デプロイ可能な機械学習パイプラインの構築
'デプロイ可能な機械学習パイプラインの構築' can be translated to 'Building deployable ML pipelines.'
Kedroを活用して本番用の機械学習パイプラインを構築する

背景 — ノートブックは「デプロイ可能」ではありません
多くのデータサイエンティストは、ノートブックスタイルのユーザーインターフェースを通じてコーディングに初めて触れます。ノートブックは探索には欠かせないものであり、ワークフローの重要な側面です。ただし、ノートブックは本番用に設計されていません。これは、多くのクライアントの中で私が観察した重要な問題であり、彼らのノートブックを本番環境で使用する方法について問い合わせる人々もいます。ノートブックを本番環境にする代わりに、モジュール化、保守性、再現性のあるコードを作成することが、本番準備の最適な方法です。
この記事では、不正なクレジットカードのトランザクションを分類するためのモデルのトレーニングに対してモジュール化されたMLパイプラインの例を紹介します。この記事の結論までに、以下のことを期待しています:
- モジュール化されたMLパイプラインの価値と理解を得ること。
- 自分自身でそれを構築するためのインスピレーションを感じること。
最大の効果で機械学習モデルを展開するための利点を得るためには、モジュラーコードを記述することが重要なステップです。
まず、モジュラーコードの簡単な定義から始めましょう。モジュラーコードとは、プログラムを独立した交換可能なモジュールに分割することを重視したソフトウェア設計パラダイムです。機械学習パイプラインでもこの状態を目指すことを目指すべきです。
クイックディツア — プロジェクト、データ、およびアプローチ
この機械学習プロジェクトはKaggleから取得されました。データセットは284,807件の匿名化されたクレジットカードのトランザクションで、そのうち492件が不正です。課題は、不正なトランザクションを検出するための分類器を構築することです。
このプロジェクトのデータは、Open Data Commonsの下で商業利用を含む任意の目的でライセンスされています。
私はLudwigというオープンソースのフレームワークを利用した深層学習アプローチを使用しました。Ludwigの詳細についてはここでは触れませんが、以前にフレームワークについての記事を書いています。
Ludwigの深層ニューラルネットワークは.yamlファイルで構成されています。興味がある方は、モデルレジストリのGitHubで見つけることができます。
Kedroを使用したモジュラーパイプラインの構築
モジュラーな機械学習パイプラインの構築は、オープンソースのツールによって容易になりましたが、その中でも私のお気に入りはKedroです。これは、産業界で成功裏に使用されているだけでなく、私のソフトウェアエンジニアリングスキルの開発にも役立ちました。
Kedroは、再現性、保守性、モジュール化されたデータサイエンスコードを作成するためのオープンソースのフレームワーク(Apache 2.0のライセンス)です。私は、銀行のAI戦略を開発していた際にこのツールを利用して本番用のコードを構築するためのツールとして検討しました。
免責事項: 私はKedroまたはMcKinsey’s QuantumBlack、このオープンソースツールの作成者とは一切関係ありません。
モデルトレーニングパイプライン
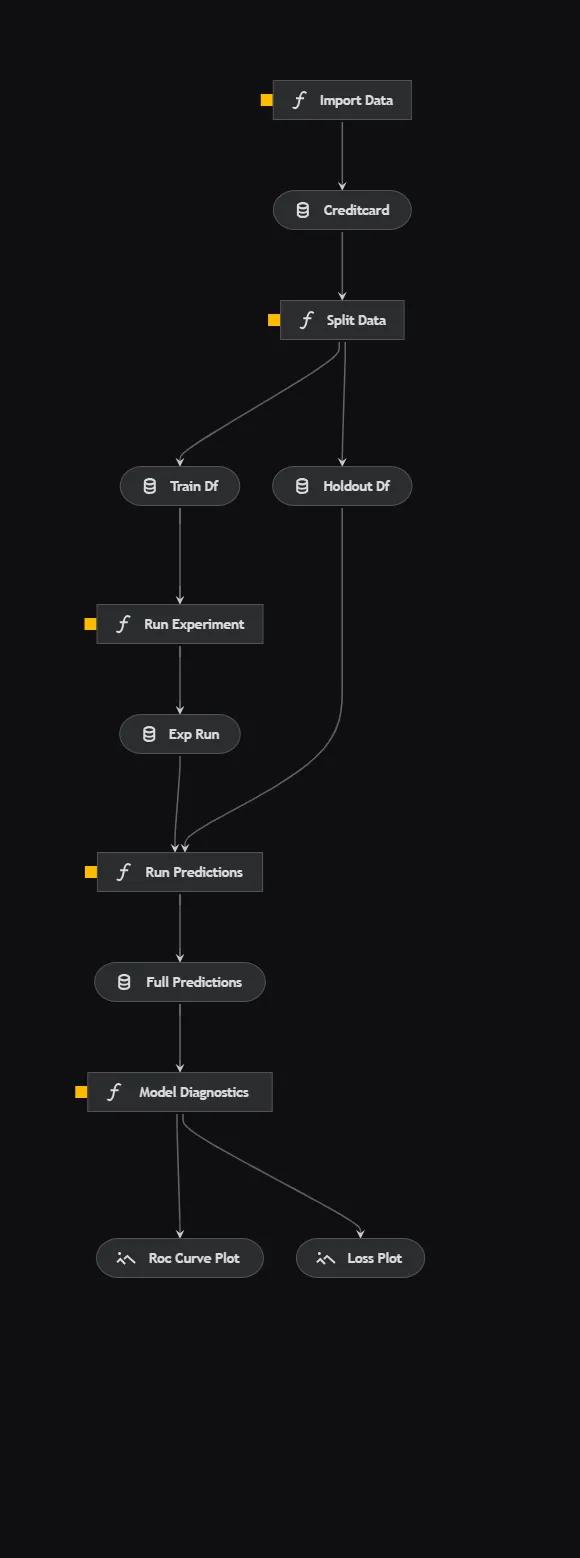
Kedroを使用すると、パイプラインを視覚化することができます。これは非常に素晴らしい機能であり、コードに明確さをもたらすのに役立ちます。パイプラインは機械学習では標準的なものなので、各要素については簡単に触れます。
- データのインポート: 外部ソースからクレジットカードのトランザクションデータをインポートします。
- データの分割: データをランダムに分割してトレーニングセットとホールドアウトセットに分けます。
- 実験の実行: Ludwigフレームワークを使用してトレーニングデータセット上でディープニューラルネットワークをトレーニングします。 Ludwigの実験APIは、各実験の実行ごとにモデルのアーティファクトを便利に保存します。
- 予測の実行: 前のステップでトレーニングされたモデルを使用して、ホールドアウトデータセット上で予測を実行します。
- モデルの診断: 2つの診断チャートを生成します。まず、各エポックでのクロスエントロピー損失をトラッキングします。次に、ホールドアウトデータセットでのモデルのパフォーマンスを測定するROC曲線です。
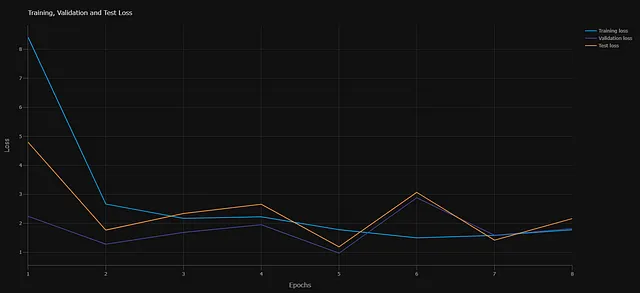
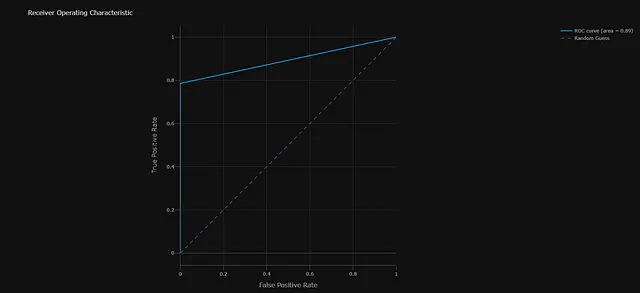
パイプラインの主要なコンポーネント
高レベルな概要を確立したところで、このパイプラインの主要なコンポーネントについて詳しく見ていきましょう。
プロジェクトの構造
C:.├───conf│ ├───base│ │ └───parameters│ └───local├───data│ ├───01_raw│ ├───02_intermediate│ ├───03_primary│ ├───04_feature│ ├───05_model_input│ ├───06_models│ │ ├───experiment_run│ │ │ └───model│ │ │ ├───logs│ │ │ │ ├───test│ │ │ │ ├───training│ │ │ │ └───validation│ │ │ └───training_checkpoints│ │ └───experiment_run_0│ │ └───model│ │ ├───logs│ │ │ ├───test│ │ │ ├───training│ │ │ └───validation│ │ └───training_checkpoints│ ├───07_model_output│ └───08_reporting├───docs│ └───source│ └───src ├───fraud_detection_model │ ├───pipelines │ ├───train_model └───tests └───pipelinesKedroは、プロジェクトを初期化すると確立されるテンプレート化されたディレクトリ構造を提供します。この基本構造に基づいて、ディレクトリ構造にさらにパイプラインをプログラムで追加することができます。この標準化された構造により、すべての機械学習プロジェクトが同一で文書化しやすくなるため、メンテナンスが容易になります。
データ管理
データは機械学習において重要な役割を果たします。機械学習モデルを商業環境で使用する際には、データを追跡する能力がより重要になります。監査が必要になる場合や、他の人のマシンでパイプラインを本番化または再現する必要がある場合があります。
Kedroでは、データ管理のベストプラクティスを強制するための2つの方法が提供されています。1つ目はディレクトリ構造で、データの変換中に生成される中間テーブルとモデルの成果物に対して異なる場所を提供します。2つ目の方法はデータカタログです。Kedroのワークフローの一環として、データセットを.yaml設定ファイルに登録する必要があります。これにより、パイプライン内でこれらのデータセットを活用することができます。このアプローチは最初は異常に思えるかもしれませんが、データの追跡が容易になります。
オーケストレーション – ノードとパイプライン
ここが本当に魔法が起こる場所です。Kedroは、パイプライン機能を直接提供します。
パイプラインの初期のビルディングブロックはノードです。実行可能なコードの各部分は、ノード内にカプセル化することができます。ノードは、入力を受け入れて出力を生成する単純なPython関数です。その後、ノードの連続としてパイプラインを構造化することができます。ノードを呼び出し、入力と出力を指定してパイプラインを簡単に構築できます。Kedroは実行順序を決定します。
パイプラインが構築されたら、それらは提供されたpipeline_registry.pyファイルに登録されます。このアプローチの利点は、複数のパイプラインを作成できることです。これは特に機械学習において有益であり、データ処理パイプライン、モデル訓練パイプライン、推論パイプラインなどがあるかもしれません。
セットアップが完了したら、パイプラインのさまざまな側面を簡単に変更できます。
ノード.pyスクリプトの例を示すコードスニペット
パイプラインスクリプトの例を示すコードスニペット
設定
ケドロのベストプラクティスでは、すべての設定は提供されたparameters.ymlファイルを介して処理する必要があります。機械学習の観点から見ると、ハイパーパラメータもこのカテゴリに含まれます。このアプローチにより、実験を効率化することができます。つまり、別のハイパーパラメータの設定を持つparameters.ymlファイルに置き換えるだけで、簡単に実験を切り替えることができます。
また、私はLudwigの深層ニューラルネットワークmodel.yamlとデータソースの場所をparameters.yml設定に含めています。モデルまたはデータの場所が変更された場合(例えば、開発者のマシン間で移動する場合)、これらの設定を簡単に調整することができます。
パラメータ.ymlファイルの内容を示すコードスニペット
再現性
Kedroには、テンプレート化された構造の一部としてrequirements.txtファイルが含まれています。これにより、環境と正確なライブラリのバージョンを簡単に監視することができます。ただし、必要に応じてenvironment.ymlファイルなど、他の環境管理方法を使用することもできます。
ワークフローの確立
Kedroを使用して機械学習パイプラインを開発しようと考えている場合、最初は学習曲線が急なものですが、標準のワークフローを採用することでプロセスを簡素化することができます。以下は私が提案するワークフローです:
- 作業環境を確立する:私はこのタスクにAnacondaを使用することをお勧めします。通常、環境に必要なすべての依存関係が含まれたenvironment.ymlファイルを使用し、Anaconda Powershellコマンドラインを使用してこの環境を作成します。
- Kedroプロジェクトを作成する:Kedroがインストールされている場合(おそらくenvironment.ymlで宣言されているはずです)、Anacondaコマンドラインインターフェースを介してKedroプロジェクトを作成できます。
- Jupyter Notebooksで調査する:私はJupyter Notebooksで最初のパイプラインを構築します。これはほとんどのデータサイエンティストにとって馴染みのあるプロセスです。ただし、パイプラインが構築された後、各セルをKedroパイプラインのノードとして使用できるように整理する必要があります。
- データを登録する:データカタログに、データ処理またはデータ取り込みステップごとの入力と出力を記録します。
- パイプラインを追加する:ノートブックでの調査が完了したら、パイプラインを作成します。これはコマンドラインインターフェースを介して行われます。このコマンドを実行すると、作成したパイプラインの名前を持つ「pipelines」に別のフォルダが追加されます。このフォルダ内でノードとパイプラインを構築します。
- パイプラインを定義する:ここでは、Jupyter Notebooksからコードをnode.pyファイルに移動し、パイプラインに含めるノードに入力と出力があることを確認します。ノードが設定されたら、pipeline.pyファイルでパイプラインを定義します。
- パイプラインを登録する: pipeline_registry.pyファイルを使用して、新しく作成したパイプラインを登録するためのテンプレートが提供されます。
- プロジェクトを実行する:設定が完了すると、CLIを介して任意のパイプラインを実行し、プロジェクトを可視化することができます。
本番用のパイプラインは、機械学習オペレーションの広範なエコシステムに組み込まれます。MLOpsに関する私の記事も読んでみてください。
ビジネス向けの機械学習オペレーションの構築
効果的なMLOpsのブループリント:AI戦略のサポート
towardsdatascience.com
結論
Kedroは、本番用の機械学習パイプラインを提供するための優れたフレームワークです。この記事で説明した機能以外にも、他のオープンソースライブラリとの統合や、ドキュメンテーションやテストのためのパッケージなど、多数の統合があります。ケドロはモデルの展開に関連するすべての問題を解決するわけではありません。たとえば、モデルのバージョニングはDVCなどの別のツールでより良く処理される可能性があります。ただし、ケドロは商業環境でのデータサイエンティストの助けとなり、保守性、モジュラリティ、再現性のあるコードを本番用に準備することができます。初心者には比較的急な学習曲線がありますが、ドキュメントはわかりやすく、ガイド付きのチュートリアルも提供されています。これらのパッケージのいずれについても学ぶ最良の方法は、ダイブインして実験することです。
完全なGitHubリポジトリへのリンク
LinkedInで私をフォローする
より多くの洞察を得るためにVoAGIに登録してください:
私の紹介リンクでVoAGIに参加する — John Adeojo
データサイエンスのプロジェクト、経験、専門知識を共有し、あなたの旅をサポートします。VoAGIには以下からサインアップできます…
johnadeojo.medium.com
AIやデータサイエンスをビジネスの運用に統合したい場合は、無料の初回相談を予約することをお勧めします:
オンラインで予約する | データ中心のソリューション
無料の相談で企業が野心的な目標を達成するための専門知識を発見してください。私たちのデータサイエンティストと…
www.data-centric-solutions.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
