データストレージの最適化:SQLにおけるデータ型と正規化の探索
データストレージ最適化:SQLのデータ型と正規化の探索

現代では、データは新しい石油です。データストレージの最適化は、それから良いパフォーマンスを得るために常に重要です。適切なデータ型を選択し、正しい正規化プロセスを適用することは、そのパフォーマンスを決定する上で不可欠です。
この記事では、最も重要で一般的に使用されるデータ型を学び、正規化プロセスを理解します。
- 「ゼロからLLMを構築する方法」
- 「DreamBooth:カスタム画像の安定拡散」
- 「限られた訓練データで機械学習モデルは信頼性のある結果を生み出すのか?ケンブリッジ大学とコーネル大学の新しいAI研究がそれを見つけました…」
SQLにおけるデータ型
SQLには主に2つのデータ型があります:文字列と数値です。これ以外にも、ブール型、日付と時刻、配列、インターバル、XMLなどの追加のデータ型があります。
文字列データ型
これらのデータ型は、文字列を格納するために使用されます。文字列は通常、配列データ型として実装され、通常は文字のシーケンスを含みます。
- CHAR(n):
これは、文字、数字、特殊文字を含む固定長の文字列です。 n は、文字列が保持できる最大の文字数を示します。
最大範囲は0から255文字であり、このデータ型の問題は、実際の文字列の長さが指定された長さよりも短い場合でも、指定された全体のスペースを取ることです。余分な文字列の長さは、余分なメモリスペースでパディングされます。
- VARCHAR(n):
VarcharはCharと似ていますが、可変サイズの文字列をサポートでき、パディングはありません。このデータ型のストレージサイズは、文字列の実際の長さと同じです。
最大で65535文字まで格納できます。可変サイズの性質から、CHARデータ型ほどのパフォーマンスはありません。
- BINARY(n):
これはCHARデータ型と似ていますが、バイナリ文字列またはバイナリデータのみを受け入れます。画像、ファイル、またはシリアライズされたオブジェクトなどを格納するために使用できます。VARCHARデータ型と似た別のデータ型である VARBINARY(n) もバイナリ文字列またはバイナリデータのみを受け入れます。
- TEXT(n):
このデータ型も文字列を格納するために使用されますが、最大サイズは65535バイトです。
- BLOB(n): バイナリ大容量オブジェクトで、最大で65535バイトのデータを保持します。
これ以外にも、さらに多くの文字を格納できるLONGTEXTやLONGBLOBなどの他のデータ型があります。
数値データ型
- INT():
これは、数値の整数を格納できます。4バイト(32ビット)です。n は、整数値を表示するために使用される最小文字数を指定でき、最大で255までです。
範囲:
- a) -2147483648 <= 符号付きINT <= 2147483647
- b) 0 <= 符号なしINT <= 4294967295
- BIGINT():
これは、最大64ビットの大きな整数を格納できます。
範囲:
- a) -9223372036854775808 <= 符号付きBIGINT <= 9223372036854775807
- b) 0 <= 符号なしBIGINT <= 18446744073709551615
- FLOAT():
これは、ある精度で近似された小数点を持つ浮動小数点数を格納できます。小さな丸め誤差があるため、正確な精度が必要な場所には適していません。
- DOUBLE():
このデータ型は、倍精度浮動小数点数を表します。FLOATデータ型と比較して、より高い精度で小数値を格納することができます。
- DECIMAL(n, d):
このデータ型は、dで示される固定精度の正確な10進数を表します。dパラメータは小数点以下の桁数を指定し、nパラメータは数値のサイズを示します。dの最大値は30であり、デフォルト値は0です。
その他のデータ型
- BOOLEAN:
このデータ型は、TrueまたはFalseの2つの状態のみを格納します。論理演算を実行するために使用されます。
- ENUM:
ENUMはEnumerationの略で、定義済みのオプションリストから1つの値を選択することができます。また、格納される値が指定されたオプションのみであることも保証します。
例えば、colorという属性を考えてみましょう。この属性は'Red,' 'Green,' or 'Blue'のいずれかの値しか持つことができません。これらの値をENUMに入れると、colorの値は指定された色のいずれかに限定されます。
- XML:
XMLは拡張可能なマークアップ言語 (eXtensible Markup Language) の略です。このデータ型は構造化データ表現に使用されるXMLデータを格納するために使用されます。
- AutoNumber:
これは、各レコードが追加されるたびに値が自動的に増加する整数です。一意または連続した番号を生成するために使用されます。
- Hyperlink:
ファイルやウェブページのハイパーリンクを格納することができます。
これでSQLデータ型に関する議論は終わりです。他にも多くのデータ型がありますが、今回話し合ったデータ型は最も一般的に使用されるものです。
SQLにおける正規化
正規化は、データベースから冗長性、不整合、および異常を除去するプロセスです。冗長性とは、同じデータの重複した値の存在を意味し、データベースの不整合は、同じデータが複数の形式で複数のテーブルに存在することを表します。
データベースの異常とは、存在してはならないデータの突然の変更や不一致を指すことができます。これらの変更は、データの破損、ハードウェアの障害、ソフトウェアのバグなど、さまざまな理由によるものです。異常はデータの損失や不整合などの重大な結果をもたらす可能性があるため、できるだけ早く検出し修正することが重要です。主な異常のタイプは主に次の3つあります。詳細はこの記事を参照してください。
- 挿入異常:
新しく挿入された行がテーブル内で不整合を作成する場合、挿入異常が発生します。例えば、組織に従業員を追加したいが、彼の部署が割り当てられていない場合、その従業員をテーブルに追加することができず、挿入異常が発生します。
- 削除異常:
削除異常は、テーブルからいくつかの行を削除したい場合に発生し、他のデータもデータベースから削除する必要がある場合に発生します。
- 更新異常:
この異常は、いくつかの行を更新したい場合に発生し、データベースの不整合を引き起こします。
正規化プロセスには、データベースの設計を効率的で最適化され、冗長性や異常から解放されたものにするための一連のガイドラインが含まれています。1NF、2NF、3NF、BCNFなど、いくつかの正規形があります。
1. 第一正規形 (1NF)
第一正規形は、テーブルに複合属性や多値属性が存在しないことを保証します。つまり、単一の属性には1つの値だけが存在することを意味します。関係が第一正規形にある場合、すべての属性は単一の値のみを持つことになります。
例-
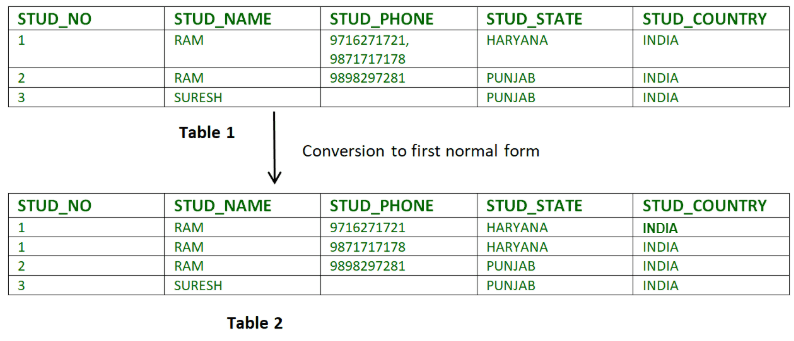
テーブル1では、属性STUD_PHONEは複数の電話番号を含んでいます。しかし、テーブル2では、この属性は第1正規形に分解されています。
2. 第2正規形
テーブルは第1正規形にある必要があり、関係に部分的な依存関係が存在してはなりません。部分的な依存関係とは、非主属性(候補キーの一部ではない属性)が、候補キーの任意の真部分集合に部分的に依存または依存していることを意味します。第2正規形にあるためには、非主属性は完全に機能し、候補キー全体に依存している必要があります。
例えば、次の属性を持つEmployeesという名前のテーブルを考えてみましょう。
EmployeeID(主キー)
ProjectID(主キー)
EmployeeName
ProjectName
HoursWorked
ここで、EmployeeIDとProjectIDは一緒に主キーを形成しています。しかし、EmployeeNameとEmployeeIDの間に部分的な依存関係があることに気付くことができます。つまり、EmployeeNameは主キーの一部(つまりEmployeeID)にのみ依存しているということです。完全な依存性のためには、EmployeeNameはEmployeeIDとProjectIDの両方に依存する必要があります。したがって、これは第2正規形の原則に違反しています。
この関係を第2正規形にするためには、テーブルを2つの別々のテーブルに分割する必要があります。最初のテーブルには、すべての従業員の詳細が含まれ、2番目のテーブルにはすべてのプロジェクトの詳細が含まれます。
したがって、Employeeテーブルには次の属性があります。
EmployeeID(主キー)
EmployeeName
そして、Projectテーブルには次の属性があります。
Project ID(主キー)
Project Name
Hours Worked
これにより、部分的な依存関係が2つの独立したテーブルを作成することで解消され、両方のテーブルの非主属性が主キーの完全なセットに依存していることがわかります。
3. 第3正規形
2NFの後でも、関係には更新の異常が存在する場合があります。それは、1つのタプルのみを更新し、他のタプルを更新しない場合に発生する可能性があります。これにより、データベースの不整合が生じます。
第3正規形の条件は、テーブルが2NFにあることであり、非主属性に対して推移的な依存関係が存在しないことです。推移的な依存関係とは、非主属性が主属性ではなく、別の非主属性に依存していることを意味します。主属性は候補キーの一部である属性です。
A、B、Cの関係R(A、B、C)を考えてみましょう。A→BおよびB→Cが2つの機能的依存関係である場合、A→Cは推移的な依存関係となります。つまり、属性Cは直接的にはAによって決定されません。Bがそれらの間の仲介者として機能します。
テーブルに推移的な依存関係が存在する場合、テーブルを別々の独立した関係に分割することで、テーブルを第3正規形にすることができます。
4. ボイス・コッド正規形
2NFおよび3NFでは、ほとんどの冗長性が除去されますが、冗長性は100%除去されていません。冗長性は、機能的依存関係の左側が候補キーまたはスーパーキーでない場合に発生する可能性があります。候補キーは主属性から形成され、スーパーキーは候補キーのスーパーセットです。この問題を解決するために、ボイス・コッド正規形(BCNF)という別のタイプの機能的依存関係が利用できます。
テーブルがBCNFにあるためには、機能的依存関係の左側が候補キーまたはスーパーキーである必要があります。たとえば、機能的依存関係X→Yの場合、Xは候補キーまたはスーパーキーである必要があります。
次の属性を含むEmployeeテーブルを考えてみましょう。
- Employee ID(主キー)
- Employee Name
- Department
- Department Head
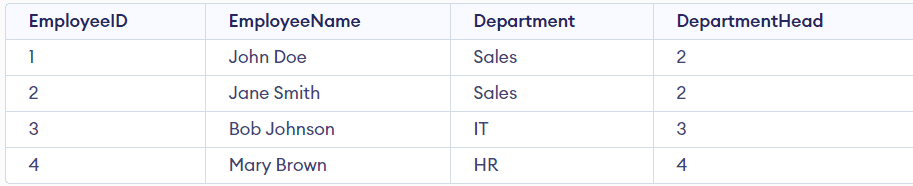
EmployeeIDは、各行を一意に識別する主キーです。Department属性は、特定の従業員の所属部署を表し、Department Head属性は、その特定の部署の部門長の従業員のEmployee IDを表します。
次に、このテーブルがBCNFにあるかどうかを確認します。条件は、関数従属の左辺がスーパーキーである必要があります。以下にそのテーブルの2つの関数従属性を示します。
関数従属性1:Employee ID → Employee Name、Department、Department Head
関数従属性2:Department → Department Head
FD1では、EmployeeIDは主キーであり、またスーパーキーでもあります。しかし、FD2では、Departmentはスーパーキーではありません。なぜなら、複数の従業員が同じ部署に所属することがあるからです。
したがって、このテーブルはBCNFの条件に違反しています。BCNFの特性を満たすためには、そのテーブルをEmployeesとDepartmentsの2つの別々のテーブルに分割する必要があります。EmployeesテーブルにはEmployeeID、EmployeeName、およびDepartmentが含まれ、DepartmentテーブルにはDepartmentとDepartment Headが含まれます。
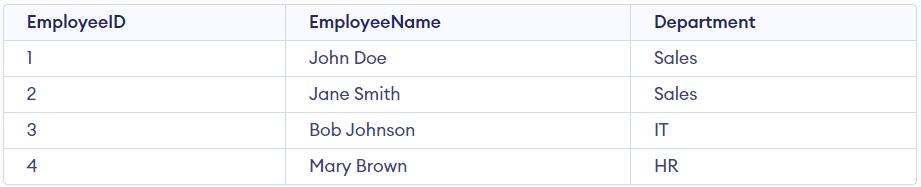

今は、両方のテーブルで、すべての関数従属性が主キーに依存していることがわかります。つまり、非自明な依存関係はありません。
有名な正規化技術をすべてカバーしましたが、これら以外にも4NFと5NFという2つの正規形があります。それについてもっと読みたい場合は、GeeksForGeeksのこの記事を参照してください。
まとめ
SQLで最も一般的に使用されるデータ型と、データベース管理システムでの重要な正規化手法について説明しました。データベースシステムを設計する際には、スケーラブルで、冗長性を最小限に抑え、データの整合性を確保することを目指しています。
適切なデータ型を選択することで、ストレージ、精度、メモリ消費の間に微妙なバランスを作ることができます。また、正規化プロセスによってデータの異常を排除し、スキーマをより整理されたものにすることができます。
今日は以上です。それでは、読み続け、学び続けてください。 Aryan Gargは、現在学士課程の最終年度にいるB.Tech.電気工学の学生です。彼の興味はWeb開発と機械学習の分野にあります。彼はこの興味を追求し、これらの方向でさらに活動することを熱望しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
