データベーススキーマの逆エンジニアリングと品質チェック:GPT vs. Bard
データベーススキーマの逆エンジニアリングと品質チェック:GPT vs. Bard
LLMsは、統合データセットをリバースエンジニアリングして、元のデータベースを設計し、対応するデータ品質チェックを提案することができますか?

データ活動に対してジェネレーティブAIを活用する方法についての私の前の投稿に続き、ここでは、あるデータチームが機能(たとえば人事)から統合データセットを受け取り、将来のクエリを処理するために適切なデータモデルをデータプラットフォームに再設計する必要があるユースケースを探ってみたいと思います。
GPT-4とBardの回答を比較し、どちらのモデルがより関連性の高い回答を提供するのかを検討します。
(注:ノートブックとデータソースは記事の最後に利用可能です)
初期(および最終)データセット
ビジネスソリューションでは、しばしば所有しているシステムから情報をレポート形式で抽出するだけであり、運が良ければAPIを介してアクセスできる場合もあります。
これは”MyCompany”の場合であり、HRISレガシーシステムでは、すべての従業員の抽出を提供することしかできず、会社に関する多くの詳細情報、機密情報も含まれています。
Data Meshの原則に従い、人事チームはこのデータを公開したいと考えていますが、レポートそのままでは利用できないこと、さらには「給与」、「年齢」、「年次評価」といった列が引き金となっている機密性の問題にも言及しなければなりません。
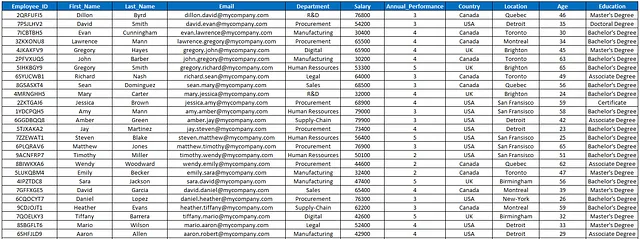
データモデルのリバースエンジニアリング
データチームとの対話の中で、テーブル周りの全員がすぐに理解することは、このデータセットをすべての機能/従業員に配信することはできず、複数のテーブルに分割する必要があるということです。
これらのテーブルのいくつかは、他の分析やユースケースで多くの人に活用することができます:
- 内部部門のリスト
- メール、部門、国、場所を含む従業員リスト
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
