インデータベース分析:SQLの解析関数の活用
データベース分析 SQLの解析関数の活用

今日のデータ駆動型の世界では、データ分析の重要性と、利用可能なデータから価値ある洞察を提供することを誰もが知っています。しかし、時には、データ分析はデータアナリストにとって非常に困難で時間のかかるものになります。現在では、生成されるデータの爆発的な増加と、それに対して複雑な分析技術を実行するための外部ツールの必要性が理由です。
しかし、データベース内でデータを分析し、大幅に簡略化されたクエリで行うことはできませんか?これは、SQL解析関数を使用することで実現できます。この記事では、SQLサーバー内で実行されるさまざまなSQL解析関数について、詳細と実践的な例を交えて説明します。このチュートリアルの前提条件は、SQLクエリの基本的な実践的な知識です。
デモテーブルの作成
チュートリアルに沿って簡単に追いかけるために、デモテーブルを作成し、すべての解析関数をこのテーブルに適用します。
- 深層学習を用いた強力なレコメンデーションシステムの構築
- ML プレゼンテーションに PowerPoint を使うのをやめて、代わりにこれを試してみてください
- Matplotlibを使用してインフォグラフィックを作成する
注意:このチュートリアルで説明されている一部の関数はSQLiteには存在しません。したがって、MySQLまたはPostgreSQLサーバーを使用することをお勧めします。
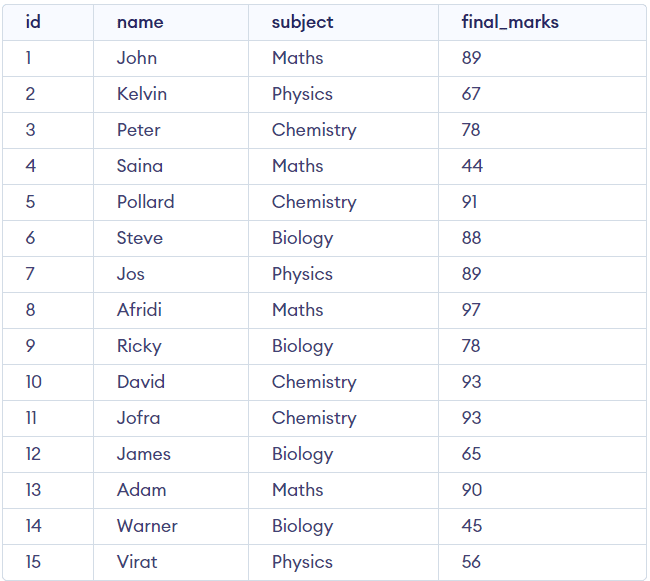
このテーブルには、いくつかの大学生のデータが含まれており、4つの列、学生ID、学生名、科目、100点満点の最終成績が含まれています。
4つの列を含む学生テーブルの作成:
CREATE TABLE students
(
id INT NOT NULL PRIMARY KEY,
NAME VARCHAR(255),
subject VARCHAR(30),
final_marks INT
); 今、そのテーブルにいくつかのダミーデータを挿入します。
INSERT INTO Students (id, name, subject, final_marks)
VALUES (1, 'John', 'Maths', 89),
(2, 'Kelvin', 'Physics', 67),
(3, 'Peter', 'Chemistry', 78),
(4, 'Saina', 'Maths', 44),
(5, 'Pollard', 'Chemistry', 91),
(6, 'Steve', 'Biology', 88),
(7, 'Jos', 'Physics', 89),
(8, 'Afridi', 'Maths', 97),
(9, 'Ricky', 'Biology', 78),
(10, 'David', 'Chemistry', 93),
(11, 'Jofra', 'Chemistry', 93),
(12, 'James', 'Biology', 65),
(13, 'Adam', 'Maths', 90),
(14, 'Warner', 'Biology', 45),
(15, 'Virat', 'Physics', 56);次に、テーブルを視覚化します。
SELECT *
FROM students出力:
解析関数を実行する準備ができました。
RANK() & DENSE_RANK()
RANK()関数は、指定された順序に基づいてパーティション内の各行に特定のランクを割り当てます。同じパーティション内で行が同じ値を持つ場合、それらに同じランクが割り当てられます。
以下の例を使って、もっと明確に理解しましょう。
SELECT *,
Rank()
OVER (
ORDER BY final_marks DESC) AS 'ranks'
FROM students;出力:
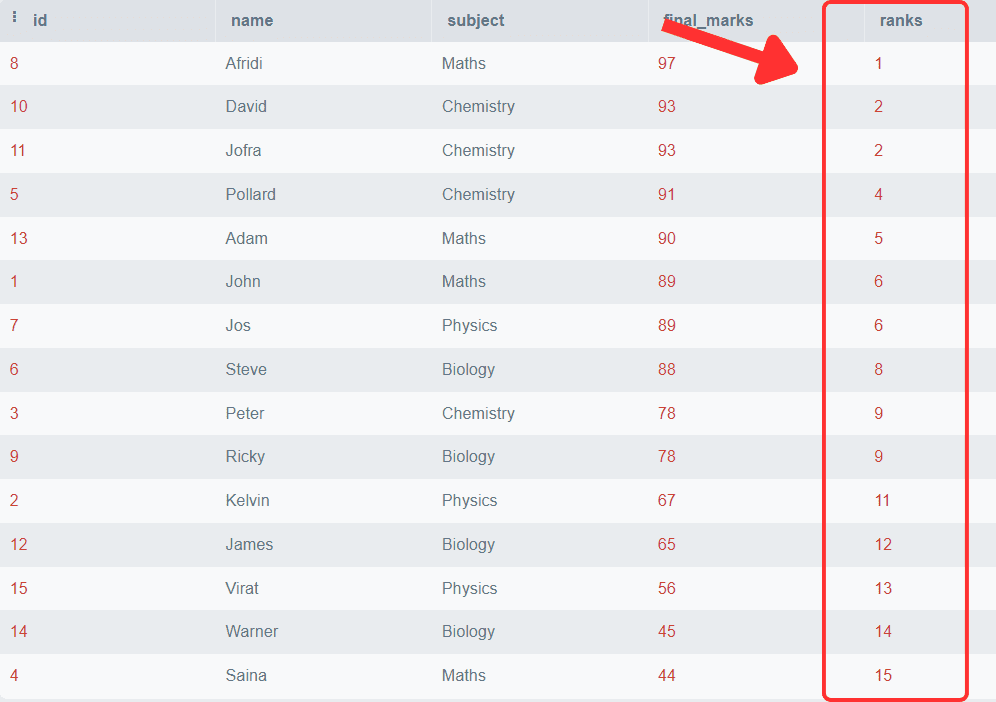
最終成績が降順に並べられ、各行に特定のランクが関連付けられていることがわかります。同じ点数を持つ学生は同じランクを取得し、重複行の後続のランクはスキップされます。
さらに、各科目のトップ学生も見つけることができます。すなわち、科目に基づいてランクをパーティション分割することができます。その方法を見てみましょう。
SELECT *,
Rank()
OVER (
PARTITION BY subject
ORDER BY final_marks DESC) AS 'ranks'
FROM students;出力:
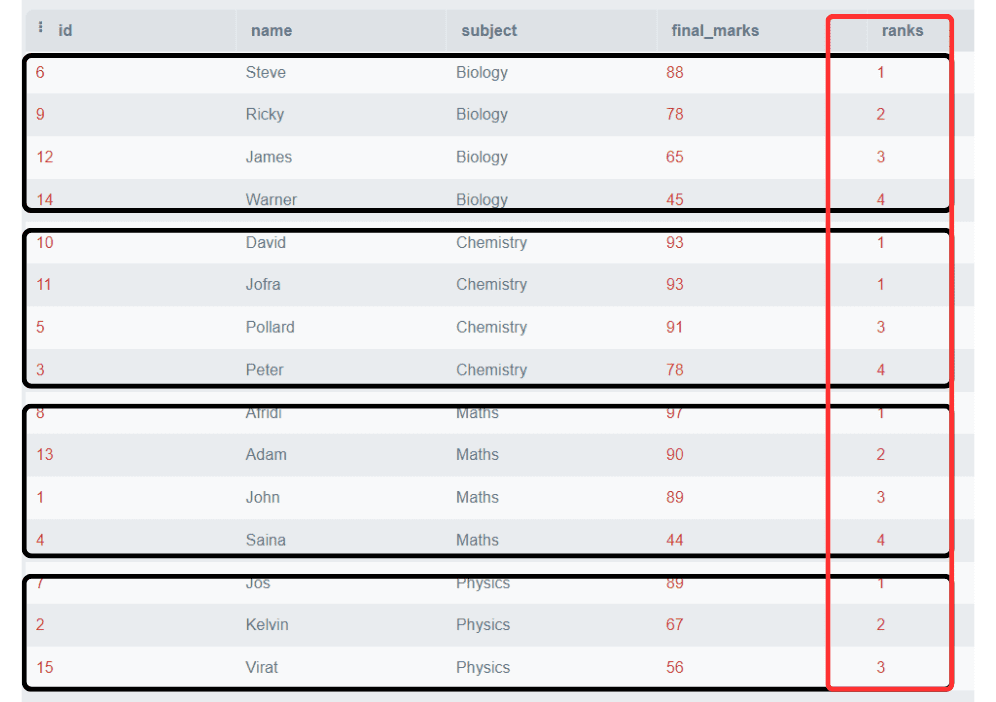
この例では、科目に基づいてランキングをパーティション分割し、ランクは各科目ごとに個別に割り当てられています。
注意: 化学の科目で2人の学生が同じ点数を取り、1位としてランク付けされ、次の行のランクは直接3から始まります。2のランクはスキップされます。
これは、RANK()関数の特徴であり、必ずしも連続的にランクを生成する必要はないということです。次のランクは、前のランクと重複する数値の合計になります。
この問題を解決するために、DENSE_RANK()が導入され、RANK()関数と同様に機能しますが、常に連続的にランクが割り当てられます。以下の例を参照してください:
SELECT *,
DENSE_RANK()
OVER (
PARTITION BY subject
ORDER BY final_marks DESC) AS 'ranks'
FROM students;出力:
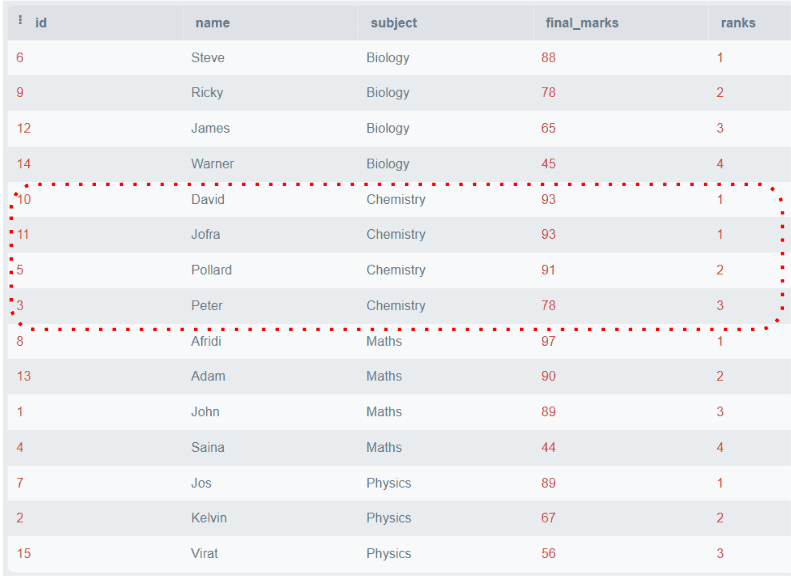 上記の図は、重複したマークが同じパーティションにある場合でも、すべてのランクが連続していることを示しています。
上記の図は、重複したマークが同じパーティションにある場合でも、すべてのランクが連続していることを示しています。
NTILE()
NTILE()関数は、行を指定された数(N)のほぼ同じサイズのバケットに分割するために使用されます。各行は1からN(バケットの総数)までのバケット番号が割り当てられます。
また、PARTITION BYおよびORDER BY句で指定された特定のパーティションまたは順序にNTILE()関数を適用することもできます。
Nが行数で完全に割り切れない場合、関数は差が1で異なるサイズのバケットを作成します。
構文:
NTILE(n) OVER (PARTITION BY c1, c2 ORDER BY c3)NTILE()関数は、必須のNという1つのパラメーターを取ります。バケットの数や、PARTITION BYおよびORDER BY句のようなオプションのパラメーターを指定することもできます。 NTILE()は、これらの句で指定された順序に基づいて行を分割します。
「Students」テーブルを考慮した例を見てみましょう。最終的なマークに基づいて学生をグループに分割したいとします。三つのグループを作成します。グループ1には最高の成績を持つ学生が含まれます。グループ2には平凡な学生が含まれ、グループ3には低い成績の学生が含まれます。
SELECT *,
NTILE(3)
OVER (
ORDER BY final_marks DESC) AS bucket
FROM students; 出力:
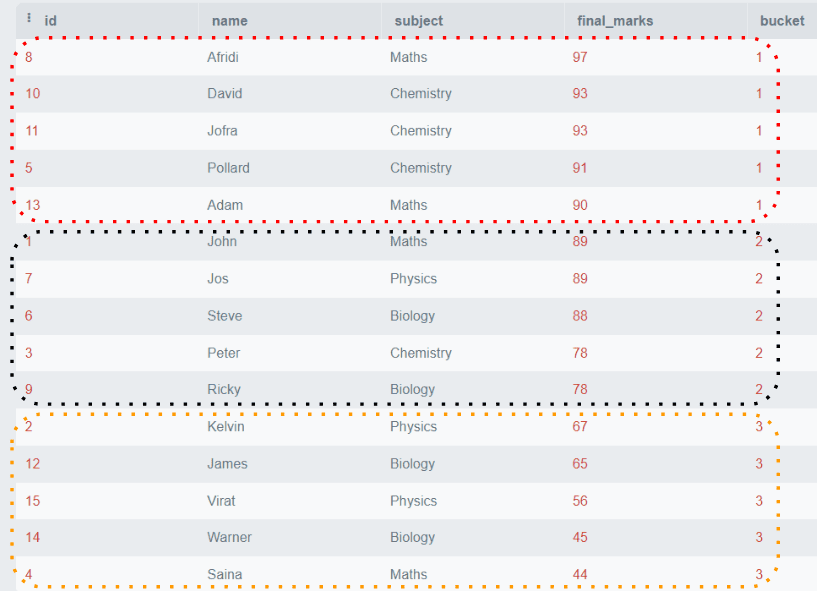
上記の例では、すべての行がfinal_marksで並べ替えられ、それぞれのグループに5行ずつ含まれています。
NTILE()は、特定の基準に基づいてデータを等しいグループに分割したい場合に役立ちます。アイテムの購入に基づいた顧客セグメンテーションや、従業員のパフォーマンスの分類などのアプリケーションで使用することができます。
CUME_DIST()
CUME_DIST()関数は、指定されたパーティションまたは順序内の各行における特定の値の累積分布を見つけます。累積分布関数(CDF)は、確率変数Xがx以下である確率を示します。これはF(x)と表され、その数学的な式は以下のように表されます。
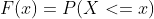
P(x)は確率分布関数です。
単純な言葉で言えば、CUME_DIST()関数は、現在の行値以下の値を持つ行の割合を返します。これにより、データの分布や値の相対的な位置を分析するのに役立ちます。
SELECT *,
CUME_DIST()
OVER (
ORDER BY final_marks) AS cum_dis
FROM students; 出力:
上記のコードは、final_marksに基づいてすべての行を順序付けし、累積分布を見つけるものですが、データを科目に基づいて分割したい場合は、PARTITION BY句を使用することができます。以下にその方法の例を示します。
SELECT *,
CUME_DIST()
OVER (
PARTITION BY subject
ORDER BY final_marks) AS cum_dis
FROM students; 出力:
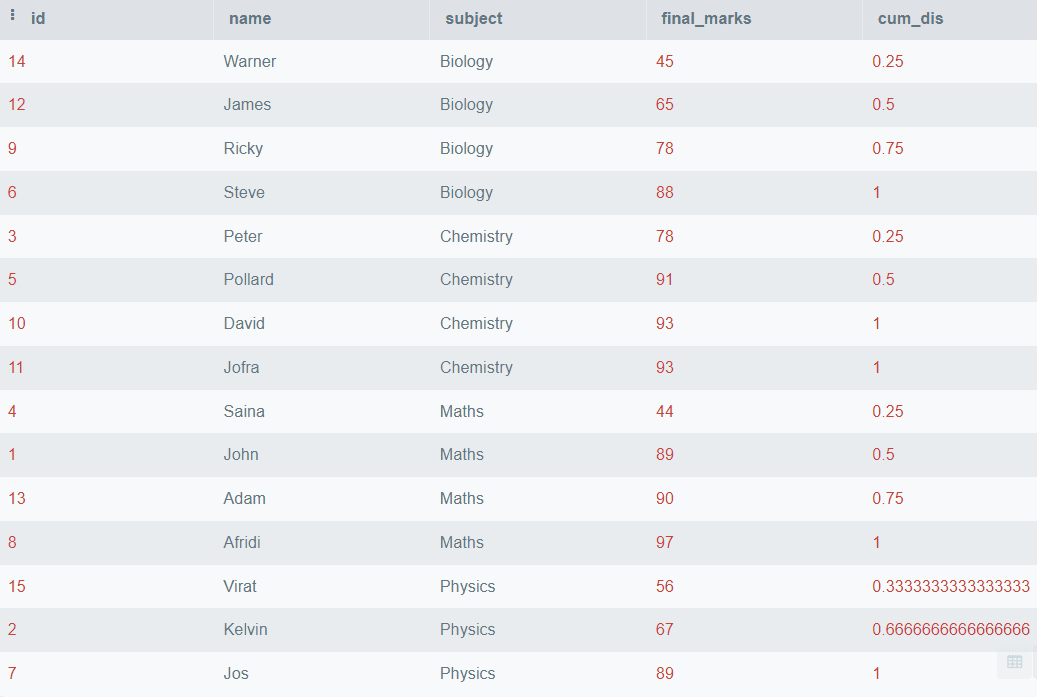
上記の出力では、科目名で分割されたfinal_marksの累積分布を見ることができます。
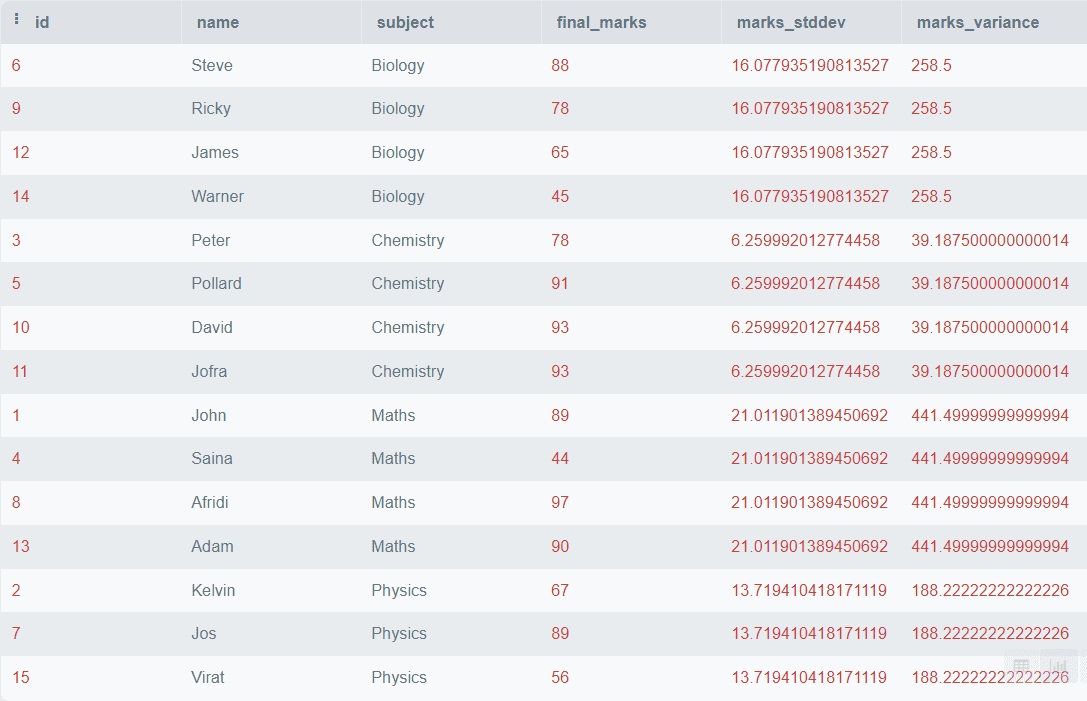
STDDEV() と VARIANCE()
VARIANCE()関数は、パーティション内の特定の値の分散を求めるために使用されます。統計学では、分散は数値がその平均値からどれだけ遠いかを表し、また数値間の変動の度合いを表します。分散は?^2で表されます。
STDDEV()関数は、パーティション内の特定の値の標準偏差を求めるために使用されます。標準偏差はデータの変動を測定し、分散の平方根と等しい値です。標準偏差は?で表されます。
これらのパラメータは、データの分散と変動性を見つけるのに役立ちます。具体的な方法を見てみましょう。
SELECT *,
STDDEV(final_marks)
OVER (
PARTITION BY subject) AS marks_stddev,
VARIANCE(final_marks)
OVER (
PARTITION BY subject) AS marks_variance
FROM students; 出力: 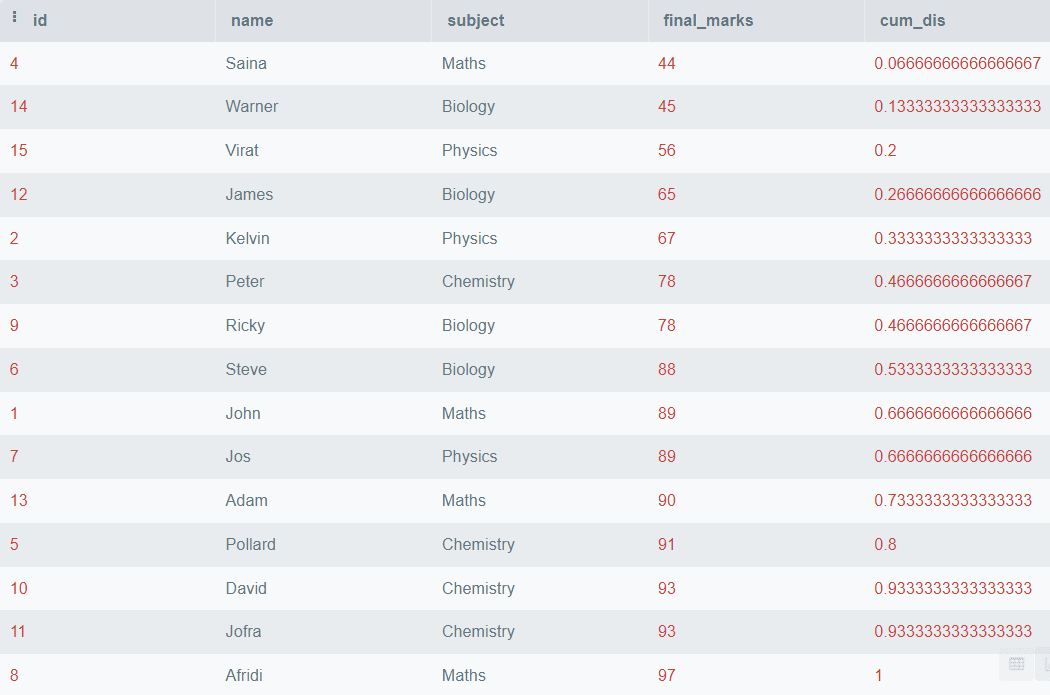 上記の出力は、各科目の最終成績の標準偏差と分散を示しています。
上記の出力は、各科目の最終成績の標準偏差と分散を示しています。
FIRST_VALUE() と LAST_VALUE()
FIRST_VALUE()関数は、特定の順序に基づいてパーティションの最初の値を出力します。同様に、LAST_VALUE()関数はそのパーティションの最後の値を出力します。これらの関数は、指定されたパーティションの最初と最後の出現を特定したい場合に使用することができます。
構文:
SELECT *,
FIRST_VALUE(col1)
OVER (
PARTITION BY col2, col3
ORDER BY col4) AS first_value
FROM table_name結論
SQLの分析関数を使用すると、SQLサーバー内でデータ分析を行うための関数が提供されます。これらの関数を使用することで、データの真の潜在能力を引き出し、貴重な洞察を得てビジネスを拡大することができます。上記で説明した関数以外にも、複雑な問題を素早く解決するための多くの優れた関数があります。Microsoftのこの記事からこれらの分析関数についてもっと詳しく読むことができます。アリャン・ガーグは、電気工学のB.Tech.学生で、現在は学部の最終年度です。彼の関心はWeb開発と機械学習の分野にあります。彼はこの関心を追求し、これらの方向でさらに活動することを熱望しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
