「データ資産のポートフォリオを構築および管理する方法」
データ資産のポートフォリオの構築と管理方法
ステップバイステップのアプローチ
データアセット(または製品)は、特定のユースケースのために容易に消費できる準備されたデータや情報のセットで、データ管理の世界で話題です。個々のデータ製品を特定し、構築し、管理することができることは一つのことですが、企業レベルでどのように進めれば良いのでしょうか?どこから始めれば良いのでしょうか?
データの活用リーダーや特にチーフデータオフィサーは、この移動の課題に取り組んでいます。この視点では、データアセットに対してポートフォリオのアプローチを取る方法について説明します。以下の図1は、ステップバイステップのアプローチを示しており、この記事の残りでは7つのステップについて詳しく説明します。途中で、アプローチと方法論を説明し、進むにつれて例を交えて説明します。
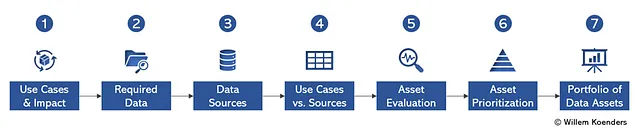
私は実際の例にこのアプローチを使用してきましたが、特定のクライアントのデータが提供されているという疑いを避けるために、適切なプロンプトが与えられた場合にジェネレーティブAIが具体的に使用される方法を示すために、ChatGPT 4.0を使用しました。完全なチャットはこちらでご覧いただけます。
ステップ1:ユースケースと影響
最初のステップは、組織にとって重要なデータ駆動型のユースケースを特定することです。すべての企業全体について同時に行う必要はありません。ドメインまたはビジネスラインの一部から始めることもおすすめです。
- 「Reactを使用して、エキサイティングなデータセットに対してインタラクティブなインターフェースを構築する」
- AccelDataがBewgleを買収:AIデータパイプラインの可視化における重要な動き
- 「データ注釈は機械学習の成功において不可欠な役割を果たす」
ユースケースは、全体的な組織戦略を実施するための具体的なメカニズムです。データ戦略とデータガバナンスは、それ自体では価値を生み出しません。より広範な戦略的目標が達成される範囲でのみ、価値を生み出します。したがって、ユースケースは最初のステップである必要があります。
これにはさまざまな方法があります。ビジネスと分析のリーダーへのインタビューによってユースケースの一覧を内部で作成することができます。自分のセクターについては、外部情報源からユースケースの概要をまとめることができます。最も成功する方法は、ハイブリッドアプローチを取ることです。外部のユースケースのリストを取り入れ、それを内部のリーダーとともに洗練させます。
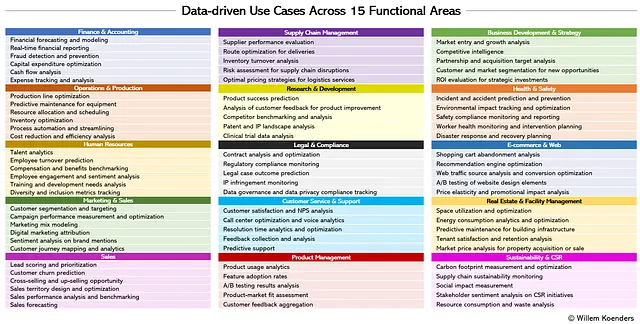
上記の説明のように、この記事の目的のために、ChatGPT 4.0を使用してユースケースの一覧を作成しました。以下の図2に示されています。たとえば、金融・会計のユースケースでは、不正検出と予防のために、リアルタイムの分析と機械学習モデルを顧客とトランザクションのデータの組み合わせに使用してパターンを認識し、不審なイベントを特定します。また、マーケティングと販売では、マーケティングミックスモデリングの一環として、マーケティングの取り組みと売上パフォーマンスの間の歴史的な関係を調査し、マーケティング予算の割り当てとチャネル・戦略の使用を最適化します。
ユースケースを持っているだけでは十分ではありません — それらがどれほど重要であるかを把握する必要があります。ユースケースが価値を生み出す4つの重要な方法があります。
- 収益の増加
- コストの削減
- 顧客体験の向上
- リスクの軽減
一部のリストは「イノベーションの推進」として第5の価値ドライバーを挙げていますが、私の見解では、それは時間軸の問題です。なぜなら、どんなイノベーション自体も最終的には上記の4つのメカニズムを通じて価値を生み出すためです。
さて、図3では、マーケティング関連のユースケースとそれらに関連付けられている典型的な「トップラインへの影響」の概要を示しています。実際に、さきほど紹介したマーケティングミックスモデリング(MMM)のユースケースでは、「トップラインへの影響は1〜2%」と表示されます。企業の年間売上が10億ドルであれば、これらの推定によれば、マーケティングミックスモデリングによってそれに追加して1,000万〜2,000万ドルが生み出される可能性があります。

ステップ1の終わりには、組織への影響が推定されたユースケースのセットがあります。
ステップ2:必要なデータ
このステップでは、特定されたユースケースを実現するために必要なデータを調査します。まず、ユースケースに必要な重要なデータ入力を定義することから始めます。たとえば、オペレーションの下の製品ライン最適化の場合、必要なデータには生産量データ、機械のパフォーマンスログ、原料の入手可能性が含まれます。また、人事の下の離職予測の場合、従業員の満足度調査、退職面接のフィードバック、業界の離職率からデータが必要です。
ユースケースの一部または完全なリストがあると、関連するSME(Subject Matter Expert)またはプロセス所有者が必要なデータを明確にするのに役立ちます。重要なデータ入力のリストが増えるにつれて、データをデータタイプまたはドメインにグループ化することができるようになります。セクター内、およびある程度セクター間でも、これらのデータタイプとドメインは実際にはかなり安定しています。ほとんどの組織が一定の人々のグループにサービスを提供し、そのための従業員を持ち、予算を管理する必要があるため、顧客(または顧客と同等の存在、例えば学生、患者、またはメンバー)や従業員、財務を含む顧客、従業員、財務など、ほとんどの場合適用されるデータドメインがあります。サプライチェーンや研究・安全データなど、その他の一部のドメインはより具体的であり、組織が製品や材料の物理的な供給チェーンを管理している場合にのみ適用される場合があります。
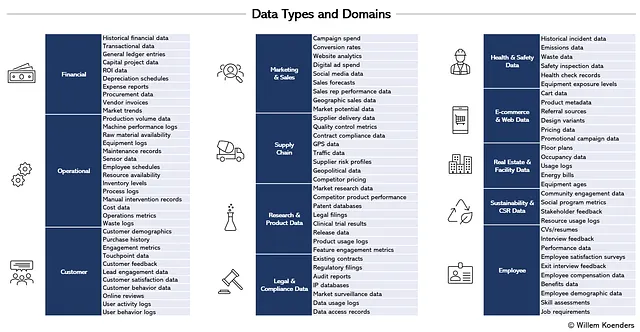
上記の図4では、12のデータドメインと約100のサブドメインが示されています。組織のすべてのデータは、ここにリストされているタイプにマッピングできます。たとえば、マーケティングとセールスの下のキャンペーンの支出データには、デジタル広告、伝統的なメディアキャンペーン、スポンサーシップのイニシアチブとコストに関するデータが含まれる場合があります。また、オペレーションの下のセンサーデータには、倉庫内に配置された温度センサーや工場で機械の健康状態を監視するための振動センサーからのデータが含まれる場合があります。
ユースケースの重要なデータ入力を特定し、それらの重要なデータ入力をデータタイプまたはドメインにマッピングし始めると、図5のようなマトリックスを作成できます。上記では、製品ライン最適化という例のユースケースがオペレーションのデータドメインにマッピングされています。ここでは、視覚化するためにユースケースがより広範なデータドメインにマッピングされていますが、実際の生活では、ユースケースを基礎となるより詳細なサブドメインにマッピングすることができます(すべてのリソースイメージの要求に応じて、完全な解像度のイメージが利用可能です)。
ユースケースが必要とするデータタイプに対してキーのユースケースがマッピングされた、このような全体像は、データ戦略の開発や特定のデータドメインの優先順位付けにおいて、既に非常に有益ですが、私たちはさらに進めて、もっと具体的な対策を講じます。
ステップ3:データソース
ステップ2の(論理的な)データ要件に基づいてソースシステムを識別する前に、一つのユースケースグループを取り上げ、必要なデータを評価しましょう。以下の図6は、マーケティングとセールスのユースケースの概要と、それらが依存する重要なデータを示しています。これは、図5に示されている内容と一致しており、より詳細なレベルで示されています。
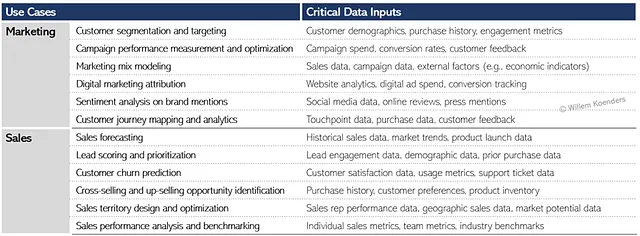
たとえば、顧客セグメンテーションとターゲティングの最初のユースケースでは、顧客デモグラフィックスのデータが必要です。対象の企業では、そのデータはグローバルCRMと呼ばれる物理的なシステムに保存されています。同じユースケースが必要とする購入履歴データは、Eコマースのトランザクション履歴と小売りのPOSシステムの2つのシステムに保存されています。
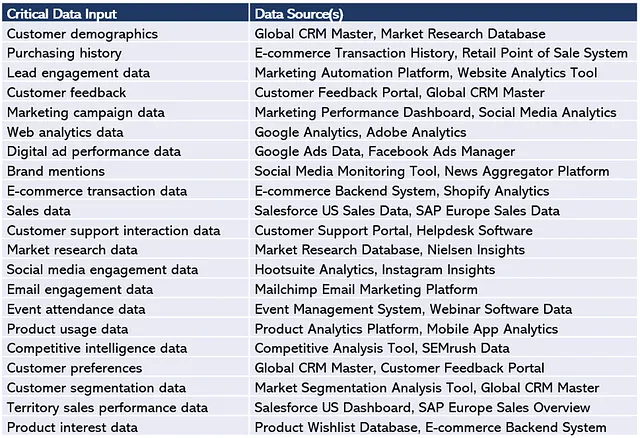
などなど。図6の上記の重要なデータ入力をすべて取り上げ、ソースシステムを特定すると、図7の表が得られます。ご覧の通り、一部のデータソースには複数の種類の重要なデータが含まれています。たとえば、グローバルCRMマスターには顧客デモグラフィックスだけでなく、顧客の好み、顧客のフィードバック、および顧客セグメンテーションデータも含まれています。
ステップ4:ユースケース対ソース
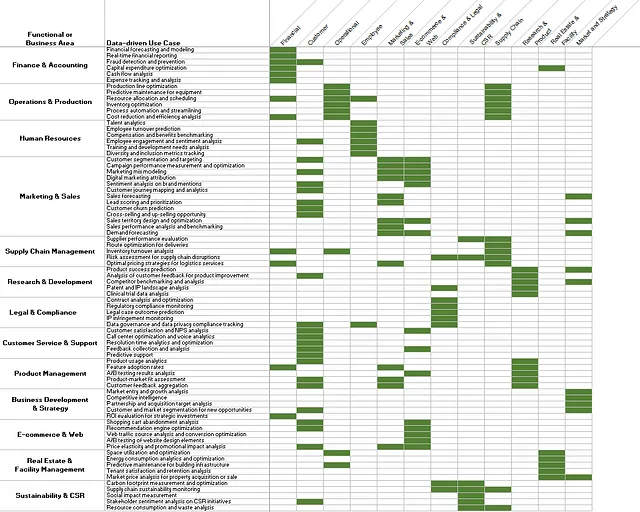
ユースケースの必要なデータを特定し(ステップ2)、それをソースシステムにマッピングしました(ステップ3)。次に作成できるビューは、マーケティングと販売のためのユースケースとソースシステムのマッピングであり、その例を以下の図8に示します。
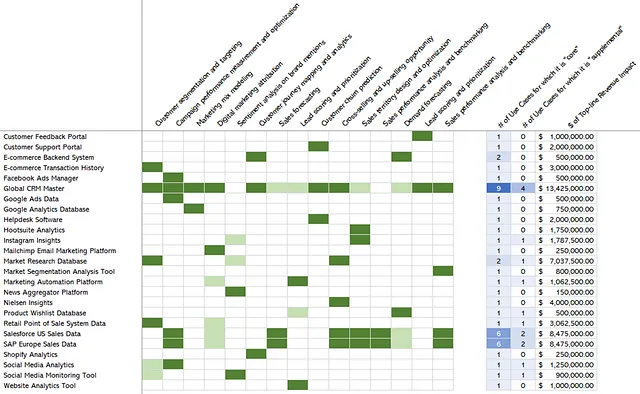
ここでは、濃い緑はデータがユースケースにとって重要であることを示し、薄い緑は「あってもいい」またはサポートしていることを意味します。たとえば、顧客セグメンテーションとターゲティングの場合、グローバルCRMマスターからのデータは重要ですが、ソーシャルメディアの分析からのデータは「あってもいい」です。
しかし、私たちはすでにユースケースについて多くのことを知っています。実際、ステップ1で最初に行ったことは、ユースケースとそれらのユースケースがもたらす増収を特定することでした。これにより、特定のデータソースに依存する価値創造について言及できるようになります。なぜなら、特定のデータセットが3つのユースケースにとって重要であり、それぞれが推定で2、3、5百万ドルの増収を生み出すとわかっている場合、このデータセットには1000万ドルの売上が依存していると述べることができます。
この演習は単独では完了できません — それには対応するユースケースとビジネスプロセスの専門家および所有者の協力が必要です。これらの人々を特定するのには時間がかかるかもしれませんが、一度見つけると、ユースケースの成功を確保するために関与しているため、協力的であることが通常です。したがって、どのデータが重要であり、それがもたらす影響を明確にするために、協力する必要があります。
進行するにつれて、図8の右側に示されているように、マーケティングと販売のユースケースにとって重要なすべてのデータソースに対するトップラインの収益インパクトを推定できるようになります。ただし、重複計算に注意し、数値を適切に説明して修正する必要があります。たとえば、特定のユースケースの価値創造ポテンシャルが100万ドルであり、2つのデータソースに依存している場合、2つのデータソースが合わせて200万ドルを生み出すとは言えません。
ステップ5:アセット評価
前のステップでは、ユースケースとそれらが駆動する価値をデータソースのセットに対してマッピングしました。これにより、これらのデータソースが価値を生み出す可能性があることがわかり、それは会社にとって固有の価値を持つということを意味します。したがって、これらはデータアセットと見なすことができます。
図8は非常に洞察に富んでいますが、特定のデータアセット(およびそれに対する投資)を他のデータアセットより優先することはまだできません。特定のデータアセットが多くの価値を生み出す可能性があるが、既に使用可能で「目的に適っている」という場合、さらなる行動は必要ありません。
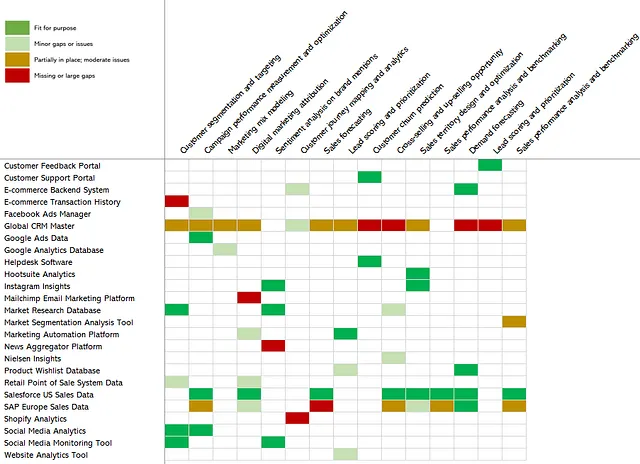
図9は、データアセットの評価状態を「目的に適っている」から「不足または大きなギャップがある」までの4つの状態に分け、データアセットの一貫した評価を可能にします。ここで、目的に適っているとは、広く解釈する必要があります。スペクトラムのポジティブな端では、適切なデータが適切な粒度とタイムリネスで利用可能であり、品質が高く信頼性があり、ソースシステムが常に稼働していることを意味します。他方では、データアセットがまったく存在しないか、存在する場合でもデータが非常に不十分で信頼性がなく、または不完全であることを意味します。

これで、私たちは「ホットエリア」(つまり、赤色または黄色の部分)を示すヒートマップを作成するために必要なツールを持っています。これは、ユースケースが必要とするデータに依存できない場所で、価値創出の機会を示しています。以下の図10をご覧ください。
ステップ6:アセットの優先順位付け
次のステップは、私たちがこれまでにデータアセットについて知っているすべてに基づいて、データアセットの優先順位を付けることです。図11では、図10にあったヒートマップと収益への影響と依存するユースケースの数を追加しました。その後、データアセットを再配置し、生成される総収益への影響に基づいて降順で整理しました。
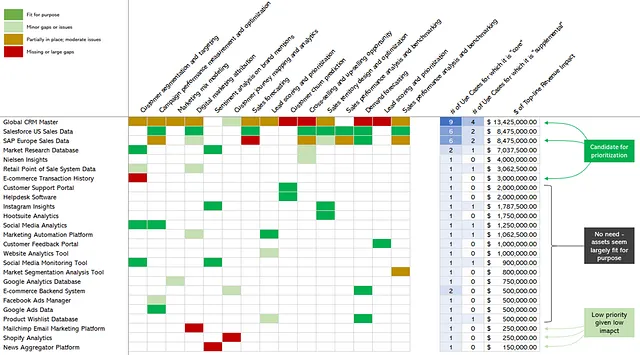
これにより、改善と投資のために優先順位を付けることができるデータアセットがより明確になります。たとえば、グローバルCRMマスターは、9つのユースケースに最適にフィードされていないため、1300万ドル以上の影響があります。Instagram Insights、顧客サポートポータル、Google Adsデータなど、さまざまなデータアセットは目的に適っており、救済措置を必要としないようです。そして、Shopify Analyticsやニュースアグリゲータプラットフォームなど、1つのユースケースのみをサポートするが影響が限定的なものがいくつかあります。
もしもあなたが最高データ責任者であり、このパノラマが与えられたドメインの組織のデータアセットとユースケースを反映している場合、影響を与えるロードマップが自ら開かれます。戦略的に重要なデータのガバナンスを強化するために、1つまたは2つのデータアセットを取り上げ、データの所有権と管理、メタデータの管理、データ品質などのさまざまなデータガバナンスの能力を組み込み、操作化する機会が明確にあります。
ステップ7: データアセットのポートフォリオ
データリーダーである最高データ責任者(CDO)の期待される在職期間は、平均2.5年未満とよく言われています。これは、CDOが短期間で有意義なビジネスの影響を実現するのに苦労していることが大きく原因です。
それがなぜ、この視点で示されたアプローチが非常に強力なのか、その理論に則ってデータ資産を優先順位付けすると、ほとんど確実に影響を生成することができます。そして、ユースケースとその影響から始めることで、ビジネスと機能領域を関与させることができ、したがって「データそのもののためにデータを行う」という罠に陥ることを避けることができます。これは、データガバナンスがビジネスに対して費用や障害となるという認識を避けるためにも重要です。
ここで終わりではありません。特定したデータ資産は、不動産ポートフォリオの所有物に類似しています。これらを積極的に管理し、データ利用者が引き続き満足していること、新しい要件が追加されていること、価値の創出が明示的に追跡されていることを確認する必要があります。
以下の図12は、この視点で分析した組織のデータ資産ポートフォリオダッシュボードを示しています。認定されたデータ資産の数、それにマッピングされたユースケースの数、および増加収益とリスク軽減によって生成された価値が表示されています。
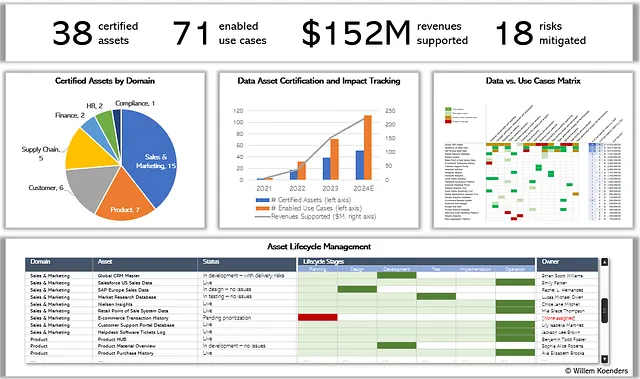
中央には、認定されたデータ資産の数と、さらに重要なこととして、有効なユースケースの数と収益で表される関連する影響を追跡するグラフが表示されています。これは、CDOのキャリアの長期化にとって重要です。対象となるデータの有効化とガバナンス活動によって生成される価値を証明できるようにするためです。
一番下には、データ資産のパイプラインビューが表示されます。それらのいくつかは構造化されたアクティベーションライフサイクルを通じて押し進められている一方、他のものは既に稼働しています。先ほど調査したGlobal CRM Masterは、現在「開発」フェーズにあります。
市場からの逸話
この視点の最初に述べたように、私はヨーロッパと米国の複数の企業で、銀行、保険、小売、テクノロジー、製造業を横断してこのアプローチを使用し、洗練させました。
製造業の一つの例では、ここで概説された7つのステップの若干変更したバージョンを使用しました。複雑なグローバル企業であるため、組織全体でユースケースを特定することはできませんでした。代わりに、主な焦点として1つのビジネスドメイン、つまり商業部門、およびマーケティングとセールスのサブドメインを選びました(ステップ3でのユースケースの範囲と似ています)。
私たちは、他の目的のために既に定義されているほとんどのユースケースのセットを特定しました。必要なデータと対応するソースを特定し、ユースケースをソースにマッピングするため、ステップ2から4までの軽量で加速されたバージョンを実行しました。ステップ5に進み、ユースケースの所有者とSMEに参加し、適切な目的に適したデータにアクセスできるかどうか尋ねました。できない場合、どのデータまたはソースが不足しているのか、問題は何ですか?
かなり速く、データが必要なユースケースに問題がある8つのユースケースのセットに落ち着き、これらのユースケースのうち6つに対して2つの特定のデータソースが問題だとわかりました。さらに深く掘り下げることはありませんでしたが、作業を開始しました。中央のデータチームと商業チームと共に、2つのデータソースの所有者を調整し、一連の正式な認証基準に基づいてそれらを評価し、ギャップを解消するための計画を立てました。
数ヶ月後、最初のデータ資産は強化され、認定され、文書化されたユースケースのニーズを満たすために使用されました。執筆時点では、正確な影響はまだ測定されていませんでした(影響が実現するまでには時間がかかるため)、しかし初期の逸話的な証拠は、マーケティングの効果が大幅に向上した可能性があることを示唆していました。いずれにせよ、問題となるCDOはアプローチを導入し、洗練させ、控えめな成功を収め、さらなるアセット、ユースケース、ドメインの広範なロードマップを開始することができました。
頑張ってください!
データポートフォリオの構築と管理は簡単でも速くでもありませんが、努力は報われるものです。ここで説明された手順が役立つことを願っています。進捗状況をお聞かせいただけると嬉しいです。もしご意見やご自身の体験談がありましたら、ぜひコメント欄にご投稿ください。
データ資産の有効活用の旅、安全な旅をお祈りしています!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
