データスクレイピングが注目されています:言語モデルは皆のコンテンツをトレーニングすることで飛び越えているのでしょうか?
データスクレイピングが注目されています言語モデルはコンテンツをトレーニングすることで飛躍しているのでしょうか?
スクレイピングが有効なモデルを取得する際、クリーンにソース化されたデータがますます重要になってきます
この記事のリサーチをまとめ、執筆を始めようとしていたところ、OpenAIがそれにぴったりの発表をしました。それは、「Browse with Bing」という機能を一時的に無効にするというものです。これを使ったことがない人に説明すると、これは有料のプラスユーザーが利用できる機能です。プラスには主に2つの利点があります:
- Browse with Bing — デフォルトでは、ChatGPTはリアルタイムのウェブサイトデータに接続しません(たとえば、2023年のアップカミングマーベル映画を尋ねても、2021年9月でトレーニングデータが停止しているため、回答は返されません)。Browse with Bingは、OpenAIがMicrosoft Bingとのパートナーシップによりアクセス権を得たウェブ上のサイトからのリアルタイム情報を活用することで、この制限を超えます。
- プラグイン — これらは、独立した企業によってChatGPTのUIを介してその機能を公開するためにChatGPTに組み込まれた統合です(たとえば、OpenTableはレストラン予約を検索することができ、Kayakはプラグインを使用する場合、ChatGPT内でフライトを検索することができます)。これらは実験的なものであり、「クール」な機能ではありますが、ユーザーはまだそれらを有用とは感じていません。
そのため、Browse with BingはChatGPTにとって特に重要です。なぜなら、最大の競合相手であるGoogle Bardは、Google Searchからリアルタイムデータを利用する能力を持っているからです。以下はChatGPTとBardのアップカミングマーベル映画に関する例の応答です:
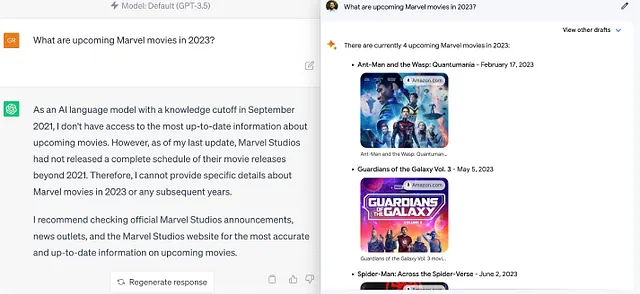
したがって、OpenAIがBrowse with Bingを無効にすることは非常に重要です(たとえ一時的にでも)。その理由は興味深いものです:
ChatGPT Browseベータ版では、我々が望まない形でコンテンツを表示することがあるということを学びました。たとえば、ユーザーが特定のURLの全文を要求した場合、それを誤って満たすことがあります。2023年7月3日現在、コンテンツの所有者に対する適切な対応を行うため、この問題を修正するためにBrowse with Bingベータ版機能を無効にしました。ベータ版をできるだけ早く復活させるために作業を行っており、ご理解いただけると幸いです!
興味深いのは、これによって明らかになるより大きな問題です。つまり、OpenAIやGoogle Bardのような企業が自分たちのモデルを訓練するために大量のデータを使用しているが、このデータの使用許可を持っているのか、またこのデータの使用に対してクリエイターやコンテンツプラットフォームにどのように補償しているのかが不明であるという問題です。
この記事では、以下の点を詳しく説明します:
- Large Language Models(LLM)とは何か、なぜデータが必要なのか
- 彼らはどこからデータを入手しているのか
- OpenAIやGoogleなどの企業は、データの入手方法についてどのように考えるべきか
- コンテンツプラットフォームは、これに対応するためにどのような戦略を採用しているのか
この記事の最後には、この急速に進化しているトピックについてより充実した情報を得られるでしょう。さあ、探求してみましょう。
Large Language Modelsとは何か、なぜデータが必要なのか
まず、機械学習モデルの動作を簡単に説明します。たとえば、予定されているフライトの到着時間がどれくらい遅れるかを予測したいとします。非常に基本的なバージョンでは、人間の推測(たとえば、天候が悪い場合や航空会社が悪い場合は、遅れる可能性が高い)があります。それをより信頼性のあるものにするために、フライトの到着時間に関する実際のデータを取得し、さまざまな要因とパターンマッチングすることができます(たとえば、到着時間が航空会社、目的地空港、気温、降水量などと関連しているかどうか)。
さらに一歩進めて、このデータを使用して数学の式を作成し、予測することができます。たとえば:遅延時間 = A * 航空会社の信頼性スコア + B * 空港の混雑度 + C * 降水量。A、B、Cをどのように計算するのか?過去の到着時間データを大量に使用して、それに数学的な処理を行うことによって計算します。
この数式は数学的には「回帰」と呼ばれ、最も一般的に使用される基本的な機械学習モデルの一つです。モデルは基本的には「特徴」(例:航空会社の信頼性スコア、空港の混雑度、降水量の量)と「重み」(例:A、B、Cなどの各変数が予測にどれだけの重みを加えるかを示す)からなる数式です。
同じ概念は他のより複雑なモデルにも適用できます。例えば、「ニューラルネットワーク」(ディープラーニングの文脈で聞いたことがあるかもしれません)や大規模言語モデル(LLMと略され、Google検索、ChatGPT、Google BardなどのテキストベースのAI製品の基礎モデルです)などです。
詳細にはあまり触れませんが、LLMを含むこれらのモデルはすべて、「特徴」と「重み」の組み合わせです。性能の良いモデルは、最適な特徴と重みの組み合わせを持っており、その組み合わせに到達する方法は、大量のデータを使用してトレーニングすることです。データが多ければ多いほど、モデルのパフォーマンスが向上します。したがって、大量のデータを持つことは重要であり、これらのモデルをトレーニングする企業はこのデータを入手する必要があります。
これらのデータはどこから入手しているのでしょうか?
大まかに言えば、データソースは以下のように大まかに分類されます:
- オープンソースのデータ:これらは通常、商業目的で利用できる高容量のデータソースであり、LLMのトレーニングに使用されます。大規模なオープンソースのデータの例には、Wikipedia、CommonCrawl(Webクロールデータのオープンリポジトリ)、Project Gutenberg(無料の電子書籍)、BookCorpus(未公開の著者による無料の書籍)などがあります。
- 独立したコンテンツウェブサイト:これには、ニュース発行物(ワシントンポスト、ガーディアンなど)、クリエイター固有のプラットフォーム(Kickstarter、Patreon、VoAGIなど)、ユーザー生成コンテンツプラットフォーム(Reddit、Twitterなど)など、さまざまなウェブサイトが含まれます。これらのウェブサイトは、特に商業目的で使用される場合には、そのコンテンツのスクレイピングに関してより制限的なポリシーを持っていることが一般的です。
理想的な世界では、LLM企業は使用した/スクレイピングしたすべてのデータソースを明示的にリスト化し、そのデータを所有する者のポリシーに準拠して行うべきです。しかし、それらのうちのいくつかは非透明であり、最も問題なのはOpenAI(ChatGPTの製造元)です。Googleはトレーニングに使用した1つのデータセットであるC-4を公開しました。ワシントンポストはこのデータについての興味深い分析をまとめました。以下はその分析に基づくトップ30のソースです:
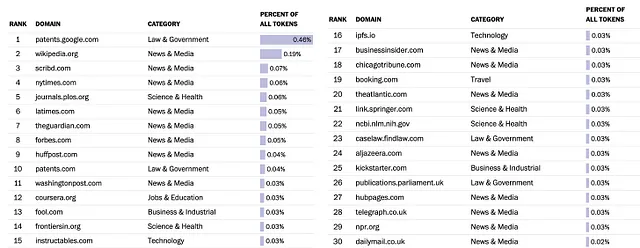
このデータのほとんどはスクレイピングによって取得され、コンテンツプラットフォームはこのデータが利用規約に違反してスクレイピングされたと主張しています。彼らは明らかに不満を抱いており、特にLLM企業がデータから得られるメリットの量を考えると、その点について不満を抱いています。
OpenAIやGoogleのような企業がデータの入手方法について気にすべき理由は何ですか?
よし、コンテンツプロバイダーが不満を言っている。では、LLM製品を提供する企業は、心の底から「公正」でありたいと思う以外に、これについて気にする必要があるのでしょうか?
データの入手は、2つの主要な理由でますます重要になっています。
法的な問題:LLMを開発する企業は、データが許可なく使用されたと考えるコンテンツクリエイターやパブリッシャーからの訴訟に巻き込まれることが増えています。法的な争いは高額な費用がかかり、関与する企業の評判を損なう可能性があります。例えば:
- Microsoft、GitHub、OpenAIは、AIを使用してオープンソースのコードを複製することで著作権法に違反したとして訴えられています。
- Getty ImagesがAIアートジェネレーターのStable Diffusionを訴える
- AIアートツールのStable DiffusionとMidjourneyが著作権訴訟の対象となる
[補足:Stable Diffusion、Midjourneyは画像生成AIであり、言語生成AIである「LLM」ではないため、モデルの構成とトレーニング方法は同じです]
企業顧客との進展:LLMまたはその派生物を使用する企業顧客は、トレーニングデータの正当性を保証される必要があります。彼らは、LLMを使用することで法的な問題に直面したくないため、LLMプロバイダーへの訴訟の責任を負うことができない場合があります。
これらの乱雑なデータソーシング制約で実際に効果的なモデルを構築することは本当に可能ですか?それは公平な質問です。これらの原則を適用するマスタークラスの一例として、最近のAdobe Fireflyの発表があります(これはクールな製品であり、オープンベータ版でプレイすることができます)-この製品はテキストから画像への変換など、幅広い機能を備えています。
Fireflyを素晴らしい例とする要素は次のとおりです:
- Adobeは、Adobe Stockのライセンスを既に持っている画像と、ライセンス制限のないオープンソースの画像のみを使用します。さらに、彼らはクリエイターが自分たちの才能を利用して収益化できるようにジェネレーティブAIを構築することを発表し、Fireflyがベータ版を抜けた後にAdobe Stockの貢献者向けの補償モデルを発表する予定です。
- Adobeは、Fireflyの出力に関して、顧客を保護します(テキストから画像への変換機能から開始)-「保護する」という用語を聞いたことがない場合、単純に言えば、Adobeは、彼らのモデルに入力されるデータをきれいにソース化したという自信があり、したがって、誰かがFireflyの出力を使用してAdobeの顧客を訴えた場合に生じる可能性のある法的問題をカバーする意思があると述べています。
クリーンなデータソーシングアプローチの一つの批判は、モデルが生成する出力の品質に影響を与えるということです。その反対の意見は、コンテンツプロバイダーが所有する高品質のデータがモデルトレーニングにおいてより良い品質の入力を提供できるということです(モデルトレーニングにおいてゴミを入れればゴミが出る)。以下の画像では、左側がAdobe Fireflyの出力で、右側がOpenAIのDall-Eの出力です。比較してみると、両者はかなり似ており、Fireflyの出力の方が現実的と言えるでしょう。つまり、きれいにソース化されたデータだけでも高品質の言語モデルを構築することができるということを示しています。
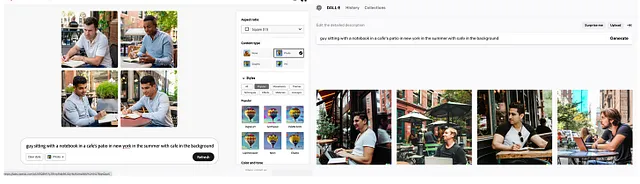
コンテンツプラットフォームはこれに対応するためにどのような戦略を採用していますか?
多くのコンテンツを持つ企業は、自社のデータを使用するAI企業に対して料金を請求する意向を明確に表明しています。重要なことは、ほとんどの企業が反AIの立場を取っていないこと(つまり、AIがビジネスを乗っ取るので、コンテンツへのアクセスを停止するとは言っていない)です。彼らは主に、このデータへのアクセスがどのように行われ、どのように補償を受けるかを定義する商業的な構造を求めています。
StackOverflowは、プログラマがヘルプが必要な時に利用する最も人気のあるフォーラムであり、50億のQ&Aコンテンツへのアクセスに対して大規模なAI開発者に料金を請求する予定です。StackOverflowのCEOであるPrashanth Chandrasekarは、いくつかの妥当な議論を示しました:
- 追加の収益は、StackOverflowがユーザーを引きつけ、高品質な情報を維持するために不可欠であり、また、プラットフォーム上で新しい知識を生成することによって将来のチャットボットの開発にも役立つでしょう
- StackOverflowは、一部の人々や企業に対してデータのライセンスを無料で提供し続ける予定であり、商業目的でLLMを開発している企業にのみ料金を請求することを検討しています
- 彼は、LLMの開発者がStack Overflowの利用規約に違反していると主張し、データを使用した後にデータの出典を明記する必要があるクリエイティブ・コモンズ・ライセンスの対象であると考えています(LLMはこれを行っていません)
Redditも同様の発表を行いました(同時にAPIの価格設定に関する論争的な変更も行いました)。RedditのCEOであるSteve Huffmanは、「Redditのデータは本当に価値がありますが、それを世界最大の企業のいくつかに無料で提供する必要はありません」とThe Timesに語りました。
Twitterは、今年初めにAPIへの無料アクセスを停止し、データの不正なスクレイピングを防ぐために1日にユーザーが表示できるツイートの数を制限するという最近の変更も発表しました。政策の実施と展開には改善の余地がありますが、商業目的での無料データアクセスを提供する意図は明確です。
LLMに対して統一的な立場と批判を示しているもう1つのグループは、ニュース機関です。米国の印刷およびデジタルメディアの発行者を代表するニュース/メディア連合(NMA)は、彼らがAI原則と呼んでいるものを公開しました。具体的な詳細はあまりありませんが、彼らが伝えたいメッセージは明確です:
GAI(生成AI)の開発者や展開者は、出版者のIP(知的財産)を許可なく使用してはならず、これらの開発者によるIPの使用に対して公平な補償を交渉する権利を出版者が持つべきです。
したがって、書面による形式的な合意が必要です。
公正使用の原則は、GAIシステムによる出版者のコンテンツ、アーカイブ、データベースの無断使用を正当化しません。明示的な許可なしにこれらのコンテンツの以前または現在の使用は、著作権法の違反です。
彼らの主張はこれを閉鎖するのではなく、商業契約を結んでこのデータを著作権法に準拠して使用することを求めています。また、彼らは現在市場に既に存在する補償フレームワーク(例:ライセンス)がイノベーションを遅らせることはないと主張しています。
結論
これは始まりに過ぎません。コンテンツ量が多いプラットフォームは、データに対して補償を求める可能性が高いです。この意図をまだ発表していない企業でも、既に他の形式のデータライセンスプログラム(例:LinkedIn、Foursquare、Reuters)を持っている可能性が高く、それをAI/LLM企業に適応させる可能性があります。
この展開はイノベーションの妨げに思えるかもしれませんが、コンテンツプラットフォームの長期的な持続可能性のためには必要な段階です。公正な補償を確保することで、コンテンツ作成者は質の高いコンテンツを継続して制作し、それがLLMの効果を高めることにつながります。
お読みいただきありがとうございます!もしこの記事がお気に召した場合は、毎週テックやビジネスの現在のトピックについて詳細な分析を掲載しているUnpackedニュースレターの購読を検討してください。Twitterで@viggybalaをフォローすることもできます。よろしくお願いします、Viggy。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
