初めてのDeep Q学習ベースの強化学習エージェントをトレーニングする:ステップバイステップガイド
トレーニング初心者向けのDeep Q学習ベースの強化学習エージェント:ステップバイステップガイド
イントロダクション:
強化学習(RL)は、環境との相互作用を通じて学習し、意思決定を行うことを可能にする、人工知能(AI)の魅力的な分野です。RLエージェントのトレーニングには、エージェントが行動およびその後の報酬またはペナルティを学習する試行錯誤のプロセスが含まれます。このブログでは、最初のRLエージェントのトレーニングに含まれる手順と、プロセスを説明するためのコードの断片を探求します。
ステップ1:環境の定義
RLエージェントをトレーニングする最初のステップは、エージェントが操作する環境を定義することです。環境はシミュレーションまたは現実世界のシナリオである場合があります。環境は、エージェントに観測と報酬を提供し、学習と意思決定を可能にします。 OpenAI Gymは、幅広い事前構築環境を提供する人気のあるPythonライブラリです。この例では、古典的な「CartPole」環境を考えてみましょう。
import gymenv = gym.make('CartPole-v1')ステップ2:エージェントと環境の相互作用の理解
RLでは、エージェントは観測に基づいて行動を取りながら環境と相互作用します。報酬またはペナルティという形でフィードバックを受け取り、学習プロセスをガイドします。エージェントの目標は、時間の経過とともに累積報酬を最大化することです。これを実現するために、エージェントはポリシー(観測から行動へのマッピング)を学習し、最善の意思決定を支援します。
ステップ3:RLアルゴリズムの選択
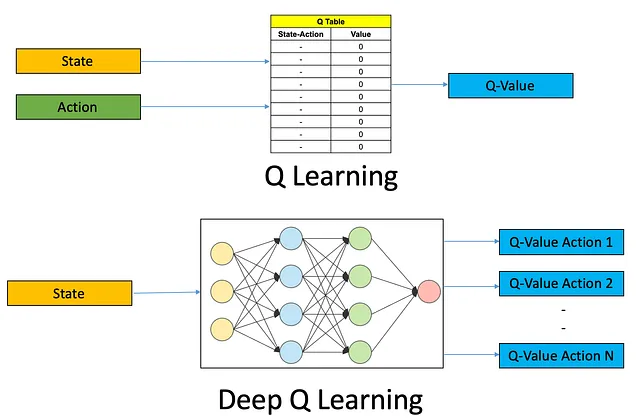
さまざまなRLアルゴリズムが利用可能であり、それぞれに固有の利点と欠点があります。一つの人気のあるアルゴリズムはQ学習であり、離散的な行動空間に適しています。もう一つよく使用されるアルゴリズムはDeep Q-Networks(DQN)であり、複雑な環境を処理するために深層ニューラルネットワークを利用します。この例では、DQNアルゴリズムを使用しましょう。
- ディープラーニングのためのPythonとC++による自動微分
- 「このGSAi中国のAI論文は、LLMベースの自律エージェントの包括的な研究を提案しています」
- 「人間と機械の対話を革新する:プロンプトエンジニアリングの出現」

ステップ4:RLエージェントの構築
DQNアルゴリズムを使用してRLエージェントを構築するには、関数近似器としてニューラルネットワークを定義する必要があります。ネットワークは観測を入力とし、各可能な行動に対するQ値を出力します。また、トレーニングのために経験を格納し、サンプリングするリプレイメモリを実装する必要があります。
import torchimport torch.nn as nnimport torch.optim as optimclass DQN(nn.Module): def __init__(self, input_dim, output_dim): super(DQN, self).__init__() self.fc1 = nn.Linear(input_dim, 64) self.fc2 = nn.Linear(64, 64) self.fc3 = nn.Linear(64, output_dim) def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x# DQNエージェントのインスタンスを作成するinput_dim = env.observation_space.shape[0]output_dim = env.action_space.nagent = DQN(input_dim, output_dim) ステップ5:RLエージェントのトレーニング
これで、DQNアルゴリズムを使用してRLエージェントをトレーニングすることができます。エージェントは環境と相互作用し、現在の状態を観測し、ポリシーに基づいて行動を選択し、報酬を受け取り、その後Q値を更新します。このプロセスは、指定されたエピソード数またはエージェントが満足のいくパフォーマンスレベルに達するまで繰り返されます。
optimizer = optim.Adam(agent.parameters(), lr=0.001)def train_agent(agent, env, episodes): for episode in range(episodes): state = env.reset() done = False episode_reward = 0 while not done: action = agent.select_action(state) next_state, reward, done, _ = env.step(action) agent.store_experience(state, action, reward, next_state, done) agent
結論:
このブログでは、最初の強化学習エージェントのトレーニングプロセスについて探求しました。まず、RLタスクのための事前構築環境を提供するOpenAI Gymを使用して環境を定義しました。次に、エージェントと環境の相互作用とエージェントの目標である累積報酬の最大化について議論しました。
次に、複雑な環境を扱うために、DQNアルゴリズムを強化学習アルゴリズムとして選びました。このアルゴリズムは、ディープニューラルネットワークとQ学習を組み合わせています。関数近似器としてニューラルネットワークを使用し、トレーニングのための経験を保存してサンプリングする再生メモリを実装し、RLエージェントを構築しました。
最後に、環境との相互作用を通じてRLエージェントをトレーニングし、状態を観察し、ポリシーに基づいてアクションを選択し、報酬を受け取り、Q値を更新しました。このプロセスは、指定されたエピソード数に対して繰り返され、エージェントが学習し、意思決定能力を向上させることができました。
強化学習は、動的な環境で自律的に学習し、意思決定することができる知能エージェントのトレーニングに対して、さまざまな可能性を開拓します。このブログで概説された手順に従って、RLエージェントのトレーニングとさまざまなアルゴリズム、環境、アプリケーションの探求の旅を始めることができます。
覚えておいてください、RLトレーニングには実験、微調整、忍耐が必要です。RLに深く入り込むにつれて、ディープRL、ポリシーグラデーション、マルチエージェントシステムなどの高度な技術を探求することができます。だから、学び続けて、反復し、RLエージェントが達成できる領域の限界を押し広げましょう。
トレーニングを楽しんでください!
LinkedIn: https://www.linkedin.com/in/smit-kumbhani-44b07615a/
私のGoogle Scholar: https://scholar.google.com/citations?hl=en&user=5KPzARoAAAAJ
「Pneumothorax検出とセグメンテーションのためのセマンティックセグメンテーション」に関するブログ https://medium.com/becoming-human/semantic-segmentation-for-pneumothorax-detection-segmentation-9b93629ba5fa

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles



