテナ、Airflow、Metaflowなど)を渡すことができるコマンドプレーンと統合されます。具体的には、どの埋め込みAPIを使用するかを指定する場所です。
- ドライバーモジュール。ドライバーは、データフローを構築するための任意の数の独立したPythonモジュールを受け取ることができます。ここでは、
vector_db_moduleを所望のベクトルデータベースの実装に交換することができます。また、importlibを使用してモジュールを動的にインポートすることもできます。これは開発と本番のコンテキストの違いに便利であり、データフローの実装を変更するための設定駆動型の方法を可能にします。 - ドライバーの実行。
final_varsパラメータは、どの出力を返すかを決定します。出力を取得するためにコードを再構築する必要はありません。たとえば、データフロー内の何かをデバッグしたい場合、final_varsにその関数の名前を追加することで、その出力を簡単にリクエストしたり、完全にその場で実行を停止したりすることが可能です。注意点として、ドライバーはexecute()を呼び出す際にinputsとoverridesの値を受け取ることができます。上記のコードでは、class_nameは実行時のinputであり、作成する埋め込みオブジェクトとそれをベクトルデータベースに格納する場所を示します。
モジュラリティの要約
Hamiltonでは、交換可能なコンポーネントを有効にするためのキーは次のとおりです:
- 同じ名前の関数を定義し、そして、
@config.whenでそれらに注釈を付け、ドライバーに渡される設定によって使用する関数を選択するか、- それらを別々のPythonモジュールに配置し、ドライバーに所望のモジュールを渡す。
これにより、Hamiltonを使用してさまざまなLLMコンポーネントをプラグイン、交換、呼び出す方法を示しました。オブジェクト指向の階層構造について説明する必要はありませんし、豊富なソフトウェアエンジニアリングの経験を持っている必要もありません(そう願っています!)。これを実現するために、関数名とその出力タイプを合わせるだけで十分です。この方法でコードを書き、モジュール化することは、現在のLLMフレームワークよりもアクセスしやすいと考えています。
実践的なHamiltonコード
主張に加えて、私たちが観察したLLMワークフローのHamiltonコードのいくつかの実践的な影響を以下に示します:
CI/CD
モジュール/@config.whenを交換/分離できる能力は、CIシステムでの統合テストを考える際にも簡単です。
コラボレーション
- Hamiltonが可能にするモジュラリティは、チーム間の境界を簡単に反映させることができます。関数の名前とその出力タイプは契約となり、手術的な変更を行い、変更に自信を持つことができます。また、Hamiltonの可視化機能やラインエージング機能(最初の可視化を見たような)によって、下流の依存関係を把握することもできます。たとえば、ベクトルデータベースからの相互作用や消費方法が明確です。
- コードの変更は、宣言的な関数によって定義されているため、レビューが簡単です。変更は自己完結しています。学ぶべきオブジェクト指向の階層構造はなく、修正するのは関数だけです。Hamiltonによって、「カスタム」なものは事実上サポートされます。
デバッグ
Hamiltonにエラーがある場合、それがマップされるコードや、関数がどのように定義されているかについては明確です。関数がどのデータフローに適合するかも分かります。
埋め込み関数を使用している場合のシンプルな例を考えてみましょう。タイムアウトが発生したり、応答の解析でエラーが発生した場合、それがこのコードにマップされることは明確であり、関数の定義から、フロー内のどこにフィットするかが分かります。
@config.when(embedding_service="cohere")def embeddings__cohere( embedding_provider: cohere.Client, text_contents: list[str], model_name: str = "embed-english-light-v2.0",) -> list[np.ndarray]: """Cohere Embed APIを使用して、テキストをベクトル表現(埋め込み)に変換します。 参考: https://docs.cohere.com/reference/embed """ response = embedding_provider.embed( texts=text_contents, model=model_name, truncate="END", ) return [np.asarray(embedding) for embedding in response.embeddings]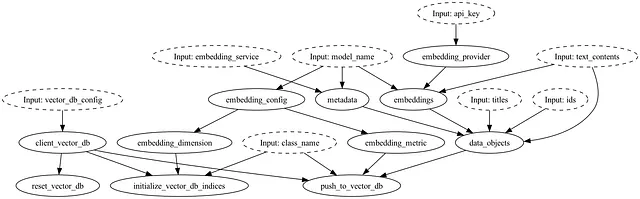
モジュラーなLLMスタックの作成に役立つヒント
終わる前に、アプリケーションの構築をガイドするいくつかのアイデアを紹介します。いくつかの決定には明らかな最良の選択肢がないかもしれませんが、適切なモジュラリティのアプローチを持つことで、要件が進化するにつれて効率的にイテレーションすることができます。
- コードを書く前に、ワークフローの論理的なステップのDAGを描きます。これにより、サービス固有でない共通のステップとインターフェースを定義する基盤が築かれます。
- 交換可能なステップを特定します。設定ポイントを目的意識に活用することで、仮説的な汎用性のリスクを減らすことができます。具体的には、引数が少なく、デフォルト値があり、テーマごとにまとめられた関数になります。
- 関連する場合は、データフローの一部を依存関係の少ないモジュールに分割します。これにより、パッケージの依存関係が少なくなり、読みやすさと保守性が向上します。Hamiltonは無関心であり、複数のモジュールからDAGを構築することができます。
クローズと将来の方向性
ここまで読んでいただき、ありがとうございます。私たちは、Hamiltonがデータフローの表現を助けるのに役立つと考えています。LLMアプリケーションはその1つの使用例です!この記事のメッセージを要約すると以下のようになります:
- LLMアプリケーションをデータフローとして捉えることは有用であり、Hamiltonの使用に適しています。
- オブジェクト指向のLLMフレームワークは、プロダクションのニーズに合わせて拡張や保守が難しく、不透明になることがあります。その代わりに、Hamiltonの明確な宣言的スタイルで独自の統合を作成するべきです。これにより、コードの透明性と保守性が向上し、テスト可能な関数、ランタイムエラーと関数の明確なマッピング、データフローの組み込みの視覚化が実現されます。
- Hamiltonのモジュラリティにより、コラボレーションが効率化され、LLMワークフローの変更と修正が迅速に行える柔軟性が得られます。
ここで、こちらで完全な例を試したり、変更したりしてみることをお勧めします。実行するコマンドと開始方法について説明したREADMEがあります。それ以外にも、以下の点についてHamilton + LLMアプリケーションの体験をさらに向上させるために取り組んでいます:
- エージェント。 通常のHamiltonデータフローと同じレベルの可視性をエージェントに提供できるでしょうか?
- 並列化。 たとえば、ドキュメントのリスト上でデータフローを実行する方法を簡単に表現できるようにするにはどうすればよいでしょうか。意図するものを確認するための進行中のPRを参照してください。
- キャッシュと可観測性のためのプラグイン。 既にHamiltonの上にカスタムのキャッシュと可観測性のソリューションを実装することができます。より一般的なオプションを提供するために、例えばredisなどの共通コンポーネントに対して、より多くの標準オプションを提供する作業を進めています。
- ユーザーの貢献するデータフローのセクション。 特定のLLMアプリケーションの使用例に共通の名前を標準化する可能性があります。その場合、Hamiltonのデータフローを集約し、人々が必要に応じてそれらをダウンロードできるようにすることができます。
皆さまからのご意見をお聞かせください!
これらのいずれかに興味を持たれた場合や強い意見をお持ちの場合は、私たちのSlackチャンネルに立ち寄ってコメントを残してください!以下のリソースもお手伝いいたします:
📣 Slackのコミュニティに参加してください – 質問に答えたり、始めるお手伝いをするのに喜んでお手伝いいたします。
⭐️ GitHubで私たちをサポートしてください
</
📝 もし何か問題を見つけた場合は、問題を残してください
他にも興味があるかもしれないハミルトンの投稿:
- tryhamilton.dev – ブラウザでの対話型チュートリアル!
- 5分でのハミルトンでのPandasデータ変換
- 10分でのラインエージ + ハミルトン
- 本番用のハミルトン + Airflow
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
