データ・コモンズは、AIを使用して世界の公共データをよりアクセスしやすく、役に立つものにしています
データ・コモンズは、AIを使用して公共データのアクセスと有用性を向上させています
世界中の政府、組織、その他多くの人々が、気温、貿易、疫病の発生率など、さまざまなトピックに関してデータを生成しています。これらのデータは、気候変動、飢餓、流行病などの重要な社会的課題を理解し、対処するために非常に役立つものです。幸いにも、このデータの多くは公に利用可能であり、さらに利用可能なものもあります。しかし、公に利用可能であることとアクセスしやすく利用しやすいことは同じではありません。これが、GoogleのイニシアチブであるData Commonsが埋めるべきギャップです。
データはしばしば国や州の境界によって分断され、さまざまな機関、研究機関、非政府組織によって収集・公開され、さまざまな形式でさまざまなタイミングで共有されます。これらの公共データセットを有効に連携させることは、政策立案者、研究者、非営利組織、ジャーナリスト、学生、一般の人々が社会問題をより良く理解し、解決策を見つけるためには、困難で時間がかかり、コストがかかる場合があります。Data Commonsの長期的なビジョンは、Google検索がインターネットに対して行っていることや、Googleマップがナビゲーションに対して行っていることと同様に、公に利用可能なデータを整理し、アクセス可能かつ有用にすることです。
 10:25
10:25
私たちの目標は、社会の重要な課題や機会に取り組もうとする人々に、データとその洞察をより利用しやすくすることです。これは、2つのイノベーションによって実現されています。今後もさらに進化していく予定です。
まず、2017年以来、Data Commonsチームは、気候変動の政府間パネルやブラジル地理統計研究所、アメリカ商務省など、信頼性のある公に利用可能なソースから数千のデータセットを標準化・処理することを目指してきました。これには、さまざまな形式、スキーマ、アクセス方法を持つデータを統合し、単一のAPIとスキーマを持つナレッジグラフを作成するためのイノベーションが必要でした。この統合されたビューにより、データの経験豊富なユーザーは通常数週間かかる作業を数時間で達成することができます。データの標準化とアクセス可能性を確保することは大きな進歩でしたが、APIや可視化ツールを介してそれを利用するには、時間のかかる投資やコーディングスキルが必要でした。
次に、この問題に対処し、Data Commonsをさらに使いやすくするために、Data CommonsはAIの力、具体的には大規模言語モデル(LLM)を活用して、自然言語インターフェースを作成しています。ユーザーは、例えば「インドの州で一人当たりの最も高い貧困率を持つ州はどこですか?」や「識字率と貧困率はどう比較されますか?」、「これらの州で乳児死亡率はどれくらい変化しましたか?」などの質問をすることができます。
ビデオ形式はサポートされていません
AIを使用することで、「アフリカのどの国が電力アクセスを最も増加させましたか?」や「所得と糖尿病はどのように相関していますか?」などの質問をすることができます。また、「ヨーロッパの農業における温室効果ガスの排出量とGDPを比較してください」といったプロンプトを使うこともできます。
LLMはクエリを理解し、結果はData Commonsから直接提供され、元のデータソースへのリンクも含まれます。したがって、出力はLLMによって生成されるものではありません。このアプローチにより、Data Commonsは、一部の事例におけるLLMの真実性に関する現在の制約のいくつかを回避することができます。
Data Commonsはデータを収集または所有しておらず、代わりに200以上のソースから公に利用可能なデータを引き出しています。データセットには人口統計、経済、教育、住宅、公衆衛生、気候、持続可能性、生物医学などの情報が含まれています。194カ国のデータがあり、一部の国では州や県レベルまでデータがあります。ただし、これまでにアクセス可能なデータは均等に分布しておらず、完全ではありません。残念ながら、データの利用可能性は他の問題と同様に公平性の課題を反映しており、現時点ではアフリカ、南アメリカ、アジアの一部の国よりも、アメリカ、インド、OECD加盟国のデータの方が多くなっています。追加および最新のデータを利用できるようにするには、さらなる作業と継続的な取り組みが必要です。私たちは、ギャップを埋めるためにさらに多くの公共データが公開されることを願っており、世界をより良く理解し、重要な社会的課題に取り組むためのデータのカテゴリを追加することを目指しています。私たちは、さらなるデータとパートナーを積極的に探しており、これらのギャップを埋めるための助けを求めています。
Data Commonsはオープンソースであり、オープンなプロセスであり、誰にでも利用できます。Data Commonsサイトに加えて、Data Commonsの一部のデータポイントはGoogle検索のクエリの応答に使用されています。Data Commonsを利用して社会の課題に取り組む組織と協力しています。その結果、Resources for the Future、Feeding America、IIT MadrasのRobert Bosch Centre for Data Science and Artificial Intelligence、Stanford Doerr School of Sustainability、Harvard University’s Institute for Quantitative Social Scienceなどのグループが独自のData Commonsのバージョンを持つことができます。これにより、組織はすでにData Commonsを通じてアクセス可能な公共データを含めた自社のデータの統一されたビューを提供することができます。
テックソープのチーフコミュニティインパクトオフィサーであるマーニー・ウェブは、長年のGoogleパートナーとして、データコモンズが彼女の組織が取り組んでいる小規模な非営利団体にも役立つことを共有しました。「データコモンズは、地域のニーズについて質問するためのツールを、地域の組織に提供します。同僚に質問する際に使用する言語で質問することができ、信頼性のある情報を得ることができます。まるでデータサイエンティストやデータエンジニアがスタッフとしているかのようなものです。私たちが言っているのは、より良い意思決定のための情報の民主化であり、組織が自らのコミュニティにより良いサービスを提供するためにスマートなリスクを取ることができるようにすることです。私たちは、データの力を、自分たちのコミュニティをよく知っている人々の手に握らせることを話しています。」
たとえば、Google.orgからの資金援助により、テックソープは非営利団体がデータコモンズの力を利用して社会的な課題を評価し、解決するのを支援しています。たとえば、セメフィはメキシコにおける飢餓とジェンダーの関係を強調し、マカイアはコロンビアの経済と社会的な成長を追跡しています。テックソープは、米国農務省やフィーディングアメリカなどの情報源からデータを結集することで、食料安全保障、農業、気候変動の関係を説明しています。
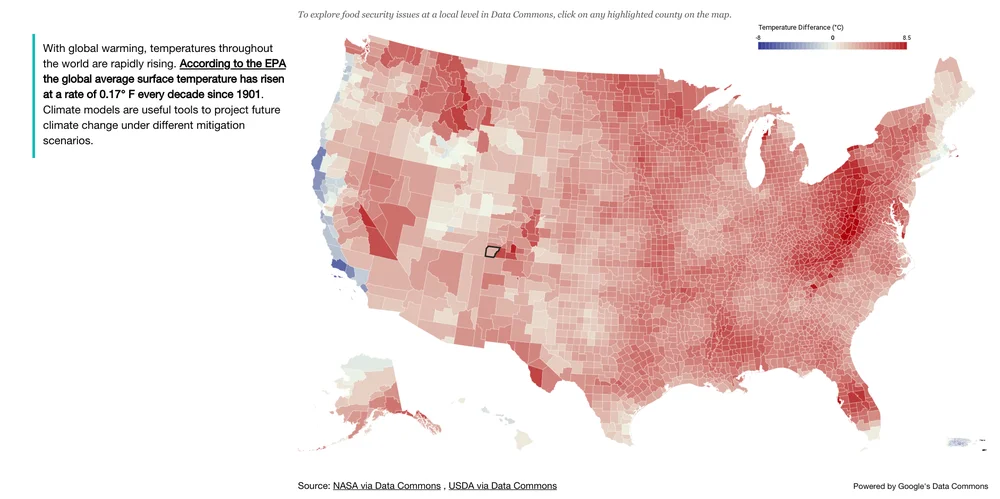
データコモンズは進行中のプロジェクトです。チームは2017年から取り組んでいますが、いくつかの面ではまだ始まったばかりであり、この取り組みには他の人々の参加が必要です。より多くのデータをアクセス可能にするためには、データの欠損箇所を特定し補完するためのパートナーが必要です。また、テックソープやリソース・フォー・ザ・フューチャー、フィーディングアメリカなどの組織が、世界の最も大きな課題に取り組む際にこのデータを活用することも必要です。まだまだ一緒にやるべきことがたくさんあります。
データコモンズを介してデータをアクセス可能にする方法について詳しく学びましょう。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「VoAGI調査:データサイエンスの支出とトレンド2023 H2における同業他社とのベンチマーク」
- 「PyGraftに会ってください:高度にカスタマイズされた、ドメインに依存しないスキーマと知識グラフを生成する、オープンソースのPythonベースのAIツール」
- 「コンピュータビジョンと言語モデルが見たものを理解する手助け」
- 「パインコーンベクトルデータベースの包括的なガイド」
- 「Seerの最高データオフィサーであるDr. Serafim Batzoglouによるインタビューシリーズ」
- 「PandasAIを用いたデータ分析における生成型AIの活用」
- 「私たちはデータサイエンスシステムを仮想化すべきでしょうか – それともしないべきでしょうか?」
