トランスフォーマーにおけるアテンションの説明【エンコーダーの観点から】
トランスフォーマーのアテンション【エンコーダー視点】の説明
この記事では、Transformerネットワークにおけるアテンションの概念について、特にエンコーダーの視点から詳しく説明します。以下のトピックをカバーします:
- 機械翻訳とは何か
- アテンションの必要性
- 再帰ニューラルネットワーク(RNN)を使用したアテンションの計算方法
- セルフアテンションとは何か、Transformerのエンコーダーを使用してどのように計算されるのか
- エンコーダーにおけるマルチヘッドアテンション
機械翻訳
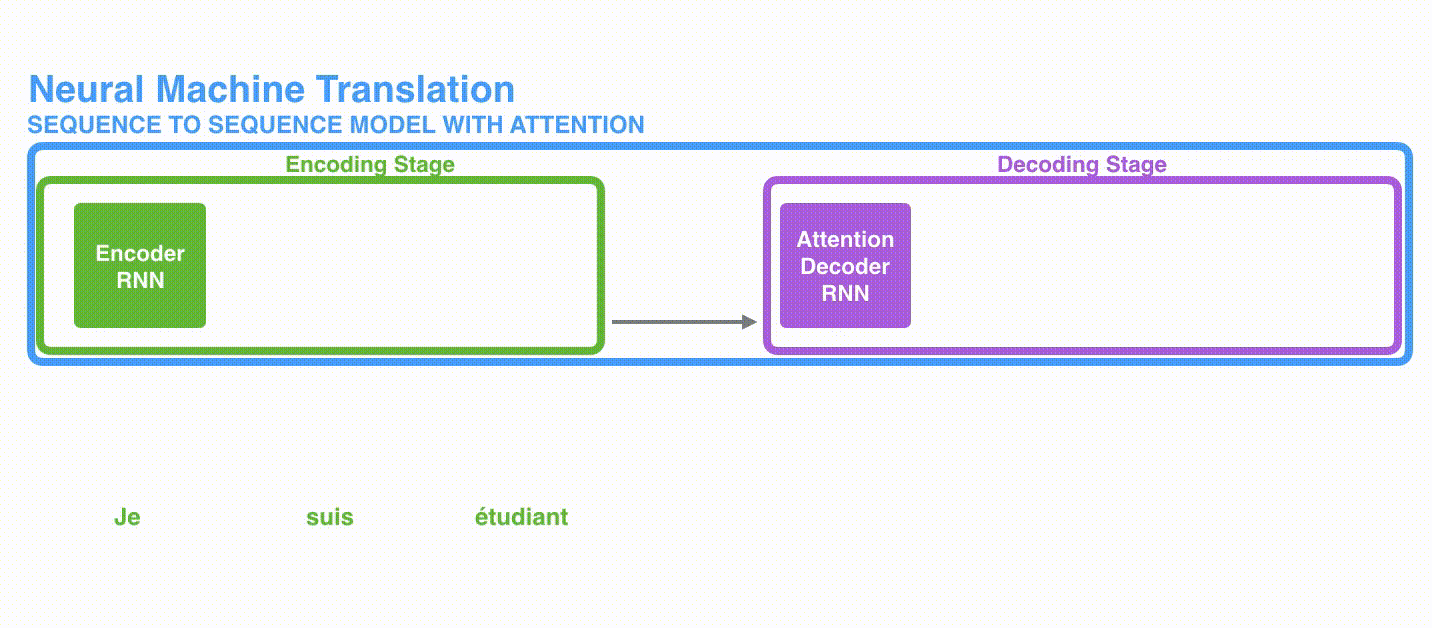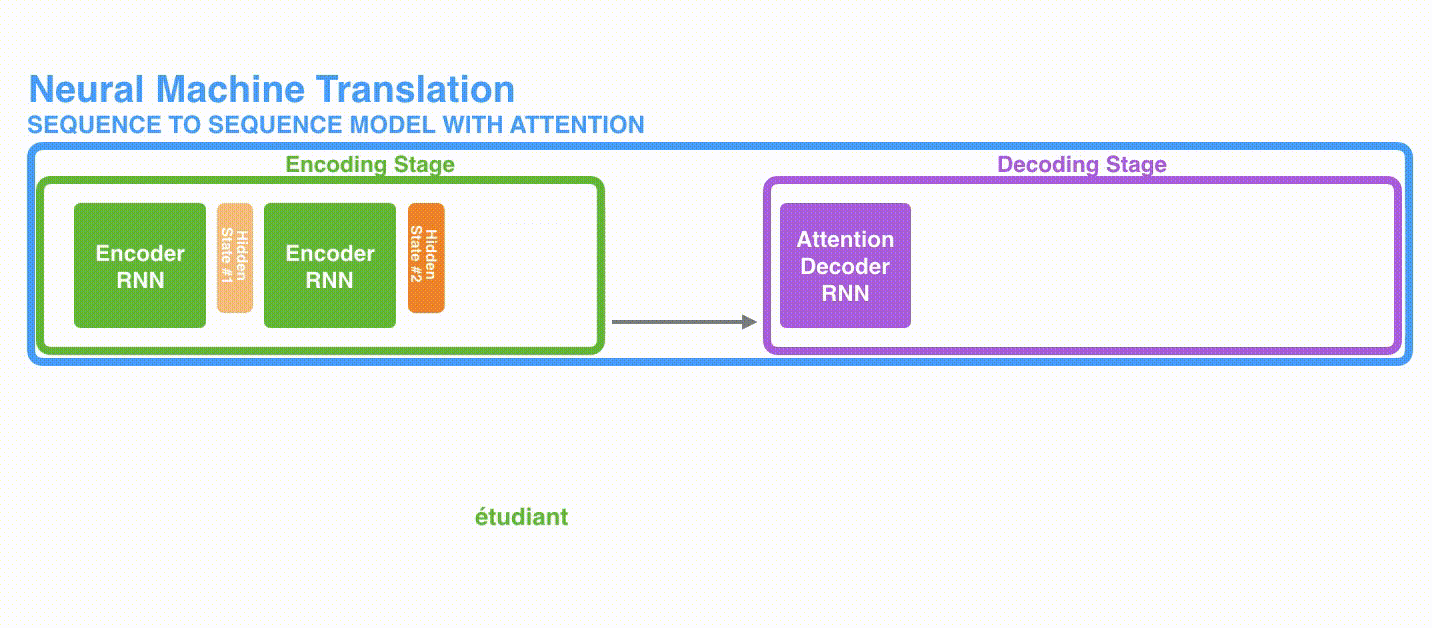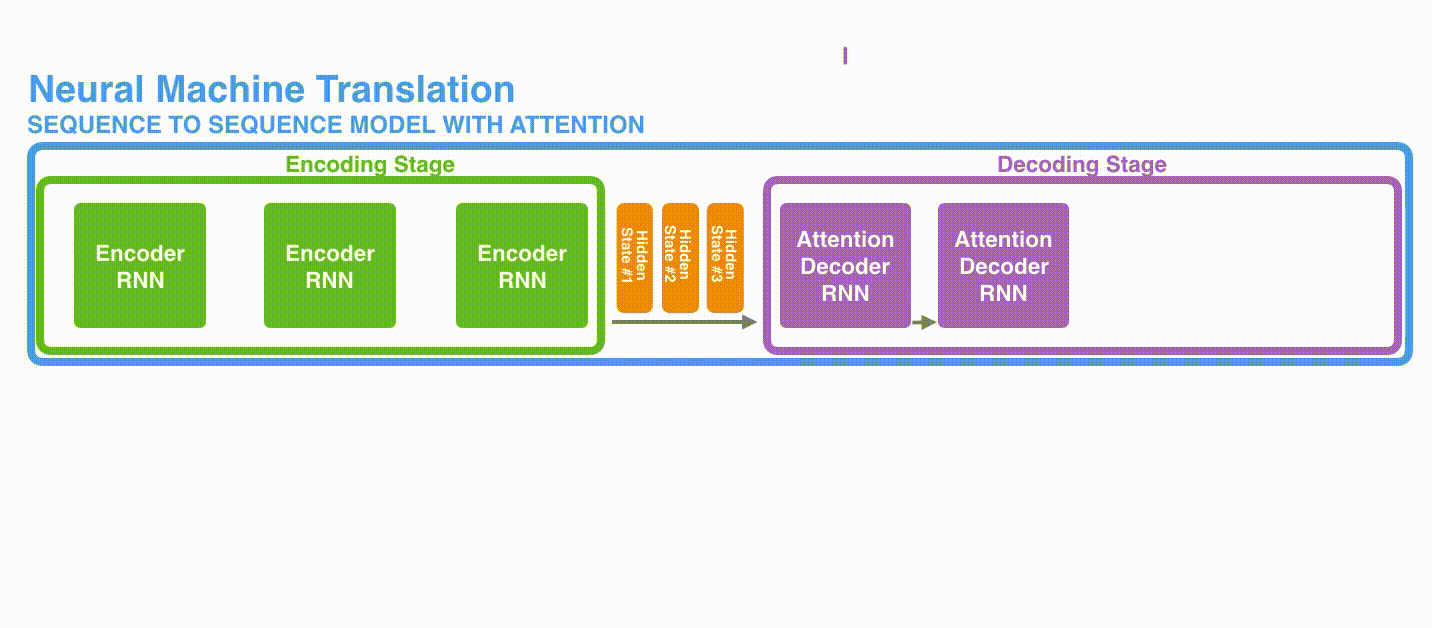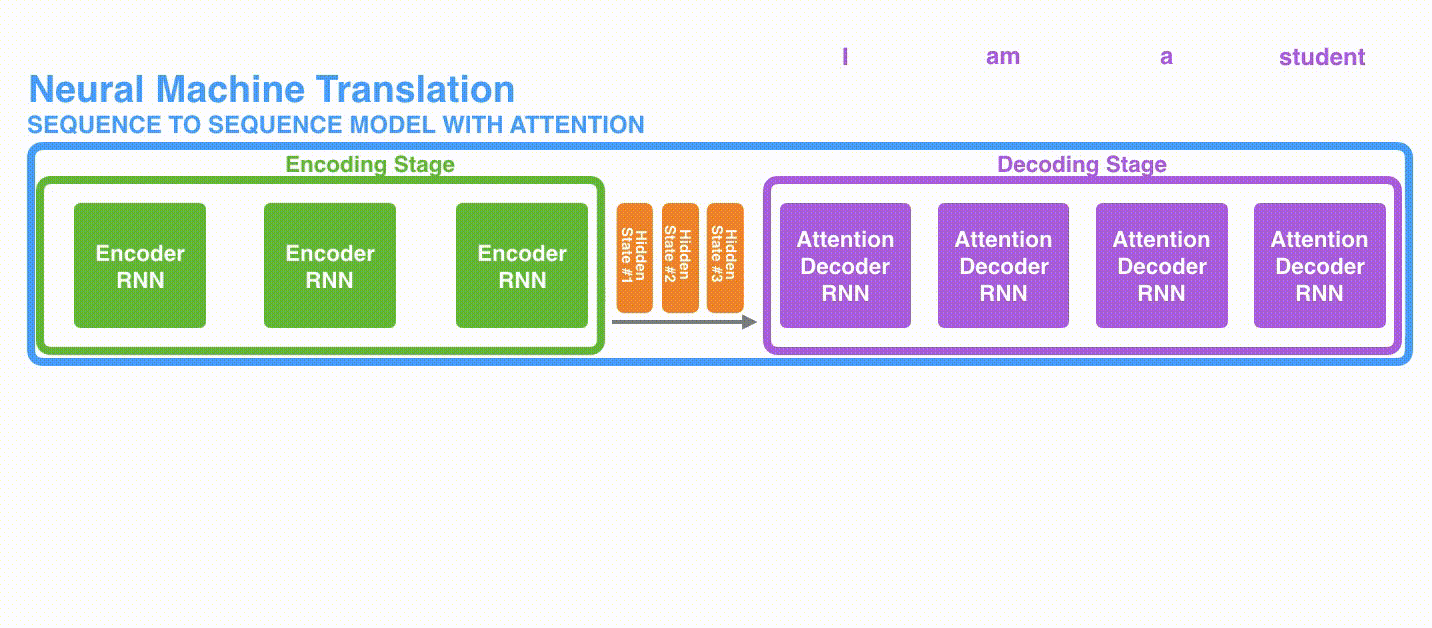
この記事では、ニューラル機械翻訳(NMT)を実例として紹介します。NMTは、1つの大規模なニューラルネットワークを構築してトレーニングし、文を読み込んで正しい翻訳を出力することを目指します。これは、シーケンス・トゥ・シーケンスモデル(再帰ニューラルネットワークなど)を使用して達成されます。モデルには、入力としてシーケンスが与えられ、出力として別のシーケンスが生成されます。
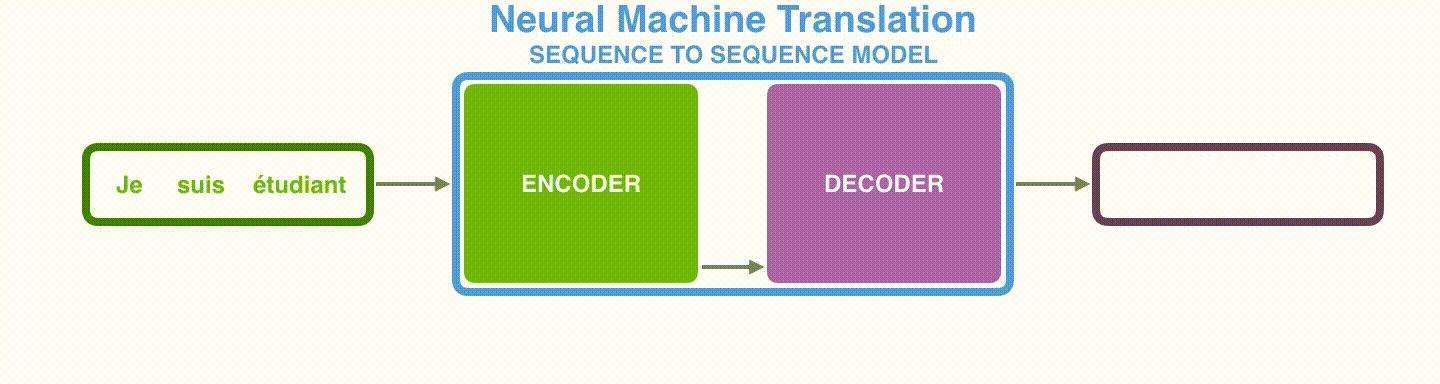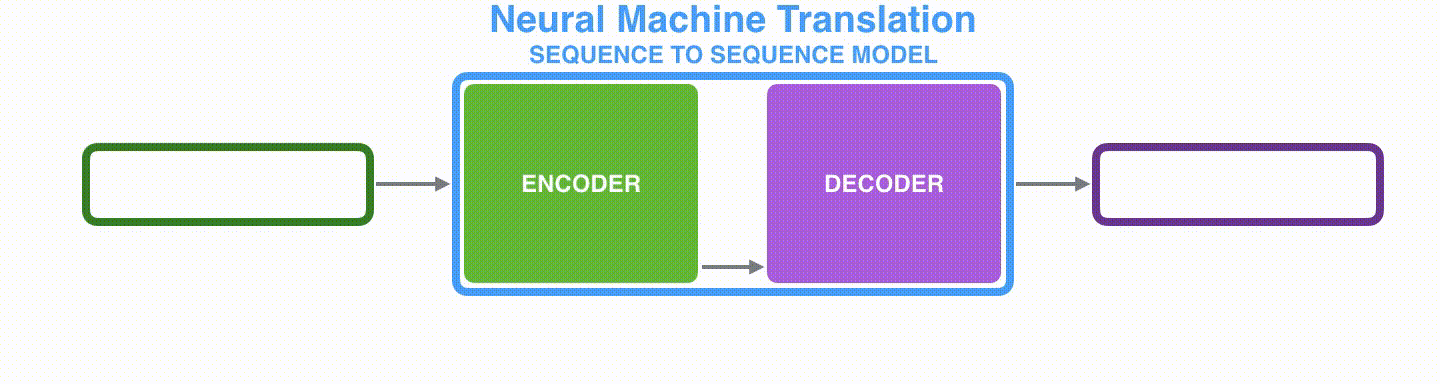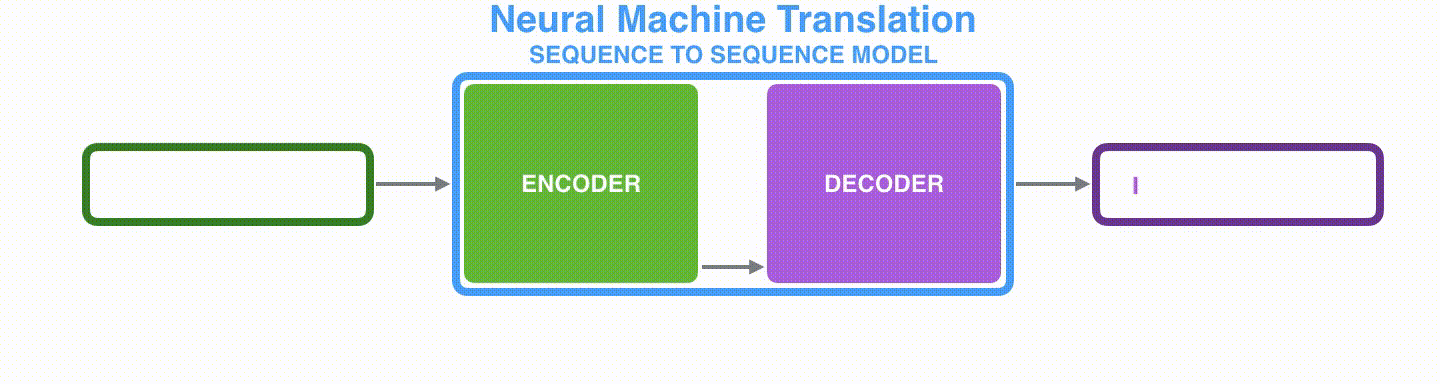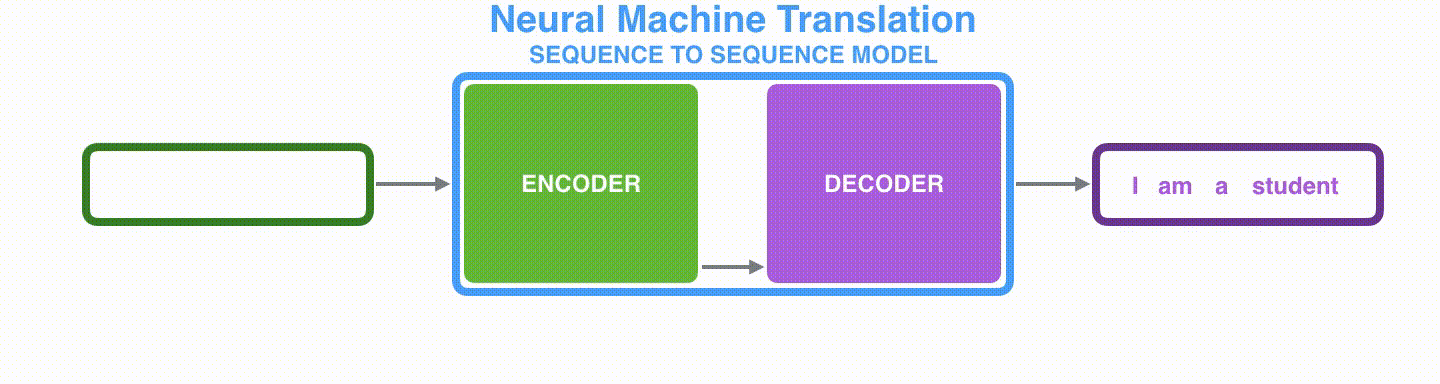
図1は、フランス語から英語への翻訳の例を示しています。モデルにはエンコーダーとデコーダーの2つの部分があります。エンコーダーは文を単語ごとに処理します(自然言語処理(NLP)の用語ではトークンごとに処理されます)。エンコーダーはコンテキストを生成し、それをデコーダーに与えます。デコーダーは単語ごとに出力を生成します。
図2では、エンコーダーは各時刻で隠れ状態を生成し、最後の隠れ状態(隠れ状態#3)がデコーダーの入力として与えられます。
文を単語ごとに処理すると、特に文が長くなると悪影響が出る場合があります。文の最後の隠れ状態だけでは必要な情報をエンコードできず、文の先頭部分を忘れる可能性があります。これはRNNが直面するよく知られた問題です。この問題を解決するために、さまざまな方法が提案されてきましたが、そのそれぞれには利点と欠点があります。アテンションはこの問題に対処するための手法として提案されました(Bahdanau et al)。
アテンションとは何ですか?
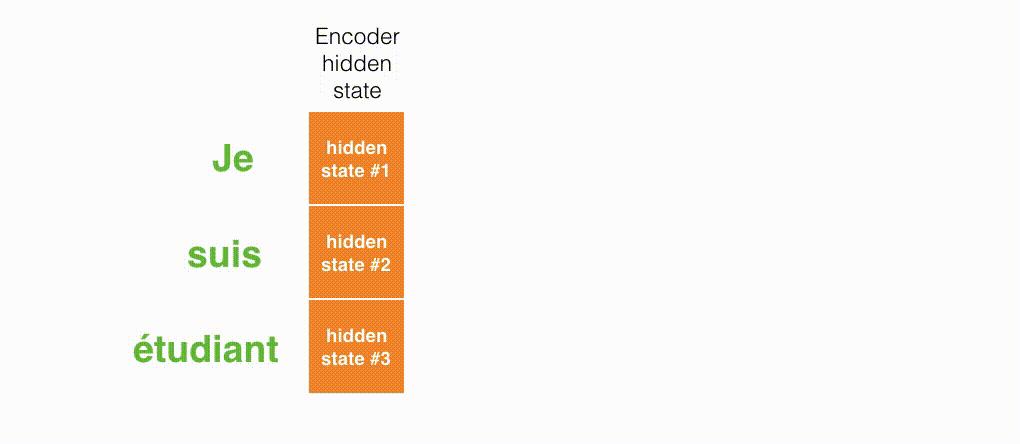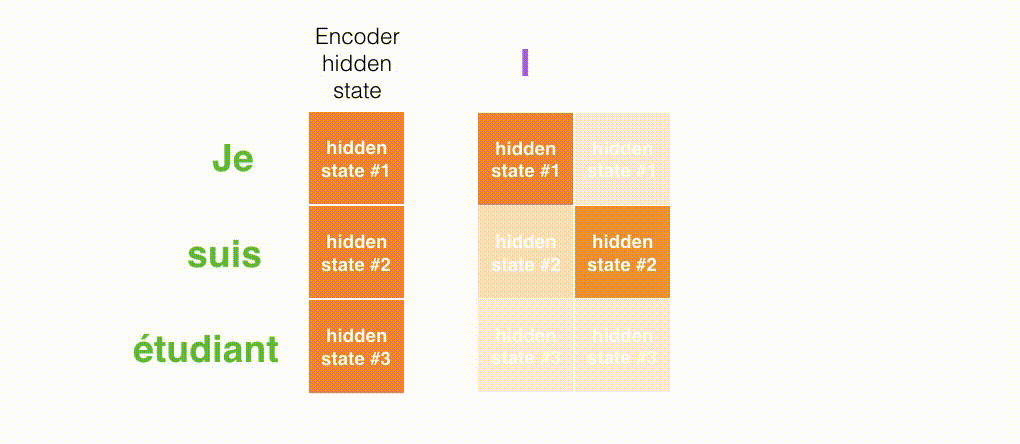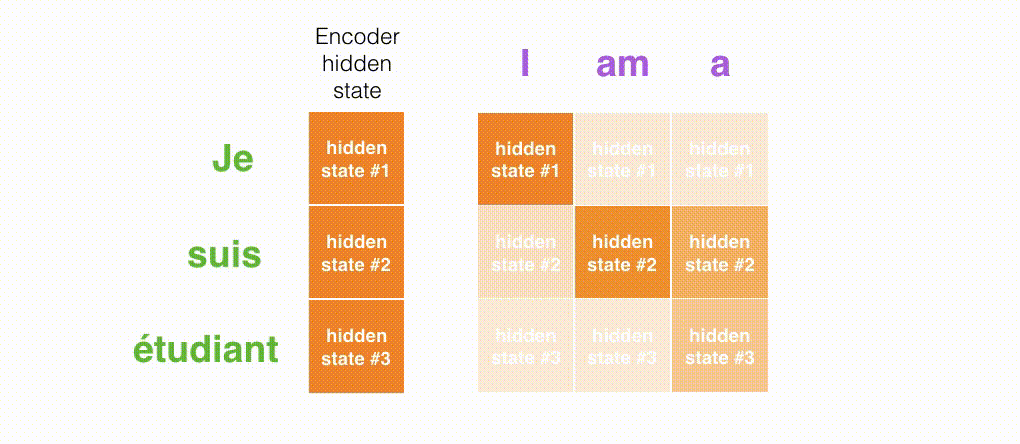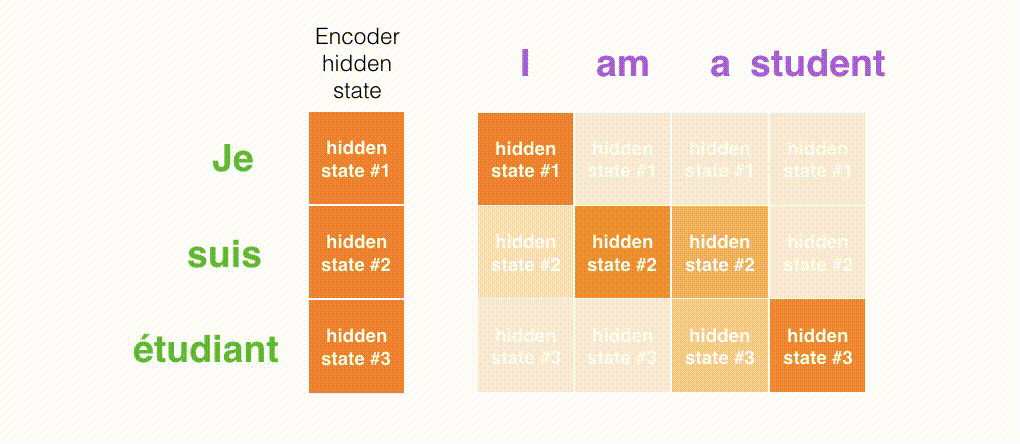
図3では、エンコーダーによって生成されるすべての隠れ状態を考慮しましょう。デコーダーは最後の隠れ状態だけに頼るのではなく、エンコーダーが生成するすべての隠れ状態にアクセスする必要があります。デコーダーは単語ごとに出力を生成するため、各時間ステップでどの隠れ状態を優先するかをデコーダーに伝える仕組みが必要です。たとえば、最初の単語「Je」を生成するためには、隠れ状態#1が最も重要です。2番目の単語「suis」を生成するためには、隠れ状態#2がより重要です。以降同様です。
基本的に、各時間ステップで、隠れ状態に異なる重み付けが必要です。これにより、デコーダーに入力文のどの部分に焦点を当てて出力を生成するかを伝えます。要するに、アテンションは隠れ状態の重み付き和として定式化できます。
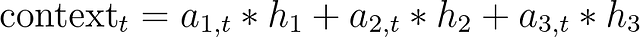
上記の文「Je suis etudiant」は、入力文と出力文の単語間で一対一の対応が比較的簡単です。以下の文(図4)では、「European Economic Area」という単語について、フランス語から英語への単語の対応が逆転しています。このような場合、アテンションは言語間の単語の正しい対応関係を学ぶ上で重要です。

要約すると、エンコーダーは単語ごとに文を処理し、対応する隠れ状態を保存します。これらの隠れ状態は、デコーダーに供給され、アテンションメカニズムが適用されます。
注:アテンションの重みは時間ステップごとに変更されます。
セルフアテンション
アテンションは、入力と出力のシーケンス間のマッピングを学習するための重み付けスキームです。つまり、現在の時間ステップで出力を生成するために重要な入力のどの部分が重要かを学習します。では、以下の文を見てみましょう。

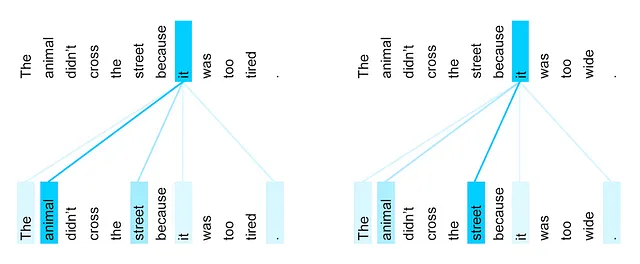
「it」が何を指しているのかを知る必要があります。それは通りなのか動物なのか?これは重要です、特に英語をジェンダーに基づいた言語(フランス語など)に翻訳する場合には。
セルフアテンションは、入力文の単語間の関係をエンコードする手段です。上記の例の最初の文では、文のすべての単語を見て、「it」をエンコードし、動物または通りより他の単語に対して重みを大きくするようにエンコードします。
さて、セルフアテンションがどのように実装されるかを理解するために、トランスフォーマーアーキテクチャを見てみましょう。
トランスフォーマーアーキテクチャ
最初のトランスフォーマーは、2017年の論文で紹介されました。
機械翻訳のために開発されたもので、エンコーダーとデコーダーのアーキテクチャを持っています。エンコーダーとデコーダーは、それぞれエンコーダーとデコーダーのスタックで構成されています。
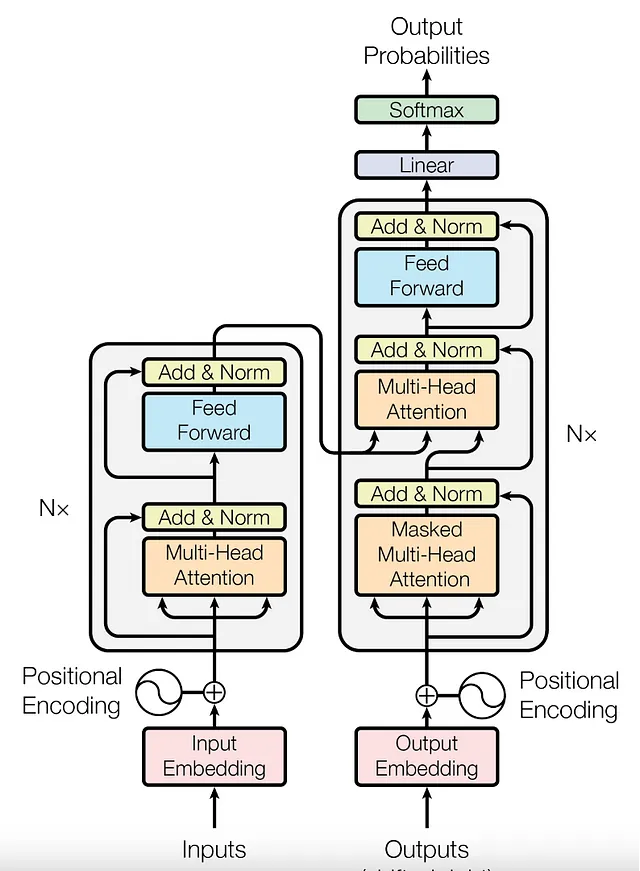
私たちは、エンコーダのMulti-Head Attentionブロックに焦点を当てる予定です。
まず、word2vecモデルを使用して、文の各単語(トークン)のベクトルを生成します。このモデルは、単語を入力として受け取り、その単語の意味を表すベクトルを生成します。word2vecモデルによって生成されるベクトルは、意味が類似している単語がベクトル空間上で近くに配置される傾向があります。つまり、「chair」と「table」の方が、「chair」と「tiger」よりも近くなります。これらのベクトルは、アテンションモジュールに入力されます。
セルフアテンションはどのように計算されますか?(クエリ、キー、値)
以前は、RNNの隠れ状態を単純な加重合計としてアテンションを計算していましたが、ここでは、クエリ、キー、値を使用して異なる方法でセルフアテンションを計算します。
これは、データベースのコンセプトに基づいており、キーとそれに対応する値からなるルックアップテーブルを持っています。誰かがデータベースにクエリを行うと、クエリをキーに一致させ、一致に基づいていくつかの値を取得します。以下の表1に示すような小さなデータベースを考えてみましょう。キーはApple、banana、chairであり、それぞれのキーに対応する値は10、5、2です。
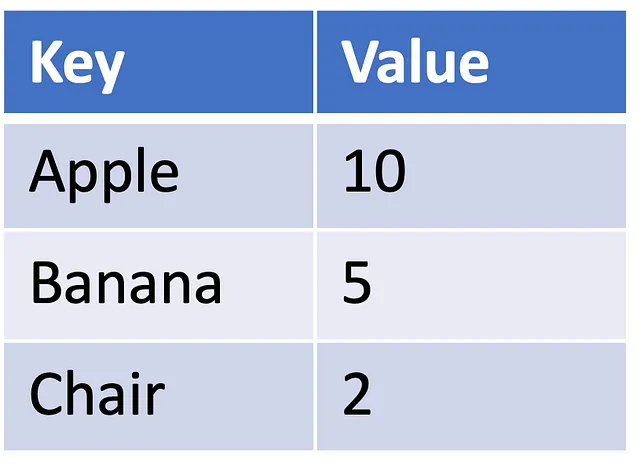
もしクエリがappleだった場合、出力は10になります。しかし、fruitというクエリがあった場合、どうするべきでしょうか?表を見ると、キー”fruit”は存在しません。エラーをスローするか、何か賢いことをするかです。果物をデータセットの他のキーに関連付けることはできますか?果物はappleとbananaに何らかの関連があり、chairとは関連がありません。したがって、fruitはappleに対して0.6倍、bananaに対して0.4倍、chairに対しては0.0倍の関連があります。これらは基本的にはアテンションの値です。したがって、もし今、クエリがfruitだった場合、出力は0.6 * 10 + 0.4 * 5 + 0.0 * 2 = 8になります。
しかし、アテンションの値はどのように計算されるのでしょうか?まず、クエリを4Dベクトルで表現します。

同様に、キー(apple、banana、chair)も対応するベクトル値を使用して行列で表現します。
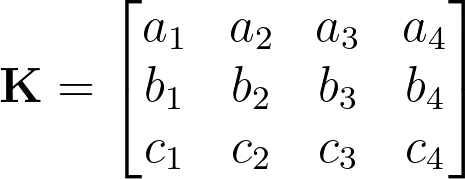
アテンションのスコアは、以下のように計算されます。
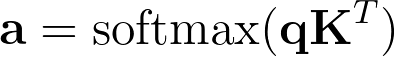
次に、エンコーダでこれがどのように実装されているかについて少し詳しく見てみましょう。
まず、単純な文「Thinking machines」から始めましょう。まず、これらの単語の固定長の埋め込みを生成します。
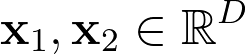
各単語について、以下の式を使用してクエリ、キー、値のベクトルを計算する必要があります。
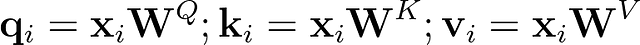
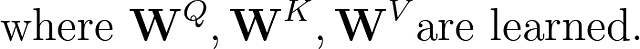
入力を行列として表すこともできます。この場合、

対応するクエリ、キー、値の行列は次のようになります。
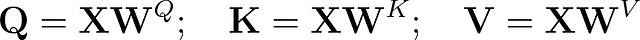

これで、注意値を計算することができます。
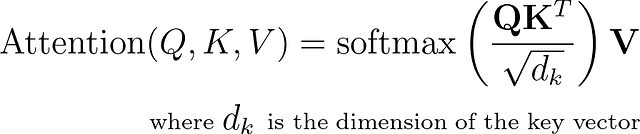
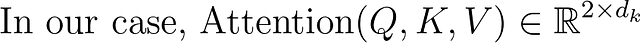
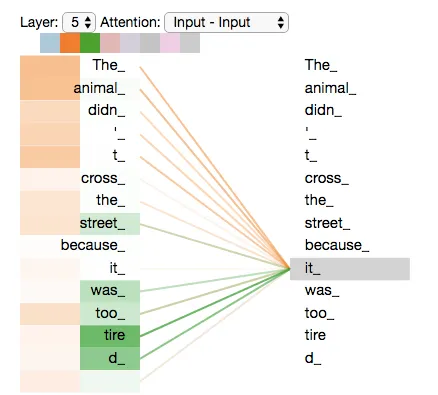
マルチヘッドアテンション
では、文「The animal didn’t cross the street because it was too tired」に戻りましょう。ここで形容詞の「tired」も動物に関連しています。以下の図では、2つのアテンションヘッドが表示されます。最初のオレンジのヘッドは「it」を「animal」と関連付け、2番目の緑のヘッドは「it」を「tired」と関連付けています。したがって、これらのヘッドは、単語「it」、「animal」、および「tired」をリンクするより良い表現を形成します。
したがって、2つのアテンションヘッドを使用すると、
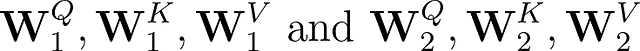
これにより、2つの異なるスコアが生成されます。
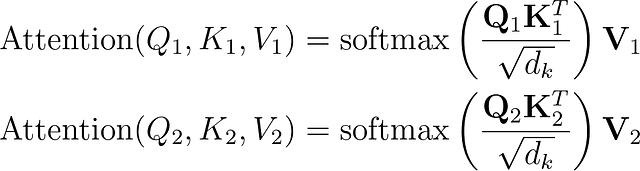
最終的なスコアは、両方のアテンションヘッドからのスコアを連結し、元の入力のD次元に再投影することで計算されます。
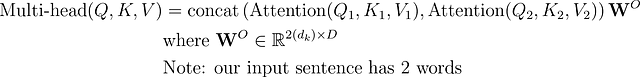
デフォルトでは、トランスフォーマーモデルでは8つのアテンションヘッドが使用されます。
これにより、トランスフォーマーのエンコーダの視点からのアテンションの理解が完了しました。デコーダは、マスキングを使用したやや異なるマルチヘッドアテンションを使用します。これについては、後続の投稿で説明します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「ODSC West 2023 予備スケジュールを発表します」
- テーラーは、ERPオペレーションに対する会話型インターフェースを可能にするChatGPTプラグインを紹介します
- AIはただの悪い学生です
- ラマとChatGPTを使用してマルチチャットバックエンドのマイクロサービスを構築する
- 「Anthropicは、AIチャットボットプラットフォームのClaudeの有料サブスクリプションを導入します」
- 「ジェネレーティブAIをマスターしたいなら、すべてを無視して(ただ2つだけを除いて)ツールに集中せよ」という文です
- 「お知らせ:フォーカスエンターテイメントがゲームパスのタイトルをGeForce NOWに提供します」





