データセットシフトのフレームワークの整理:例
データセットシフトのフレームワークの整理:例' can be condensed to 'データセットシフトのフレームワーク整理:例'.
3つの確率要素に応じた条件付き確率の変化方法
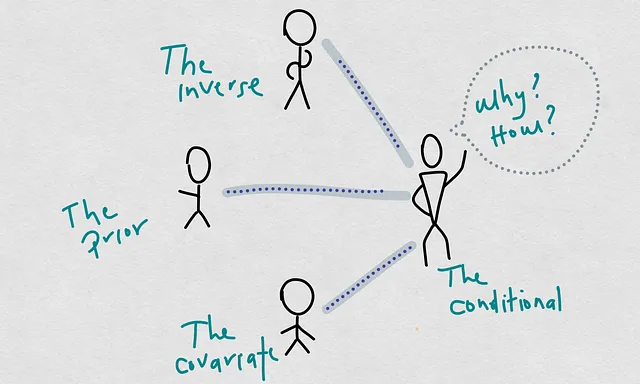
最近、モデルの性能低下の原因について話しました。つまり、モデルの予測品質がトレーニングおよびデプロイメント時の品質に比べて低下することを指します。この別の記事では、モデルの劣化原因について新しい考え方を提案しました。そのフレームワークでは、いわゆる条件付き確率が大きな原因となります。
条件付き確率は、定義上、3つの確率から構成されます。これらを私は具体的な原因と呼んでいます。この概念の再構築による最も重要な学びは、共変量のシフトと条件付きシフトが2つの別々または並行した概念ではないということです。共変量のシフトに応じて条件付きシフトが発生することがあります。
この再構築により、原因について考えることがより容易になり、アプリケーションで観察されるシフトをより論理的に解釈することができると思います。
これは、機械学習モデルの原因とモデルの性能のスキームです:
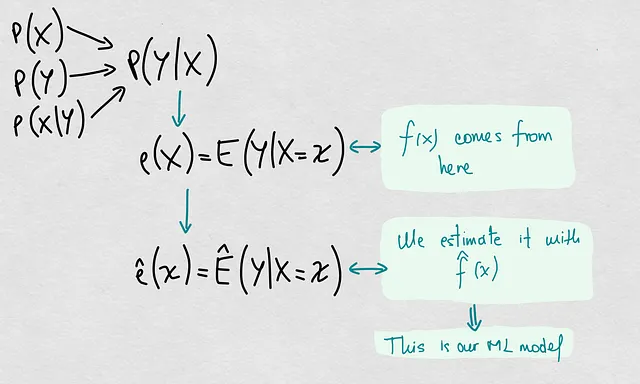
このスキームでは、原因とモデルの予測性能を結びつける明確なパスが見えます。統計学的学習において私たちがする必要がある基本的な仮定の1つは、私たちのモデルが実際のモデル(実際の決定境界、実際の回帰関数など)の「良い」推定量であるということです。ここで「良い」という言葉には、バイアスのない推定量、精度の高い推定量、完全な推定量、十分な推定量など、さまざまな意味があります。しかし、単純化と今後の議論のために、予測誤差が小さいという意味で「良い」と言います。言い換えれば、私たちはそれらが実際のモデルを代表するものであると仮定しています。
この仮定により、推定モデルのモデル劣化の原因を確率P(X), P(Y), P(X|Y), およびその結果, P(Y|X)から求めることができます。
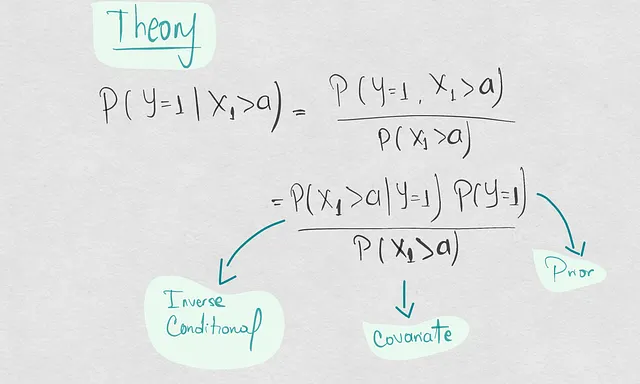
では、今日は3つの確率P(X|Y), P(X), および P(Y)の関数としてP(Y|X)がどのように変化するかを実例として紹介し、さまざまなシナリオを進めてみましょう。これを行うために、2D空間のいくつかのポイントの集団を使用し、これらのサンプルポイントから確率をラプラスの方法で計算します。その目的は、モデルの劣化の原因の階層スキームを理解することであり、P(Y|X)をグローバルな原因、他の3つを具体的な原因とします。その方法で、潜在的な共変量のシフトが独立したシフトではなく、条件付きシフトの議論の根拠であることがどのようになるかを理解することができます。
例
今日の授業で描く例は非常に単純なものです。2つの共変量X1とX2と出力Yがバイナリ変数である空間があります。モデルの空間は次のようになります:
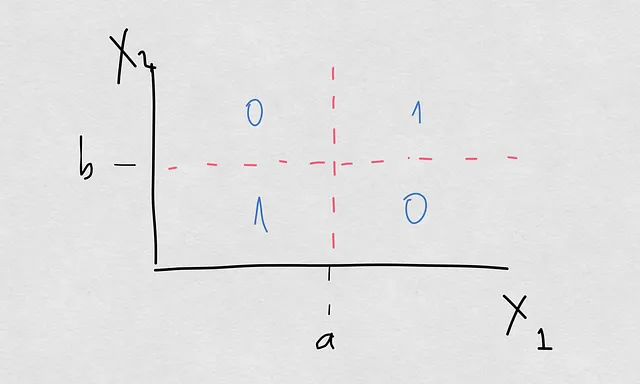
そこには、空間が4つの象限に整理され、この空間の決定境界は十字架です。これは、モデルが1つ目と3つ目の象限にある場合にサンプルをクラス1に分類し、それ以外の場合はクラス0に分類することを意味します。この演習では、P(Y=1|X1>a)を比較するために異なるケースを進めます。なぜX2も取らないのか疑問に思うかもしれませんが、それは単純化のためだけです。私たちが理解したい洞察には影響を与えません。
もしまだ苦い気持ちを持っている場合、P(Y=1|X1>a)を取ることは、理論的にはP(Y=1|X1>a, -inf <X2 < inf)と同等ですので、X2も考慮に入れています。
参照モデル
まず、ショーケースの確率を計算し、1/2を得ます。ここでは、サンプルグループが空間全体にわたってかなり均一であり、先行確率も均一です。
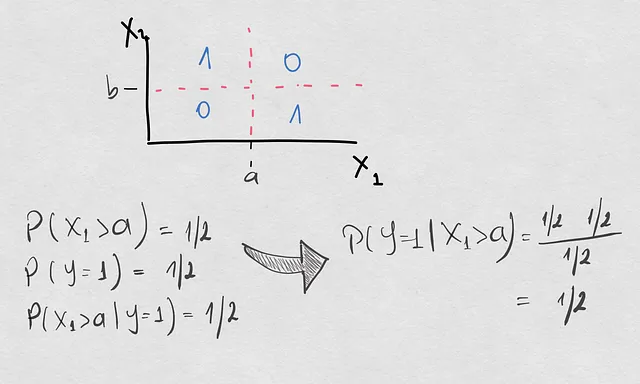
シフトが発生します
- 下右の象限に1つの追加サンプルが現れます。ではまず、共変量シフトについて話しているのか、条件付きシフトについて話しているのかを確認しましょう。
実際には、以前よりもX1>aでのサンプリングが増えているため、共変量シフトが発生しています。したがって、これは共変量シフトであり、条件付きシフトではないのでしょうか? それでは確認してみましょう。更新されたポイントセットで前と同じ確率の計算を行った結果(変化した確率はオレンジ色で表示されています):
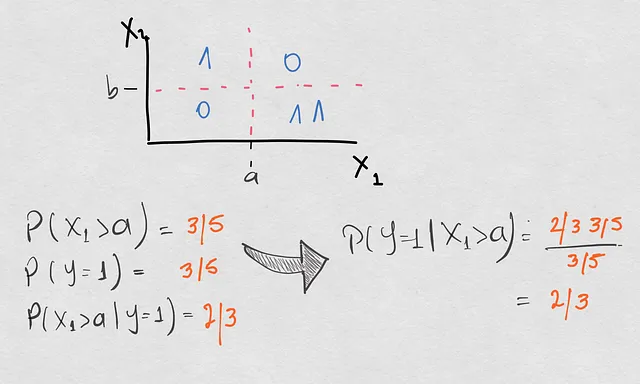
ここで何を見ましたか? 実際には、共変量シフトだけでなく、すべての確率が変化しました。先行確率も変化し、クラス1の新しいポイントによってこのクラスの発生率がクラス2よりも大きくなりました。そして、逆確率P(X1>a|Y=1)も先行シフトのために変化しました。全体的にこれらの変化により、条件付きシフトが発生し、P(Y=1|X1>a)は1/2ではなく2/3になりました。
ここに思考バブルがあります。実は非常に重要なものです。
このサンプリング分布のシフトにより、モデル全体で役割を果たすすべての確率にシフトが生じました。ただし、初期サンプリングに基づく決定境界は有効のままでした。
これはどういう意味ですか?
条件付きシフトが発生したとしても、決定境界は必ずしも劣化するわけではありません。なぜなら、決定境界は期待値に基づいており、現在のシフトに基づいてこの値を計算すると、境界は同じままであるが条件付き確率が異なる可能性があるからです。
2. 第1象限のサンプルはもはや存在しません。
したがって、X1>aに対しては何も変わりません。ここでショーケースしている条件付き確率とその要素がどのように変化するかを見てみましょう。

直感的には、X1>a内では何も変わらず、条件付き確率も同じままです。ただし、P(X1>a)を見ると、トレーニングサンプリングと比較して1/2ではなく2/3になっています。したがって、ここでは条件付きシフトなしの共変量シフトが発生しています。
数学的な観点から考えると、共変量確率が変わらずに条件付き確率が変わることはどのようにして起こるのでしょうか? これは、P(Y=1)およびP(X1>a|Y=1)が共変量確率に応じて変化したためです。したがって、補償により条件付き確率は変わらないままです。
これらの変化により、前と同様に決定境界は有効のままでした。
3. 異なる象限にいくつかのサンプルを投入しながら、決定境界は有効のままでした。
ここでは2つの追加の組み合わせがあります。1つの場合では、事前確率は変わらず、他の2つの確率が変化しましたが、条件付き確率は変化しませんでした。2つ目の場合では、逆確率のみが条件付きのシフトに関連していました。以下でシフトを確認してください。後者は非常に重要なものなので、見逃さないでください!
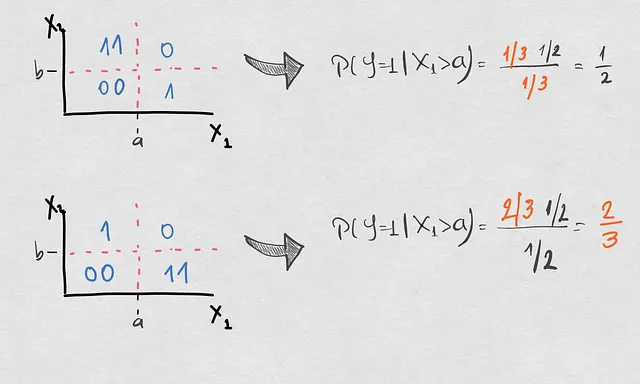
これにより、他の3つの確率の関数として条件付き確率がどのように変化するかについて、かなり堅固な視点を持つことができます。しかし、もっと重要なことは、すべての条件付きシフトが既存の決定境界を無効にするわけではないということも知っているということです。では、それは一体どういうことでしょうか?
コンセプトドリフト
前の投稿では、コンセプトドリフト(またはコンセプトシフト)をより具体的に定義する方法も提案しました。提案は次の通りです:
確率のシフトが発生すると、決定境界または回帰関数が無効になった場合、コンセプトの変化と呼びます。
ですので、決定境界が無効になると、確実に条件付きシフトが発生しています。逆に、前の投稿で議論したように、上記の例でも見たように、必ずしも逆は真ではありません。
これは実用的な観点からはあまり素晴らしくないかもしれませんが、確かにコンセプトドリフトがあるかどうかを知るためには、境界または関数を再評価する必要があるかもしれません。しかし、少なくとも理論的な理解のためには、これは非常に魅力的です。
以下は、条件付きのシフトが自然に発生しているが、共変量のシフトや事前確率のシフトがない例です。
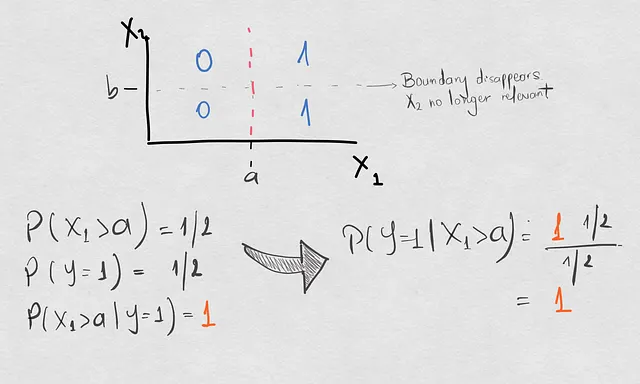
これらの要素の分離はどれほどクールですか?ここでは逆確率のみが変化しましたが、前述のシフトとは対照的に、この逆確率の変化は決定境界の変化と関連していました。現在、有効な決定境界は、X1>aによる分離のみで、X2によって規定される境界は破棄されます。
何を学びましたか?
モデルの劣化の原因の分解について、非常にゆっくりと進んできました。確率要素のさまざまなシフトとそれらが機械学習モデルの予測性能の劣化と関係する方法を学びました。最も重要な洞察は次のとおりです:
- 条件付きのシフトは、機械学習モデルの予測性能のグローバルな原因です
- 具体的な原因は、共変量のシフト、事前確率のシフト、逆確率のシフトです
- 決定境界が有効のままであるときに、さまざまな確率のシフトが発生する可能性があります
- 決定境界の変化は条件付きのシフトを引き起こしますが、逆は必ずしも真ではありません!
- コンセプトドリフトは、全体的な条件付き確率分布ではなく、決定境界と特に関連しているかもしれません
これによって何が導かれるのでしょうか?この定義の階層に基づいて、私たちの実践的な解決策を再編成することが最も重要な招待です。私たちは、現在のモデルのモニタリングに関する疑問に対する望ましい答えを見つけるかもしれません。
これらの定義を使用してモデルのパフォーマンスモニタリングに取り組んでいる場合は、このフレームワークについてのご意見を共有してください。
みなさん、考えるのを楽しんでください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
