データサイエンスのためのSQL:ジョインの理解と活用
データサイエンスのためのSQL:ジョインの理解と活用

データサイエンスは、膨大なデータから洞察を抽出し、情報に基づいた意思決定を行うために重要な役割を果たす学際的な分野です。データサイエンティストのツールボックスの中で、SQL(Structured Query Language)は、リレーショナルデータベースの管理や操作に特化したプログラミング言語です。
この記事では、SQLの中でも最もパワフルな機能の一つである「結合(joins)」に焦点を当てます。
- 「GPTとその先へ:LLMの技術的な基礎」
- Excalidraw 図を使ってデータサイエンスで自分自身をより明確に表現する方法
- データの壁を破る:ゼロショット、ワンショット、およびフューショットラーニングが機械学習を変革している
SQLにおける結合とは何ですか?
SQLの結合を使用すると、共通の列に基づいて複数のデータベーステーブルからデータを結合することができます。これにより、情報を統合し、関連するデータセット間に意味のあるつながりを作ることができます。
SQLにおける結合の種類
SQLにはいくつかの結合の種類があります:
- 内部結合
- 左外部結合
- 右外部結合
- 完全外部結合
- クロス結合
それぞれの種類を説明しましょう。
SQL内部結合
内部結合は、結合する2つのテーブルの中で一致する行のみを返します。共有キーまたは列に基づいて2つのテーブルの行を結合し、一致しない行は破棄します。
次のように視覚化します。 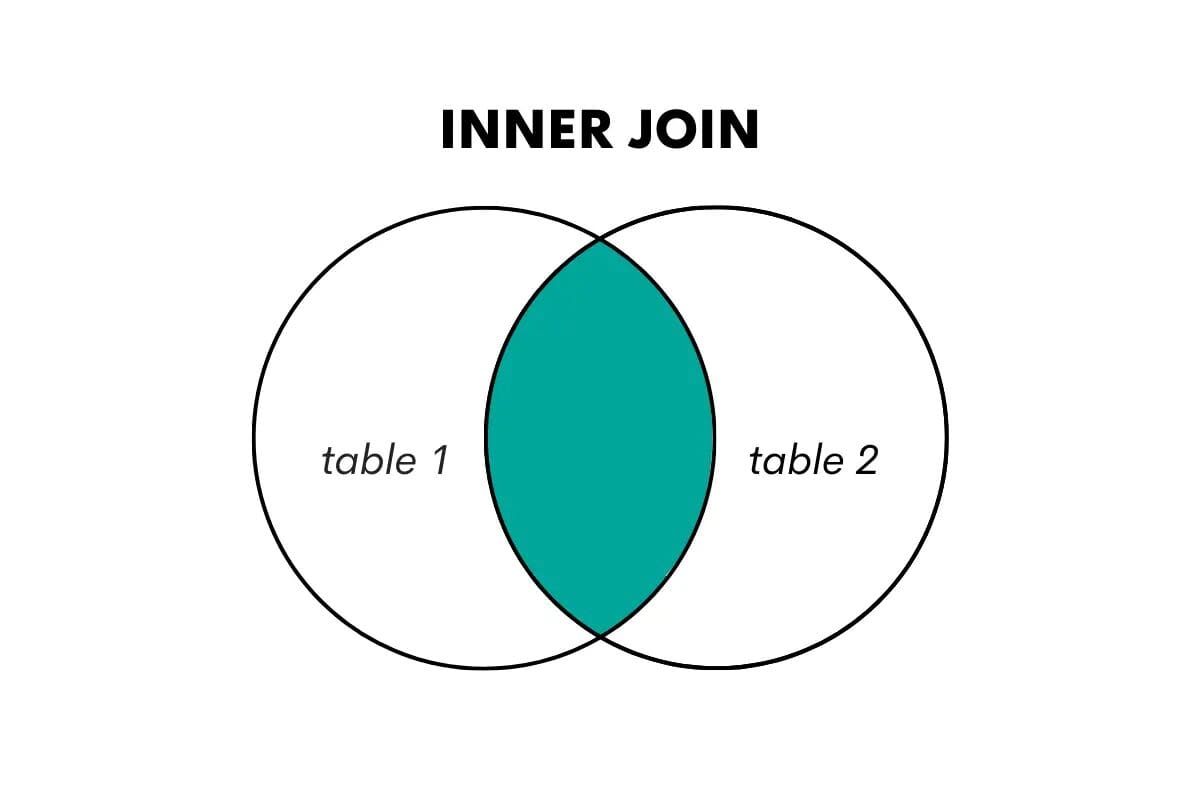
SQLでは、この結合タイプはJOINまたはINNER JOINキーワードを使用して実行されます。
SQL左外部結合
左外部結合は、左(または最初の)テーブルのすべての行と右(または2番目の)テーブルの一致する行を返します。一致しない場合、右テーブルの列にはNULL値が返されます。
次のように視覚化します。
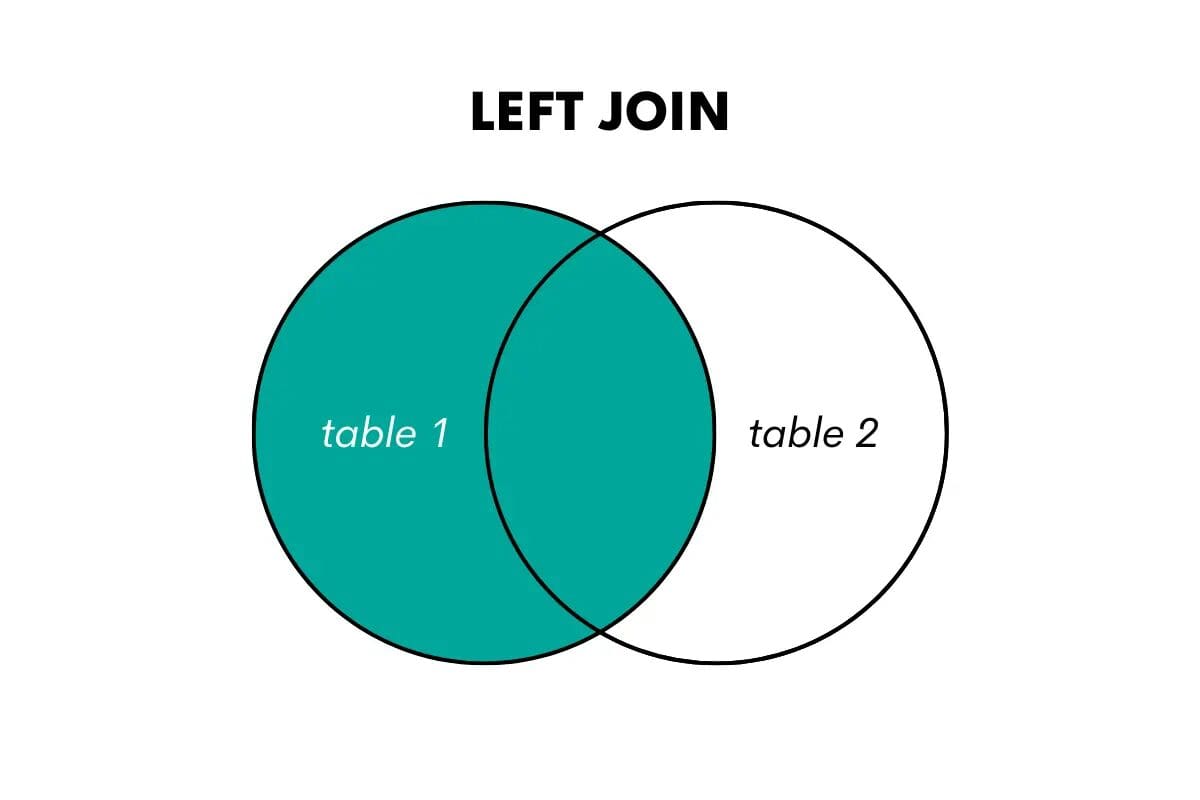
SQLでは、この結合を使用する場合、LEFT OUTER JOINまたはLEFT JOINキーワードを使用します。左結合と左外部結合の違いについて説明した記事があります。
SQL右外部結合
右結合は左結合の逆です。右テーブルからすべての行と左テーブルの一致する行を返します。一致しない場合、左テーブルの列にはNULL値が返されます。
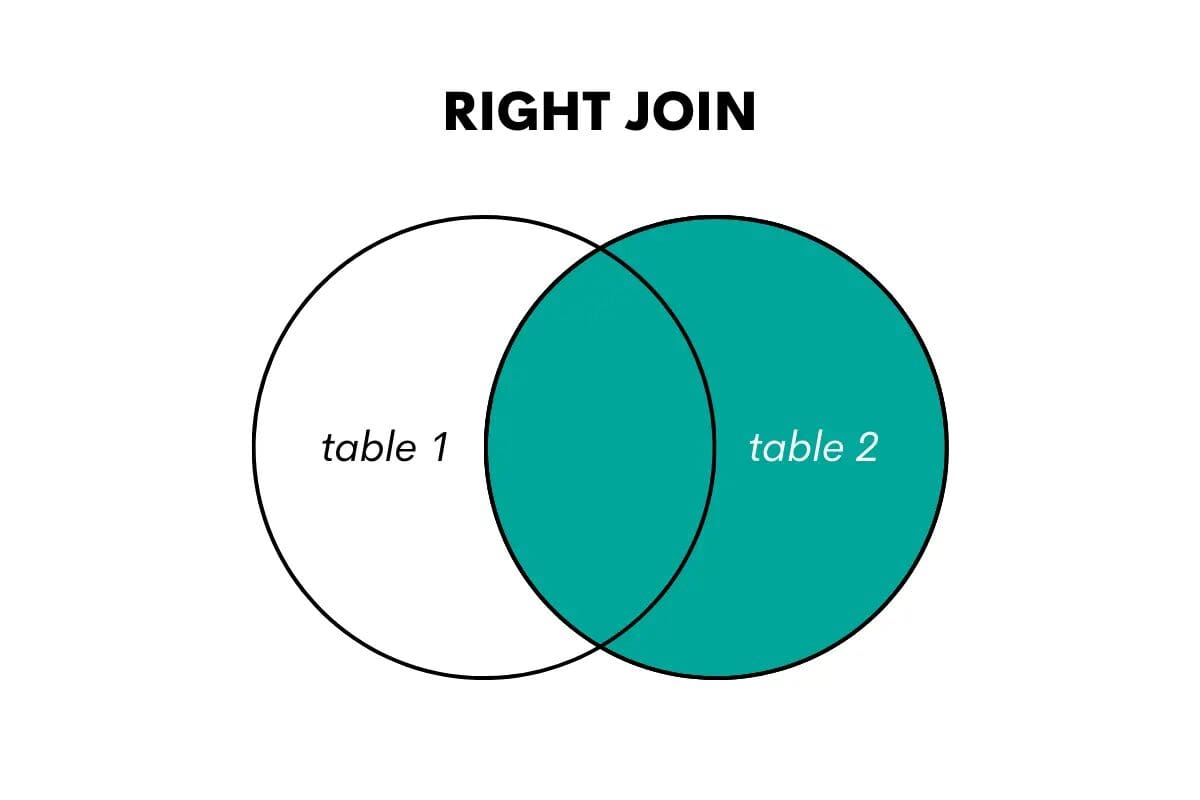
SQLでは、この結合タイプはRIGHT OUTER JOINまたはRIGHT JOINキーワードを使用して実行されます。
SQL完全外部結合
完全外部結合は、両方のテーブルからすべての行を返し、可能な場合に一致する行を結合し、一致しない行にはNULL値を埋めます。
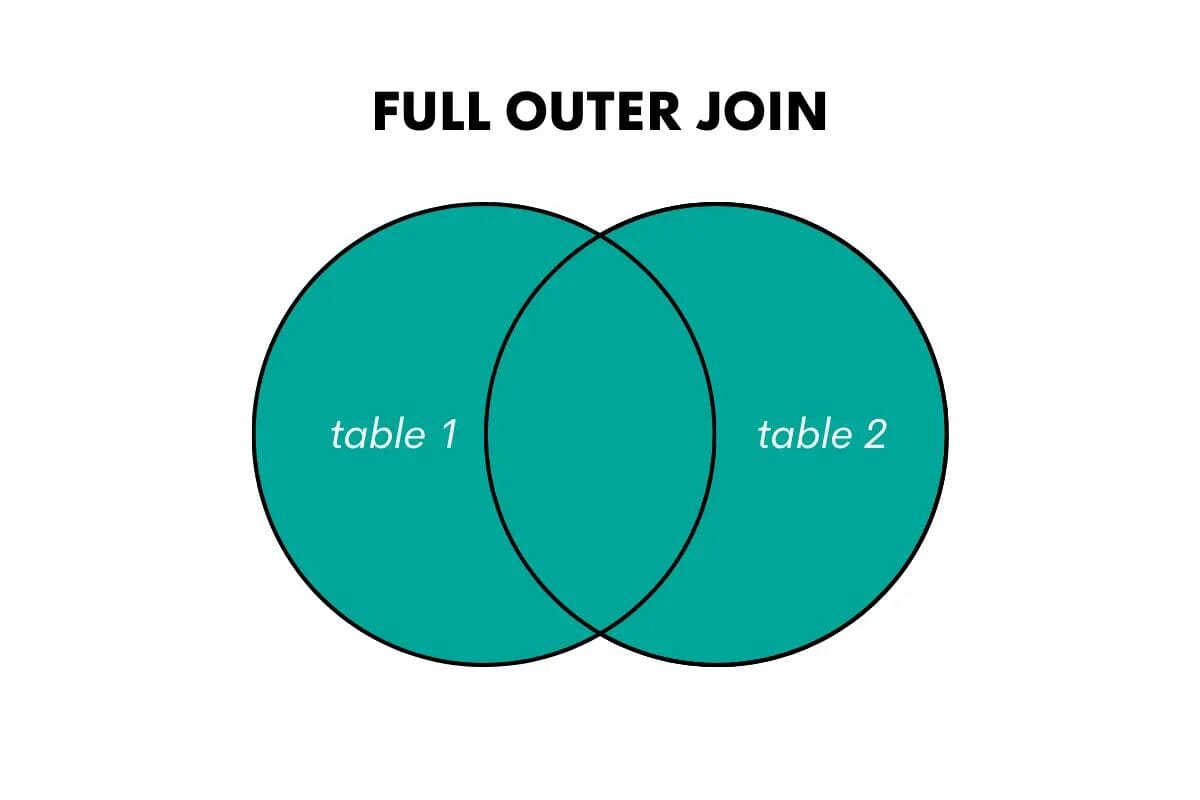
この結合のキーワードは、SQLではFULL OUTER JOINまたはFULL JOINです。
SQLクロス結合
このタイプの結合は、1つのテーブルのすべての行と2つ目のテーブルのすべての行を結合します。つまり、2つのテーブルの行の全ての可能な組み合わせを返します。
次の視覚化が理解を助けます。
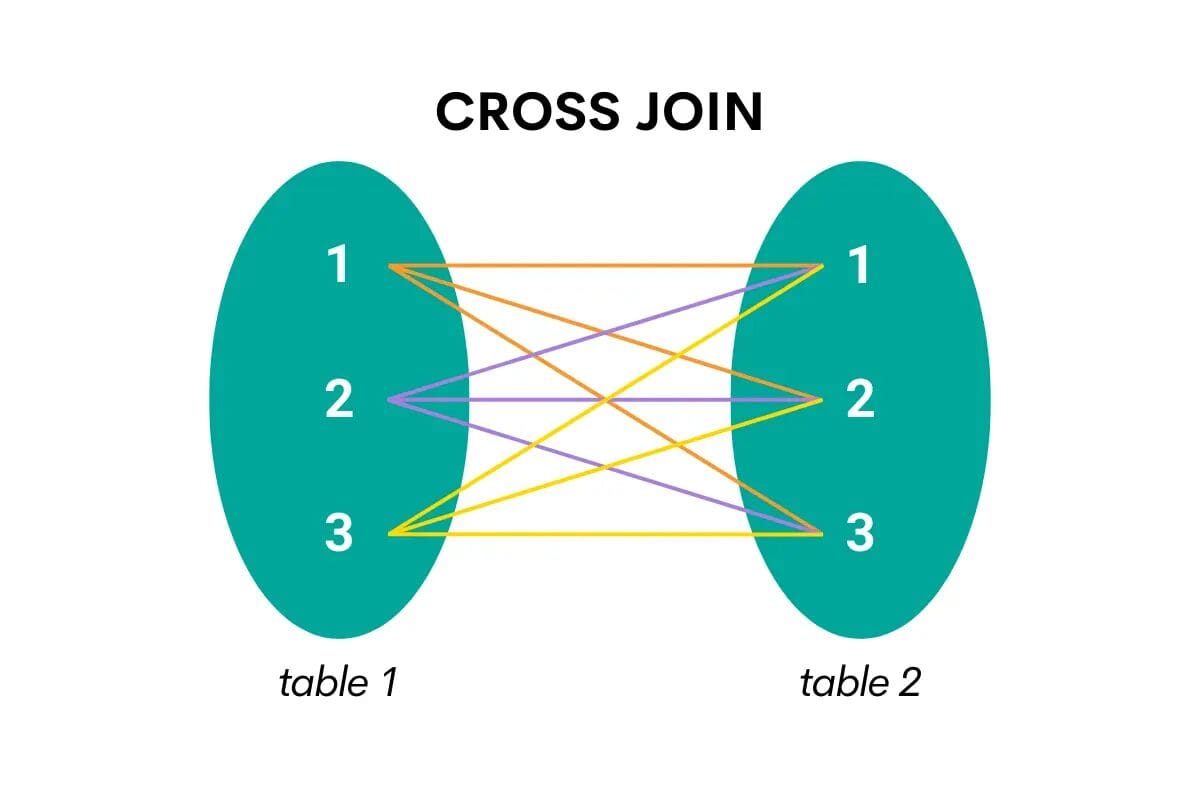
SQLでクロス結合を行う場合、キーワードはCROSS JOINです。
SQL結合構文の理解
SQLでJOINを実行するには、結合するテーブル、マッチングに使用する列、および実行する結合のタイプを指定する必要があります。 SQLでテーブルを結合するための基本的な構文は次のようになります:
SELECT 列名
FROM テーブル1
JOIN テーブル2
ON テーブル1.列名 = テーブル2.列名;
この例はJOINの使用方法を示しています。
FROM句で最初の(または左の)テーブルを参照します。次にJOINを続けて、2番目の(または右の)テーブルを参照します。
次に、結合条件がON句にあります。ここで、2つのテーブルを結合するために使用する列を指定します。通常、一方のテーブルのプライマリキーであり、2番目のテーブルの外部キーである共有列です。
注:プライマリキーはテーブル内の各レコードの一意の識別子です。外部キーは2つのテーブルの関連を確立します。すなわち、最初のテーブルを参照する2番目のテーブルの列です。 例でそれがどういう意味かを示します。
LEFT JOIN、RIGHT JOIN、またはFULL JOINを使用したい場合は、JOINの代わりにこれらのキーワードを使用するだけで、コードの他の部分はまったく同じです!
CROSS JOINでは少し異なります。その性質上、両方のテーブルの行の組み合わせをすべて結合します。そのため、ON句は必要ありませんし、構文は次のようになります。
SELECT 列名
FROM テーブル1
CROSS JOIN テーブル2;
つまり、FROMで1つのテーブルを参照し、CROSS JOINで2番目のテーブルを参照します。
または、FROMで両方のテーブルを参照し、カンマで区切って別々に参照することもできます。これはCROSS JOINの省略形です。
SELECT 列名
FROM テーブル1, テーブル2;
Self Join: SQLの特別な結合の一種
テーブルを結合するもう1つの特別な方法があります-テーブルを自己結合することです。これは自己結合とも呼ばれます。
これは厳密には異なる結合の種類ではありません。最初に説明した結合のいずれのタイプでも自己結合に使用できます。
自己結合の構文は以前に示したものと似ています。主な違いは、FROMとJOINで同じテーブルが参照されることです。
SELECT 列名
FROM テーブル1 t1
JOIN テーブル1 t2
ON t1.列名 = t2.列名;
また、テーブルには2つのエイリアスを指定する必要があります。行っていることは、テーブルを自己結合して2つのテーブルとして扱うことです。
ここでそれについて触れたかっただけで、詳細には触れません。自己結合に興味がある場合は、このSQLにおける自己結合のイラスト付きガイドを参照してください。
SQL結合の例
これまでに説明したすべての内容が実際にどのように機能するかを示します。SQL JOINのインタビュー問題を使用して、SQLの各異なる結合のタイプを紹介します。
1. JOINの例
このMicrosoftの質問では、各プロジェクトをリストし、プロジェクトごとに従業員の予算を計算するように求められます。
高額プロジェクト
「プロジェクトと各プロジェクトにマッピングされた従業員のリストが与えられた場合、各従業員に割り当てられたプロジェクト予算の金額ごとに計算してください。出力にはプロジェクトのタイトルと最も高い予算の従業員ごとのプロジェクト予算を整数に丸めたものが含まれるようにします。」
データ
この質問では2つのテーブルが与えられます。
ms_projects
| id: | int |
| title: | varchar |
| budget: | int |
ms_emp_projects
| emp_id: | int |
| project_id: | int |
今、テーブルms_projectsのカラムidは、テーブルの主キーです。同じカラムは、テーブルms_emp_projectsでも見つけることができますが、名前が異なります: project_idです。これは、テーブルの外部キーであり、最初のテーブルを参照しています。
これらの2つのカラムを使用して、テーブルを結合する方法を示します。
コード
SELECT title AS project,
ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b
ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
JOINを使用して2つのテーブルを結合しました。テーブルms_projectsはFROMで参照され、JOINの後にはms_emp_projectsが参照されます。両方のテーブルには別名が付けられており、後でテーブルの長い名前を使用する必要がありません。
これで、テーブルを結合するために使用するカラムを指定する必要があります。1つのテーブルの主キーともう1つのテーブルの外部キーがどのカラムかすでに説明しましたので、ここでそれらを使用します。
これらの2つのカラムを等しくする理由は、プロジェクトIDが同じデータをすべて取得したいからです。また、各プロジェクトの予算を従業員数で割ります。結果を小数値に変換し、小数点以下を0に丸めるようにもしています。
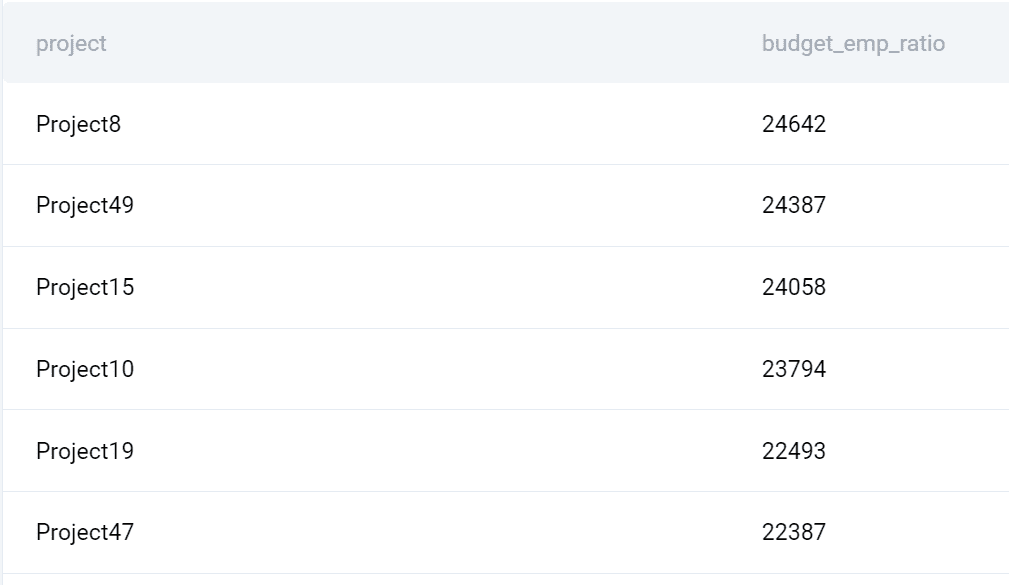
出力
クエリの結果は以下の通りです。
2. LEFT JOINの例
Airbnbのインタビューの質問でこの結合を練習しましょう。各都市ごとの注文数、顧客数、注文の総費用を見つけるように求められています。
顧客の注文と詳細
「各都市ごとの注文数、顧客数、注文の総費用を見つけてください。少なくとも5つの注文を行った都市のみを含め、各都市のすべての顧客をカウントすること。各計算と対応する都市名を出力してください。」
データ
テーブルcustomersとordersが与えられます。
customers
| id: | int |
| first_name: | varchar |
| last_name: | varchar |
| city: | varchar |
| address: | varchar |
| phone_number: | varchar |
orders
| id: | int |
| cust_id: | int |
| order_date: | datetime |
| order_details: | varchar |
| total_order_cost: | int |
共有の列は、customersテーブルのidと、ordersテーブルのcust_idです。これらの列を使用してテーブルを結合します。
コード
ここでは、LEFT JOINを使用してこの問題を解決する方法を示します。
SELECT c.city,
COUNT(DISTINCT o.id) AS orders_per_city,
COUNT(DISTINCT c.id) AS customers_per_city,
SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
FROM句でcustomersテーブルを参照し(これが左側のテーブルです)、顧客ID列を使用してordersとLEFT JOINします。
これで都市を選択し、COUNT()を使用して都市ごとの注文数と顧客数を取得し、SUM()を使用して都市ごとの注文総額を計算できます。
これらの計算を都市ごとに取得するために、出力を都市でグループ化します。
問題には「少なくとも5つの注文を行った都市のみを含めてください…」という追加の要求があります。それを達成するためにHAVINGを使用して、5つ以上の注文がある都市のみを表示します。
質問は、なぜ LEFT JOIN を使用し、JOINではないのか? 答えは質問にあります。「…注文を行っていない場合でも、各都市で顧客を数えます。」すべての顧客が注文を行っていない可能性があります。つまり、テーブルcustomersからすべての顧客を表示したいのですが、それはLEFT JOINの定義にぴったりと合っています。
JOINを使用した場合、結果は間違っていました。注文を行っていない顧客が抜けてしまったことになります。
注意:SQLの結合の複雑さは、構文ではなく意味で反映されます!ご覧のように、各結合は同じ方法で書かれていますが、キーワードのみが異なります。しかし、各結合は異なる方法で機能し、したがってデータに応じて異なる結果を出力することができます。そのため、各結合が何を行うかを完全に理解し、正確に必要なものを返す結合を選択することが重要です!
出力
では、出力を見てみましょう。

3. RIGHT JOINの例
RIGHT JOINはLEFT JOINの鏡像です。そのため、前の問題をRIGHT JOINを使用して簡単に解決することもできます。やり方を見てみましょう。
データ
テーブルは同じままで、異なる結合のタイプを使用します。
コード
SELECT c.city,
COUNT(DISTINCT o.id) AS orders_per_city,
COUNT(DISTINCT c.id) AS customers_per_city,
SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
変更された部分は次のとおりです。RIGHT JOINを使用しているため、テーブルの順序を切り替えました。今度はテーブルordersが左側になり、テーブルcustomersが右側になります。結合条件は同じままです。テーブルの順序を反映するために列の順序を切り替えたが、必要ではありません。
テーブルの順序を切り替えてRIGHT JOINを使用することで、再びすべての顧客を出力します。注文を行っていない場合でも。
クエリの残りの部分は前の例と同じです。出力も同じです。
注意:実際のところ、 RIGHT JOINは比較的めったに使用されません。 SQLユーザーにとっては、LEFT JOINの方が自然なので、より頻繁に使用されます。RIGHT JOINで行えることはすべてLEFT JOINでも行えます。そのため、RIGHT JOINが優先される特定の状況はありません。
出力
4. FULL JOINの例
SalesforceとTeslaの質問では、企業が2020年に開始した製品の数と前年に開始した製品の数の差を数えるように求めています。
新製品
「企業ごとの年ごとの製品開始のテーブルが与えられます。2020年に企業が開始した製品の数と前年に企業が開始した製品の数の差を数えるクエリを書いてください。企業名と2020年と前年の差分のネット製品数を出力してください。」
データ
この質問では、次の列が含まれる1つのテーブルが提供されます。
car_launches
| year: | int |
| company_name: | varchar |
| product_name: | varchar |
1つのテーブルしかない場合、どのようにテーブルを結合しますか?うーん、それも見てみましょう!
コード
このクエリは少し複雑なので、段階的に明らかにします。
SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
最初のSELECT文では、2020年の企業名と製品名が検索されます。このクエリは後でサブクエリに変換されます。
質問では、2020年と2019年の差を求めるように求められています。したがって、同じクエリを2019年用に書いてみましょう。
SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
これらのクエリをサブクエリに変換し、FULL OUTER JOINを使用して結合します。
SELECT *
FROM
(SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name;
サブクエリはテーブルとして扱われ、したがって結合することができます。最初のサブクエリにエイリアスを付け、FROM句に配置しました。そして、FULL OUTER JOINを使用して2番目のサブクエリと企業名の列で結合しました。
このタイプのSQL結合を使用することで、2020年のすべての企業と製品が2019年のすべての企業と製品とマージされます。
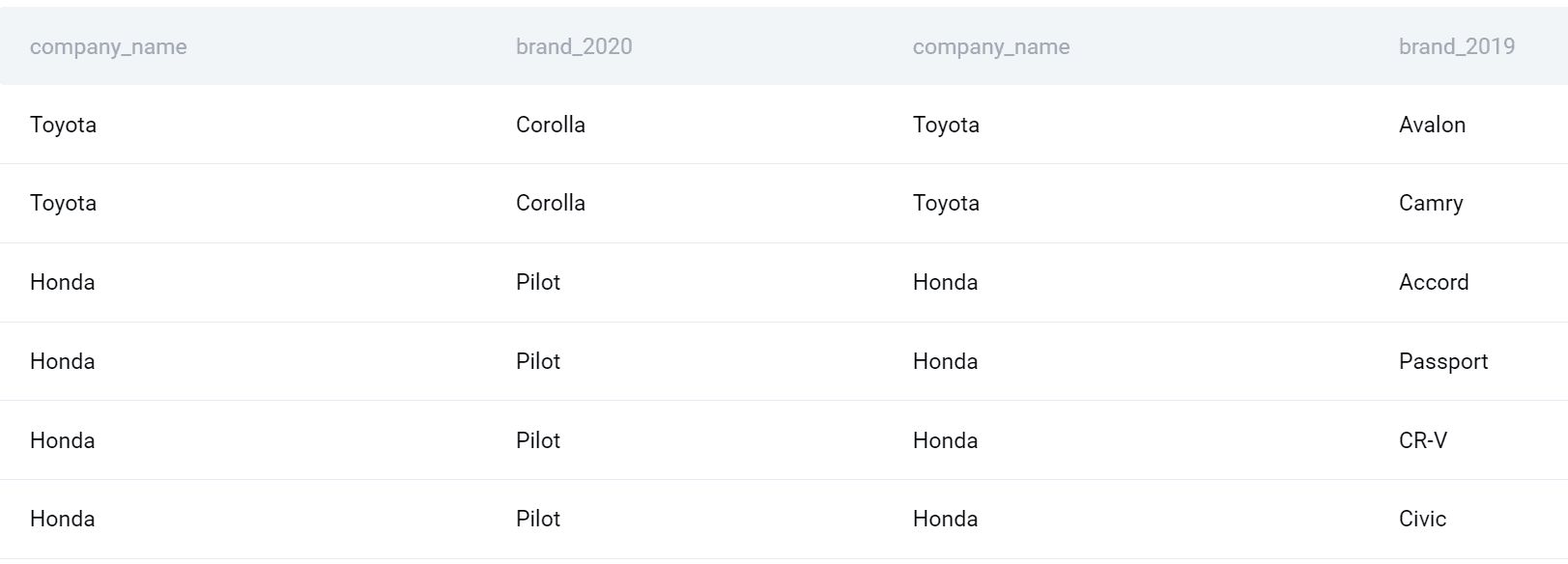
これでクエリを完成させることができます。企業名を選択しましょう。また、COUNT()関数を使用して各年における製品の数を求め、差を求めます。最後に、出力を企業名でグループ化し、企業名でアルファベット順にソートします。
以下が完全なクエリです。
SELECT a.company_name,
(COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM
(SELECT company_name,
product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020) a
FULL OUTER JOIN
(SELECT company_name,
product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019) b
ON a.company_name = b.company_name
GROUP BY a.company_name
ORDER BY company_name;
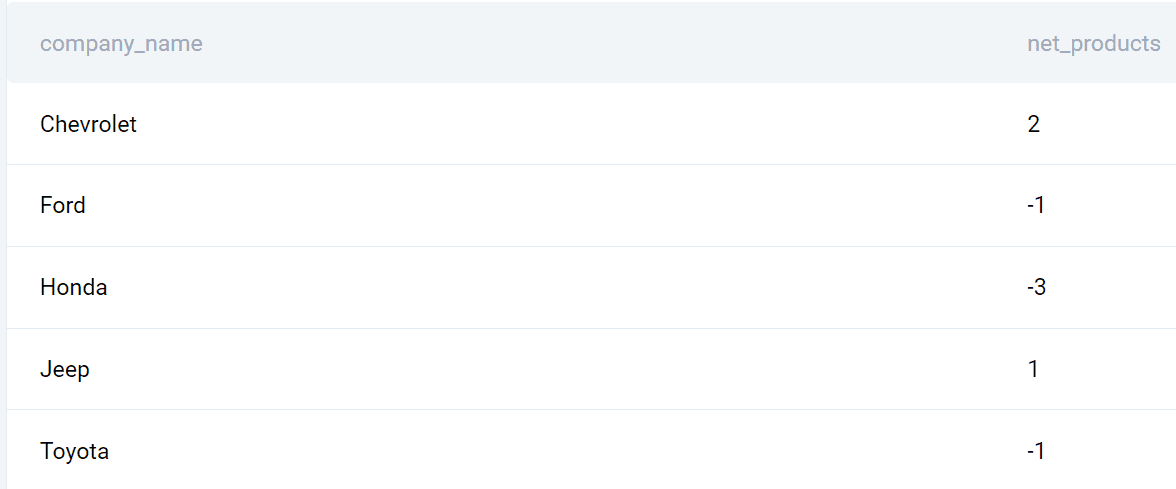
出力
以下は2020年と2019年の企業と製品のリリースの違いのリストです。
5. CROSS JOIN の例
デロイトのこの質問は、CROSS JOIN の動作を示すのに最適です。
2つの数値の最大値
「数値の1列が与えられた場合、数値のペア(x,y)と(y,x)を2つの異なる順列として扱うと仮定すると、それぞれの順列において2つの数値の最大値を見つけてください。
3つの列を出力してください:最初の数値、2番目の数値、および2つの数値の最大値」
この質問では、数値のペア(x,y)と(y,x)を2つの異なる順列として扱う必要があります。その後、各順列ごとに数値の最大値を見つける必要があります。
データ
この質問では、1つの列を持つ1つのテーブルが与えられます。
deloitte_numbers
| number: | int |
コード
このコードは、CROSS JOIN の例であり、自己結合の例でもあります。
SELECT dn1.number AS number1,
dn2.number AS number2,
CASE
WHEN dn1.number > dn2.number THEN dn1.number
ELSE dn2.number
END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
FROM 句でテーブルを参照し、別名を与えます。その後、CROSS JOIN の後にテーブルを参照し、テーブルに別の別名を与えて自己結合します。
これにより、1つのテーブルを2つとして使用することができます。各テーブルから列 number を選択します。その後、CASE 文を使用して、2つの数値の最大値を示す条件を設定します。
なぜここで CROSS JOIN を使用するのでしょうか?覚えておいてください、それはすべてのテーブルのすべての行の組み合わせを表示するタイプの SQL の JOIN です。それがまさにこの質問が求めていることです!
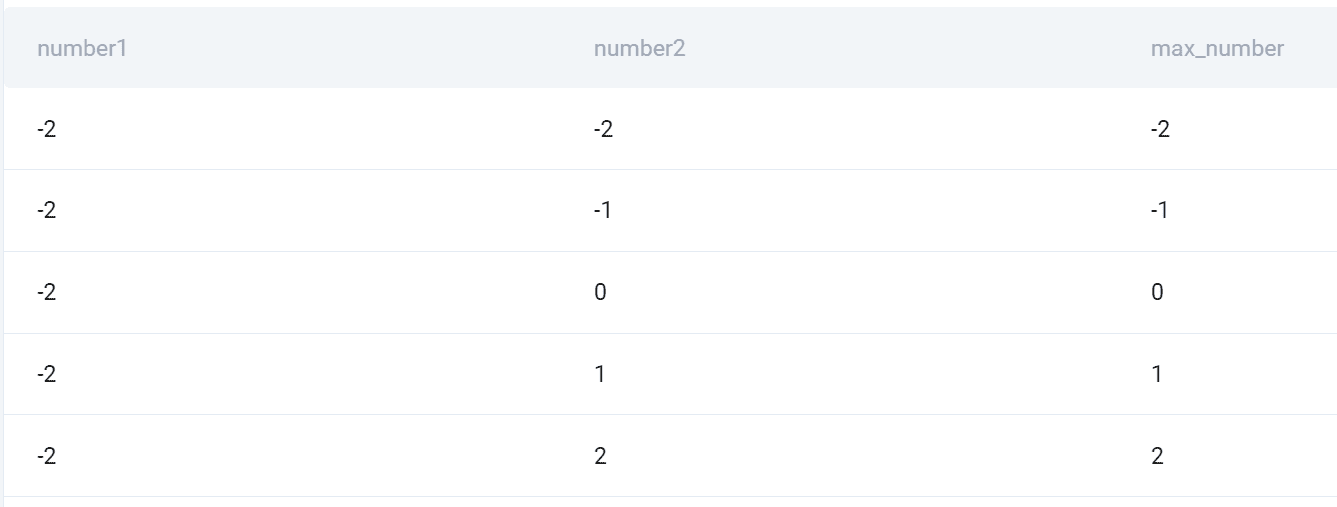
出力
以下はすべての組み合わせと2つの数値のうちの大きい方のスナップショットです。
データサイエンスでの SQL の JOIN の活用
SQL の JOIN を使用する方法を知ったところで、その知識をデータサイエンスにどのように活用するかが問題です。
SQL の JOIN は、データの探索、データのクリーニング、および特徴量エンジニアリングなどのデータサイエンスのタスクで重要な役割を果たします。
以下は SQL の JOIN を活用するいくつかの例です:
- データの結合: テーブルの結合により、異なるデータソースを統合し、複数のデータセット間の関係や相関関係を分析することができます。例えば、顧客テーブルとトランザクションテーブルを結合することで、顧客の行動や購買パターンに関する洞察を得ることができます。
- データの検証: JOIN を使用することで、データの品質と整合性を検証することができます。異なるテーブルのデータを比較することで、矛盾、欠損値、または外れ値を特定することができます。これにより、データのクリーニングが容易になり、分析に使用するデータが正確かつ信頼性があることを保証できます。
- 特徴量エンジニアリング: JOIN は、機械学習モデルの新しい特徴量の作成に重要な役割を果たすことができます。関連するテーブルをマージすることで、意味のある情報を抽出し、データ内の重要な関係性を捉える特徴量を生成することができます。これにより、モデルの予測力を向上させることができます。
- 集計と分析: JOIN を使用することで、複数のテーブルを対象に複雑な集計と分析を行うことができます。さまざまなソースからデータを組み合わせることで、データの包括的なビューを得ることができ、有益な洞察を導き出すことができます。例えば、販売テーブルと製品テーブルを結合することで、製品カテゴリや地域ごとの販売実績を分析することができます。
SQLジョインのベストプラクティス
すでに述べたように、ジョインの複雑さは構文には現れません。構文は比較的簡単です。
ジョインのベストプラクティスも同様で、コーディング自体ではなく、ジョインの動作やパフォーマンスに関係しています。
SQLのジョインを最大限に活用するためには、以下のベストプラクティスを考慮してください。
- データを理解する:データの構造や関係を理解しましょう。これにより、適切なジョインの種類を選択し、マッチングに適した列を選択することができます。
- インデックスを使用する:テーブルが大きい場合や頻繁にジョインする場合は、ジョインに使用する列にインデックスを追加することを検討してください。インデックスはクエリのパフォーマンスを大幅に向上させることができます。
- パフォーマンスに注意する:大きなテーブルや複数のテーブルをジョインすることは、計算コストがかかる場合があります。データをフィルタリングしたり、適切なジョインの種類を使用したり、一時テーブルやサブクエリの使用を検討することで、クエリを最適化しましょう。
- テストと検証:常にジョインの結果を検証して正確性を確認しましょう。サニティチェックを実施し、ジョインされたデータが期待通りのものであり、ビジネスロジックと一致していることを確認します。
結論
SQLジョインは、複数のソースからデータを結合して分析するための基本的な概念です。異なるタイプのSQLジョインの理解、構文のマスタリング、効果的な活用により、データサイエンティストは価値ある洞察を得たり、データの品質を検証したり、データに基づいた意思決定を推進することができます。
私は5つの例でどのように行うかを示しました。今度は、SQLとジョインの力をデータサイエンスのプロジェクトに活かし、より良い結果を得るために活用する番です。Nate Rosidiはデータサイエンティストであり、製品戦略に従事しています。また、実務経験を活かし、アナリティクスを教える非常勤講師でもあります。彼はStrataScratchというプラットフォームの創設者でもあり、トップ企業の実際のインタビューの質問を使ってデータサイエンティストがインタビューに備えるお手伝いをしています。Twitter: StrataScratchまたはLinkedInで彼とつながってください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「共通の悪いデータの10つのケースとその解決策を知る必要があります」
- 「ToolLLMをご紹介します:大規模言語モデルのAPI利用を向上させるためのデータ構築とモデルトレーニングの一般的なツールユースフレームワーク」
- 「データクリーニングと前処理の技術をマスターするための7つのステップ」
- 「LP-MusicCapsに会ってください:データの乏しさ問題に対処するための大規模言語モデルを使用したタグから疑似キャプション生成アプローチによる自動音楽キャプション作成」
- 「ゼロから効果的なデータ品質戦略を構築するためのステップバイステップガイド」
- 「貪欲であることはどれほど悪いのか?」
- 「マスタリングモンテカルロ:より良い機械学習モデルをシミュレーションする方法」
