価値あるデータテストの作成方法
データテストの作成方法
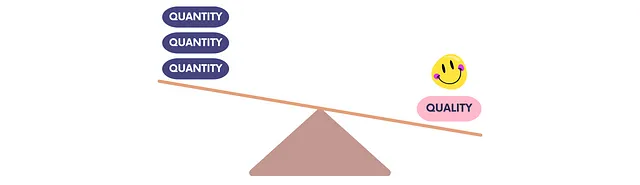
重要なのは量ではなく品質です。
データの品質については、昨年に広く議論されてきました。データの契約、データ製品、データ可観測性ツールの普及は、データの品質を向上させるためにデータの専門家が取り組んでいることを示しています。私たちは皆、これを見るのが好きです!
データソリューションの重要な要素の1つはデータのテストです。これはデータの品質を検証するための最も基本的で実用的な方法の1つであり、多くのデータソリューションに明示的または暗黙のうちに組み込まれています。
この効果的な手法はデータチームに多大な利益をもたらしましたが、より多くのテストを行うことが必ずしもデータの品質を向上させるわけではないため、その潜在的な価値を最大化する方法について疑問が生じます。この記事では、データのテストのデザインにアプローチを示したいと思います。ここで少しの光を当てることができるでしょう。
これらの手法を組み合わせて、最適なバランスを見つけることをお勧めします。
品質 > 量
私はテストを作成することが好きな人の1人です。テストによって解決策への自信が高まるからです。ソフトウェアエンジニアリングのバックグラウンドを持つ私は、かつて「テストが多ければ多いほど良い」というモットーで生きていました。常に、シンプルなデータテスト作成メソッドを提供するデータフレームワークに興奮していました。
しかし、過剰な数のデータテストを持つことの副作用を過小評価していました。(副作用があるのか?あります!)まず、データテストとユニットテスト(つまり、ロジックテスト)の違いを理解しましょう。要するに、ユニットテストは、私たちが書いたコードの論理の正しさを検証するためのものです。ユニットテストが多ければ多いほど、エッジケースの処理に自信を持つことができます。しかし、データテストはコードの論理だけでなく、ソースデータの品質、データパイプラインの設定、上流の依存関係なども検証します。指標は無限であり、圧倒されることもあります。念のために多くのテストを作成することは誘惑されるかもしれませんが、常に価値をもたらすわけではなく、不要なノイズを発生させる可能性があります。たとえば、データパイプラインがユーザーにたまにしか使用されない場合、毎日の新鮮さのテストは必要ありませんし、データパイプラインのすべてのステージが同じテストを必要とするわけではありません。重複したデータテストは冗長なアラートを引き起こすだけです。
ある時点で、データテストの作成に迷い、不要なテストが多くなり、誤ったアラートが発生しました。 データの品質を確保するためには、まずデータテストの品質を確保する必要があることを学びました。 数量は必ずしも品質と相関しないのです。
使用に適した品質

データは製品として扱われることができます。データパイプラインは、生のデータ入力を受け取り、データ製品を生成するデータ製造システムと見なすことができます。データの消費者はデータを購入するわけではありませんが、使用するかどうかを決めることができ、要件やフィードバックを提供することもできます。
品質の測定においては、「使用に適した品質」という概念が広く採用されています。これは、最終的には製品の成功を決定するのは消費者ですので、「フルカスタマーボイスを捉える」ことが重要です。たとえば、大学図書館を建設する場合、学生や教師を念頭に置くことが重要であり、多様な興味や教育要件をカバーするための様々な本やリソースが必要です。
データ製品に関しては、報告データが良い例です。価値があるとみなされるためには、エンジニアはステークホルダーと緊密に連携し、精度、信頼性、整合性、タイムリネスなどの規制要件を理解し、それに応じたデータテストを作成する必要があります。
このアプローチは、テストの作成の旅の良い出発点です。特に、データの消費者が要件を明確に持ち、データの品質についてよく理解している場合は、データエンジニアの生活をかなり楽にすることができます。ただし、ステークホルダーの要件だけに頼ることはしばしば十分ではありません。上流の依存関係や技術的なエラーを考慮に入れずに、外部の視点でデータを評価するためです。その場合、次のセクションで紹介するデータ品質フレームワークがほとんどのシナリオをカバーするのに役立ちます。
データ品質の次元
データ品質の消費者視点から始めるのは間違いなく価値のある初歩的なステップです。しかし、テスト範囲の完全性をカバーできないかもしれません。多くの文献レビューがこの問題に取り組んでおり、ほとんどのユースケースに関連するデータ品質の次元を提供しています。データの消費者と共にリストを見直し、適用可能な次元を共同で決定し、それに応じたテストを作成することをお勧めします。
| 正確性 | フォーマット | 比較可能性 || 信頼性 | 解釈可能性 | 簡潔さ || タイムリネス | コンテンツ | 偏見からの自由 || 関連性 | 効率性 | 有益性 || 完全性 | 重要性 | 詳細レベル || 通貨性 | 十分性 | 定量性 || 一貫性 | 利用可能性 | 範囲 || 柔軟性 | 有用性 | 理解可能性 || 精度 | 明快さ | |このリストが長すぎてどこから始めれば良いかわからないかもしれません。データ製品や情報システムは、外部ビューと内部ビューの2つの視点から観察または分析することができます。
外部ビュー
外部ビューはデータの使用と組織との関係についてのものです。それはしばしば実世界のシステムを表現するための機能を持つ「ブラックボックス」と考えられます。外部ビューに該当する次元は、ビジネスによって駆動されます。これらの次元の評価は主観的である場合があり、それらのために自動化されたテストを作成することは常に簡単ではありません。しかし、いくつかよく知られた次元を見てみましょう:
- 関連性:データが分析に適用可能で役立つ程度。新製品を宣伝する市場キャンペーンを考えてみましょう。お客様の属性データや購買データなど、すべてのデータ属性がキャンペーンの成功に直接寄与する必要があります。市の天気や株価などのデータはこの場合には関連性のないデータです。もう1つの例は詳細レベル(粒度)です。ビジネスが市場データを日単位で欲しいと思っている場合に、週単位で提供される場合は関連性がなく役に立ちません。
- 表現:データがデータの消費者に対して解釈可能であり、データの形式が一貫して記述的である程度。データ品質の評価において、表現層の重要性はしばしば見落とされます。これにはデータの形式(一貫性とユーザーフレンドリーさ)とデータの意味(理解可能性)が含まれます。例えば、CSVファイルでデータが利用可能であることが予想され、列の説明が記載されており、値がセントではなくEUR通貨であることを考えてみてください。
- タイムリネス:データがデータの消費者にとって新鮮である程度。例えば、ビジネスが売上トランザクションデータを販売時点から1時間以内の最大遅延で必要とする場合。これはデータパイプラインが頻繁に更新される必要があることを示しています。
- 正確性:データがビジネスルールに準拠している程度。データメトリクスは、データマッピング、丸めモードなどの複雑なビジネスルールに関連することがよくあります。データロジックの自動化テストは強くお勧めし、できるだけ多くのテストを行うことが理想です。
これらの4つの次元のうち、データテストを作成する際には、タイムリネスと正確性が比較的直接的です。タイムリネスはタイムスタンプの列と現在のタイムスタンプを比較することで達成できます。正確性のテストは顧客のクエリを通して実施できます。
内部ビュー
内部ビューは、特定の要件に依存しない操作に関連しています。これらは、どのようなユースケースであっても重要です。内部ビューの次元は、外部ビューのビジネス駆動の次元とは対照的に、より技術駆動の次元です。これはまた、データテストが消費者に依存せず、ほとんどの場合に自動化できることを意味します。次にいくつかの重要な視点をご紹介します:
- データソースの品質:データソースの品質は、最終データの品質に大きな影響を与えます。データ契約は、ソースデータの品質を確保するための素晴らしい取り組みです。ソースのデータの消費者として、データ製品を評価する際にデータステークホルダーが行うようなアプローチを採用することができます。
- 完全性:情報が完全に保持されている程度。データパイプラインの複雑さが増すにつれて、中間段階で情報の損失が発生する可能性が高くなります。例えば、顧客トランザクションデータを保存する金融システムを考えてみましょう。完全性テストは、すべてのトランザクションが適切にライフサイクルを経て進行し、省略または抜け漏れがないことを確認します。例えば、最終的な口座残高は実世界の状況を正確に反映し、すべてのトランザクションを適切に捉えているはずです。
- 一意性:この次元は完全性テストと密接に関連しています。完全性が失われないことを保証する一方で、一意性はデータ内での重複が発生しないことを保証します。
- 一貫性:データが内部システム間で日々一貫している程度。不一致は、データのシロや一貫性のないメトリック計算方法に起因する一般的なデータの問題です。一貫性の問題のもう一つの側面は、データが安定した成長パターンを持つことが予想される日々の間に発生します。どのような逸脱もさらなる調査のための旗となるべきです。
各次元は1つまたは複数のデータテストに関連付けることができることに注意する価値があります。重要なのは、特定のテーブルやメトリクスに対して適切な次元の適用を理解することです。それだけでなく、より多くのテストを使用すればするほど、良い結果が得られます。
これまで、外部ビューと内部ビューの次元について説明してきました。将来のデータテストの設計では、外部および内部の視点の両方を考慮することが重要です。適切な質問を適切な人々にすることで、効率を向上させ、意思疎通のミスを減らすことができます。
データテストのさらなるヒント
最後のセクションでは、データテストの作成に関するいくつかの実践的なヒントを共有したいと思います。これらは私の日々の業務から得たものですが、コメントでさらに情報を共有していただければ幸いです。
- 間違ったデータ対正確なデータ: 多くのデータソリューションでは、データテストは通常、モデルが更新された後に実施されます。これは、問題が認識されるまでにデータが既に「破損」してしまっていることを意味します。もし「間違ったデータ」よりも「データが存在しないこと」を好む場合は、まずテーブルを一時的な場所に実体化し、その後テストを実施します。テストが成功した場合にのみ、パイプラインがテーブルを元の宛先にコピーするように進みます。そうでない場合は、プロセスが停止します。
- 調整テスト: 調整テストは、通常、ソースと宛先のデータセットの間のデータの一貫性と正確性を比較するデータの検証プロセスです。例えば、2つのパイプラインはトランザクションを処理するために設計されており、両方のシステムとソースからの総トランザクション金額を比較することは価値があります。データパイプライン内の欠陥を示す可能性がある任意の不一致の存在です。
- 余裕を持ったテスト: ステークホルダーから次のようなステートメントを得るかもしれません:「この列に0があっても問題ありませんが、過度な量は避けるべきです。」これは、一定のパターンからの逸脱を捉えたいという意味です。多くの現代のデータモニタリングツールは異常検知機能を提供していますが、そのオプションがない場合は、余裕を持ったテストを作成することから始めることができます。例えば、合計行のうち0の値を持つ行は5%以下であるべきです。
結論
いつものように、この記事が役に立ち、インスピレーションを与えることを願っています。重要なポイントは、作成したデータテストの量に過度に注力しないことです。すべての列に同じテストを追加することは意味がありません。むしろ、ノイズを多く生み出し、生産性を低下させるだけです。
データの消費者やデータの提供者と話す前に、データ品質のフレームワークを心に留めておきましょう。賢く質問し、フレームワークを使用して、ステークホルダーにデータの追加的な視点を考慮するよう促しましょう。乾杯!
参考文献
- オントロジーの基礎にデータ品質の次元を固定する
- 正確性の向こうにあるもの: データ品質がデータの消費者にとって意味するもの
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
