データストリームにおける行列近似
データストリームにおける行列近似' can be condensed to 'データストリームの行列近似'.
行がすべて揃っていない行列の近似
行列の近似は、データマイニングや機械学習の分野で重要な研究対象です。多くのデータ分析タスクでは、行列の低ランク近似を取得することに依存しています。例えば、次元削減、異常検知、データのノイズ除去、クラスタリング、および推薦システムなどです。本記事では、行列の近似の問題と、データ全体が手元にない場合にどのように計算するかについて説明します。
本記事の内容は、スタンフォード大学の-CS246コースの講義から一部引用しています。役に立つと思いますので、ぜひこちらでフルコンテンツをご覧ください。
データを行列として表現する
ウェブ上で生成されるほとんどのデータは、各行がデータポイントである行列として表現することができます。例えば、ルータではネットワークを介して送信されるすべてのパケットは、すべてのデータポイントの行列における1行として表現することができます。小売業では、すべての購入はすべての取引の行列における1行です。

同時に、ウェブ上で生成されるほとんどのデータはストリーミングの性質を持っています。つまり、データは外部のソースによって高速に生成され、我々はそれを制御することができません。Google検索エンジンでユーザーが行うすべての検索を毎秒ごとに考えてみてください。このデータをストリーミングデータと呼びます。まるで流れのように注がれるからです。
- ベクトルデータベースについて知っておくべきすべてと、それらを使用してLLMアプリを拡張する方法
- 「MITの研究者達が、シーン内の概念を理解するために機械学習モデルを支援するために、様々なシナリオを描いた画像の新しい注釈付き合成データセットを作成しました」
- ChatGPTはデータサイエンスの仕事を奪うのでしょうか?
典型的なストリーミングのウェブスケールデータの例は次のとおりです:
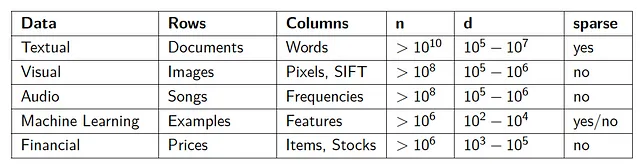
ストリーミングデータを、通常n行d次元空間の行列Aとして表現します。通常、nは数十億以上で増加します。
データストリーミングモデル
ストリーミングモデルでは、データが高速で1行ずつ到着し、アルゴリズムはアイテムを高速に処理しなければなりません。そうしないと、アイテムは永遠に失われます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「持続的な学習:データサイエンティストのオデッセイ」
- 「AIおよびARはデータ需要を推進しており、オープンソースハードウェアはその課題に応えています」
- 「LLMモニタリングと観測性 – 責任あるAIのための手法とアプローチの概要」
- 「スノーフレーク vs データブリックス:最高のクラウドデータプラットフォームを作るために競争する」
- PyCharm vs. Spyder 正しいPython IDEの選択
- マシンラーニングに取り組むため、プライベートエクイティはデータサイエンスの才能を採用しています
- 「医療機械学習におけるバイアスのある臨床データをどのように見るべきか?考古学的な視点への呼びかけ」
