「トランスフォーマーとサポートベクターマシンの関係は何ですか? トランスフォーマーアーキテクチャにおける暗黙のバイアスと最適化ジオメトリを明らかにする」
トランスフォーマーとサポートベクターマシンの関係とトランスフォーマーアーキテクチャにおける暗黙のバイアスと最適化ジオメトリを明らかにする


自己注意機構により、自然言語処理(NLP)は革新を遂げました。自己注意機構は、入力シーケンス内の複雑な関連を認識するためのトランスフォーマーデザインの主要な要素であり、関連トークンの関連性を評価することで、入力シーケンスのさまざまな側面に優先度を与えます。この他の技術は、強化学習、コンピュータビジョン、およびNLPアプリケーションにとって重要な長距離の関係を捉えるのに非常に優れていることが示されています。自己注意機構とトランスフォーマーは、GPT4、Bard、LLaMA、ChatGPTなどの複雑な言語モデルの作成を可能にし、驚異的な成功を収めています。
トランスフォーマーと最適化の風景におけるトランスフォーマーの暗黙のバイアスを説明できますか?勾配降下法で訓練された場合、注意層はどのトークンを選択し、組み合わせますか?ペンシルベニア大学、カリフォルニア大学、ブリティッシュコロンビア大学、ミシガン大学の研究者たちは、注意層の最適化ジオメトリを(Att-SVM)ハードマックスマージンSVM問題と結びつけることで、これらの問題に答えています。この問題では、各入力シーケンスから最良のトークンを分離して選択します。実験結果は、この形式が以前の研究に基づいて構築され、実際的に重要であり、自己注意のニュアンスを明らかにすることを示しています。
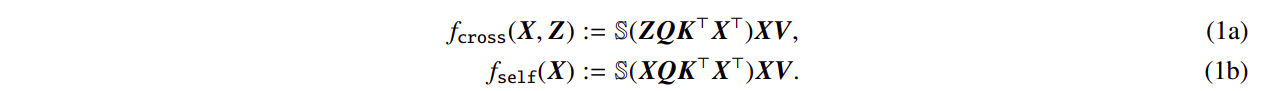
以下では、入力シーケンスX、Z ∈ RT×d(長さT、埋め込み次元d)を使用して、基本的なクロスアテンションと自己注意モデルを調査しています。ここで、訓練可能なキー、クエリ、バリューマトリックスは、K、Q ∈ Rd×m、およびV ∈ Rd×vです。S( . )は、行ごとに適用されるソフトマックス非線形性を示しています。XQK⊤X⊤に対して適用されます。Z ← Xと設定することで、自己注意(1b)はクロスアテンション(1a)の特別なケースであることがわかります。メジャーな発見を明らかにするために、予測のためにZの初期トークンを使用することを検討します。ここで、zで表されます。
- 富士通とLinux Foundationは、富士通の自動機械学習とAIの公平性技術を発表:透明性、倫理、アクセシビリティの先駆者
- 「言語モデルは放射線科を革新することができるのか?Radiology-Llama2に会ってみてください:指示調整というプロセスを通じて特化した大規模な言語モデル」
- 「InstaFlowをご紹介します:オープンソースのStableDiffusion(SD)から派生した革新的なワンステップ生成型AIモデル」
具体的には、次のように表される減少する損失関数l(): R Rによる経験的リスク最小化を扱っています。ラベルYi ∈ {−1, 1}および入力Xi ∈ RT×d、zi ∈ Rdを持つトレーニングデータセット(Yi、Xi、zi)ni=1を与えた場合、次の評価を行います。この場合の予測ヘッドは、値の重みVを含み、シンボルh( . )で示されます。この定式化では、モデルf( . )の注意層の後にMLPが続き、1層のトランスフォーマーを正確に描写しています。ソフトマックス演算は非線形性を持つため、(2)を最適化する際にはかなりの障害があります。

予測ヘッドが固定されて線形である場合でも、問題は非凸かつ非線形です。この研究では、これらの困難を克服し、基本的なSVMの同等性を確立するために、注意の重み(K、Q、またはW)を最適化します。
以下は、論文の主な貢献です:
• 注意層の暗黙のバイアス。組み合わせパラメータW:= KQの核ノルム目標(Thm 2)により、注意パラメータ(K、Q)の最適化は、減少する正則化に収束し、(Att-SVM)の最大マージン解に向かって収束します。交差注意が組み合わせパラメータWによって明示的にパラメータ化される場合、正則化パス(RP)はフロベニウスノルム目標に収束し、(Att-SVM)ソリューションに方向性を持ちます。彼らの知識によれば、これは(K、Q)パラメータ化の最適化ダイナミクスと(W)パラメータ化の最適化ダイナミクスを形式的に比較し、後者の低ランクバイアスを強調する最初の研究です。定理11と付録のSAtt-SVMは、シーケンス対シーケンスまたは因果関係のあるカテゴリ化コンテキストに簡単に拡張でき、選択されたトークンの最適性を明確に定義します。
• 勾配降下法の収束。適切な初期化と線形ヘッドh()を持つ場合、結合されたキー-クエリ変数Wの勾配降下法の反復は、局所的に最適なAtt-SVM解の方向に収束します。選択されたトークンは、局所的最適性のために周囲のトークンよりも優れたパフォーマンスを発揮する必要があります。局所的最適なルールは次の問題の幾何学で定義されますが、常にユニークではありません。これらは、グローバルに最適な方向に収束するための幾何学的パラメータを特定することによって、重要な貢献をします。これには、(i) スコアに基づいて理想的なトークンを区別する能力、または (ii) 初期勾配方向と最適なトークンの整列が含まれます。これらの他にも、過パラメータ化(たとえば、次元dが大きく、同等の条件)は、(Att-SVM)の実行可能性と(良性の)最適化のランドスケープを保証することによって、グローバル収束を促進する方法を示します。これは、定常点や架空の局所的最適方向が存在しないことを意味します。
• SVMの等価性の汎用性。アテンション層は、線形h()で最適化する場合には、ハードアテンションとしてよく知られており、各シーケンスから1つのトークンを選択する傾向があります。出力トークンが入力トークンの凸結合であるため、これは(Att-SVM)に反映されています。
しかし、非線形ヘッドの場合は複数のトークンの作成が必要となり、これらのコンポーネントがトランスフォーマーのダイナミクスにおいていかに重要かを強調しています。彼らは、その理論を結論づけることで、より広範なSVMの等価性を示唆しています。驚くべきことに、彼らはアプローチで取り扱われていない広範な条件(例えば、h()がMLPである場合)において、勾配降下法によって訓練されたアテンションの暗黙のバイアスを正しく予測するということを示しています。彼らの一般的な方程式は、アテンションの重みを2つの要素に分解しています。1つは、ソフトマックス確率を変更して選択された単語の正確な構成を決定する有限成分であり、もう1つは、0-1マスクを適用してトークンを選択するSVMによって制御される方向成分です。
これらの結果が数学的に検証可能であり、(SVMが実用的な場合)どのデータセットにも適用可能であるという事実は、それらの重要な側面です。洞察に富んだ実験を通じて、彼らはトランスフォーマーの最大マージンの等価性と暗黙のバイアスを包括的に確認しています。彼らは、これらの結果が階層的な最大マージントークン選択プロセスとしてのトランスフォーマーに関する私たちの知識に貢献し、その研究の最適化と一般化のダイナミクスに堅固な基盤を提供すると期待しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





