ディープラーニングライブラリーの紹介:PyTorchとLightning AI
ディープラーニングライブラリーの紹介:PyTorchとLightning AI

ディープラーニングは、ニューラルネットワークに基づく機械学習モデルの一部です。他の機械学習モデルでは、意味のある特徴を見つけるためのデータ処理は通常、手動で行われるか、ドメインの専門知識に頼る必要がありますが、ディープラーニングは人間の脳を模倣して重要な特徴を発見することができ、モデルのパフォーマンスを向上させることができます。
顔認識、詐欺検知、音声テキスト変換、テキスト生成など、ディープラーニングモデルの適用範囲は広範であり、ディープラーニングは多くの高度な機械学習アプリケーションで標準的なアプローチとなっており、それらについて学ぶことで得るものは何もありません。
このディープラーニングモデルを開発するために、ゼロから作業する代わりに、さまざまなライブラリフレームワークに頼ることができます。この記事では、ディープラーニングモデルを開発するために使用できる2つの異なるライブラリ、PyTorchとLighting AIについて説明します。さあ、始めましょう。
- 「Now You See Me (CME) 概念ベースのモデル抽出」
- 効果的な小規模言語モデル:マイクロソフトの13億パラメータphi-1.5
- 「BlindChat」に会いましょう:フルブラウザおよびプライベートな対話型AIを開発するためのオープンソースの人工知能プロジェクト
PyTorch
PyTorchは、ディープラーニングニューラルネットワークのトレーニングに使用するオープンソースのライブラリフレームワークです。PyTorchは、2016年にメタグループによって開発され、人気を博しています。人気の上昇は、PyTorchがTorchのGPUバックエンドライブラリをPython言語と組み合わせた機能によるものです。この組み合わせにより、パッケージはユーザーにとっては追いやすいが、ディープラーニングモデルの開発には強力です。
ライブラリによって有効になるいくつかの優れたPyTorchの機能があります。それには、素晴らしいフロントエンド、分散トレーニング、高速かつ柔軟な実験プロセスが含まれます。PyTorchのユーザーが多いため、コミュニティの開発と投資も大規模でした。長期的にはPyTorchを学ぶことは有益です。
PyTorchのビルディングブロックはテンソルであり、すべての入力、出力、およびモデルパラメータをエンコードするために使用される多次元配列です。テンソルはNumPy配列のようなものと考えることができますが、GPU上で実行することができます。
PyTorchライブラリを試してみましょう。GPUシステムにアクセスできない場合は、Google Colabなどのクラウドでチュートリアルを実行することをおすすめします(ただし、CPUでも動作する可能性があります)。ただし、ローカルで開始する場合は、次のページからライブラリをインストールする必要があります。使用しているシステムと仕様に合わせて適切なものを選択してください。
たとえば、CUDA対応システムの場合、以下のコードはpipインストールの例です。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
インストールが完了したら、PyTorchの機能をいくつか試してみましょう。このチュートリアルでは、ウェブチュートリアルに基づいてPyTorchを使用して単純な画像分類モデルを作成します。コードを実行し、コード内で何が起こっているかを説明します。
まず、PyTorchでデータセットをダウンロードします。この例では、数字の手書き分類データセットであるMNISTデータセットを使用します。
from torchvision import datasets
train = datasets.MNIST(
root="image_data",
train=True,
download=True
)
test = datasets.MNIST(
root="image_data",
train=False,
download=True,
)
MNISTのトレーニングデータセットとテストデータセットの両方をルートフォルダにダウンロードします。データセットの構造を確認しましょう。
import matplotlib.pyplot as plt
for i, (img, label) in enumerate(list(train)[:10]):
plt.subplot(2, 5, i+1)
plt.imshow(img, cmap="gray")
plt.title(f'Label: {label}')
plt.axis('off')
plt.show()

各画像は0から9までの単一の数字であり、10のラベルがあります。次に、このデータセットに基づいて画像分類器を開発しましょう。
PyTorchでディープラーニングモデルを開発するために、画像データセットをテンソルに変換する必要があります。画像はPILオブジェクトなので、PyTorchのToTensor関数を使用して変換を行うことができます。さらに、datasets関数を使用して自動的に画像を変換することもできます。
from torchvision.transforms import ToTensor
train = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
変換関数をtransformパラメータに渡すことで、データの形式を制御することができます。次に、データをDataLoaderオブジェクトにラップし、PyTorchモデルが画像データにアクセスできるようにします。
from torch.utils.data import DataLoader
size = 64
train_dl = DataLoader(train, batch_size=size)
test_dl = DataLoader(test, batch_size=size)
for X, y in test_dl:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
Shape of X [N, C, H, W]: torch.Size([64, 1, 28, 28])
Shape of y: torch.Size([64]) torch.int64
上記のコードでは、トレーニングデータとテストデータのためにDataLoaderオブジェクトを作成しています。データのバッチイテレーションごとに、上記のオブジェクトには64個の特徴とラベルが返されます。また、画像の形状は28 * 28(高さ * 幅)です。
次に、ニューラルネットワークモデルオブジェクトを開発します。
from torch import nn
#GPUにアクセスできる場合は 'cuda' に変更してください
device = 'cpu'
class NNModel(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.lr_stack = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.lr_stack(x)
return logits
model = NNModel().to(device)
print(model)
NNModel(
(flatten): Flatten(start_dim=1, end_dim=-1)
(lr_stack): Sequential(
(0): Linear(in_features=784, out_features=128, bias=True)
(1): ReLU()
(2): Linear(in_features=128, out_features=128, bias=True)
(3): ReLU()
(4): Linear(in_features=128, out_features=10, bias=True)
)
)
上記のオブジェクトでは、少数の層構造を持つニューラルモデルを作成しています。ニューラルモデルオブジェクトを開発するために、nn.module関数を使用してサブクラス化メソッドを使用し、__init__内でニューラルネットワークの層を作成します。
まず、2D画像データをフラット化関数でピクセル値に変換します。次に、シーケンシャル関数を使用してレイヤーをレイヤーのシーケンスにラップします。シーケンシャル関数の内部には、モデルのレイヤーがあります:
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
シーケンスとして上記の処理が行われます:
- まず、28*28の特徴を持つデータ入力は、線形レイヤー内の線形関数を使用して128の特徴を持つ出力に変換されます。
- ReLUは非線形活性化関数であり、モデルの入力と出力の間に非線形性を導入します。
- 128の特徴を持つ入力を線形レイヤーに入力し、128の特徴を持つ出力を得る
- 別のReLU活性化関数
- 128の特徴を持つ入力を線形レイヤーに入力し、10の特徴を持つ出力を得る(データセットのラベルは10個のラベルのみを持つ)。
最後に、forward関数はモデルへの実際の入力処理のために存在します。次に、モデルには損失関数と最適化関数が必要です。
from torch.optim import SGD
loss_fn = nn.CrossEntropyLoss()
optimizer = SGD(model.parameters(), lr=1e-3)
次のコードでは、モデリングの前にトレーニングとテストの準備を行います。
import torch
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>2f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>2f} \n")
モデルのトレーニングを実行する準備が整いました。モデルで実行するエポック(反復回数)の数を決める必要があります。この例では、5回実行することにします。
epoch = 5
for i in range(epoch):
print(f"Epoch {i+1}\n-------------------------------")
train(train_dl, model, loss_fn, optimizer)
test(test_dl, model, loss_fn)
print("完了!")
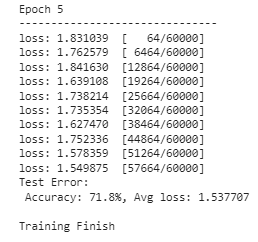
モデルのトレーニングが終了し、任意の画像予測活動に使用できるようになりました。結果は異なる場合がありますので、上記の画像とは異なる結果が予想されます。
PyTorchができることはほんの一部ですが、PyTorchを使用してモデルを構築することは簡単であることがわかります。事前学習済みモデルに興味がある場合、PyTorchにはアクセスできるハブがあります。
Lighting AI
Lighting AIは、PyTorchの深層学習モデルのトレーニング時間を最小化し、簡素化するためのさまざまな製品を提供する会社です。彼らのオープンソース製品の1つであるPyTorch Lightingは、PyTorchモデルのトレーニングと展開のためのフレームワークを提供するライブラリです。
Lightingには、コードの柔軟性、ボイラープレートのない、最小限のAPI、チームのコラボレーションの改善など、いくつかの機能があります。Lightingは、マルチGPUの利用や高速な低精度トレーニングなどの機能も提供しています。これにより、LightingはPyTorchモデルの開発における良い選択肢となります。
Lightingを使用してモデルの開発を試してみましょう。まず、パッケージをインストールする必要があります。
pip install lightning
Lightingがインストールされたら、メトリックの選択を簡素化するために、TorchMetricsという別のLighting AI製品もインストールします。
pip install torchmetrics
すべてのライブラリがインストールされたら、Lightingラッパーを使用して以前の例と同じモデルの開発を試してみましょう。以下に、モデルの開発のための全体のコードがあります。
import torch
import torchmetrics
import pytorch_lightning as pl
from torch import nn
from torch.optim import SGD
# GPUにアクセスできる場合は 'cuda' に変更してください
device = 'cpu'
class NNModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.lr_stack = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
self.train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=10)
self.valid_acc = torchmetrics.Accuracy(task="multiclass", num_classes=10)
def forward(self, x):
x = self.flatten(x)
logits = self.lr_stack(x)
return logits
def training_step(self, batch, batch_idx):
x, y = batch
x, y = x.to(device), y.to(device)
pred = self(x)
loss = nn.CrossEntropyLoss()(pred, y)
self.log('train_loss', loss)
# トレーニングの正確性を計算する
acc = self.train_acc(pred.softmax(dim=-1), y)
self.log('train_acc', acc, on_step=True, on_epoch=True, prog_bar=True)
return loss
def configure_optimizers(self):
return SGD(self.parameters(), lr=1e-3)
def test_step(self, batch, batch_idx):
x, y = batch
x, y = x.to(device), y.to(device)
pred = self(x)
loss = nn.CrossEntropyLoss()(pred, y)
self.log('test_loss', loss)
# テストの正確性を計算する
acc = self.valid_acc(pred.softmax(dim=-1), y)
self.log('test_acc', acc, on_step=True, on_epoch=True, prog_bar=True)
return loss
上記のコードで何が起こっているかを詳しく見てみましょう。以前に開発したPyTorchモデルとの違いは、NNModelクラスがLightingModuleからのサブクラス化を使用していることです。さらに、TorchMetricsを使用して評価するための正確性メトリックを割り当てます。その後、クラス内にトレーニングおよびテストステップを追加し、最適化関数を設定します。
モデルがすべて設定されたら、変換されたDataLoaderオブジェクトを使用してモデルのトレーニングを実行します。
# PyTorch Lightningトレーナーを作成する
trainer = pl.Trainer(max_epochs=5)
# モデルを作成する
model = NNModel()
# モデルをフィットさせる
trainer.fit(model, train_dl)
# モデルをテストする
trainer.test(model, test_dl)
print("トレーニング完了")
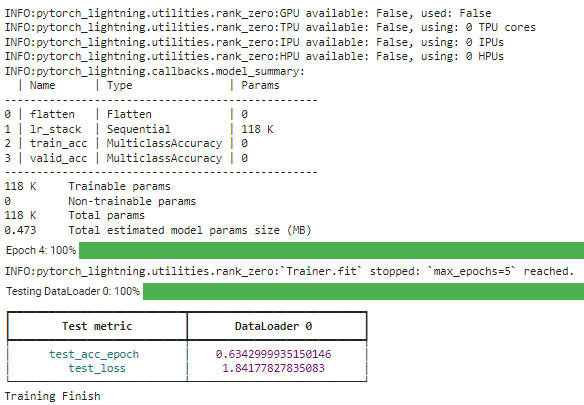
Lightningライブラリを使用すると、必要な構造を簡単に調整することができます。さらに詳しい情報については、ドキュメンテーションを参照してください。
結論
PyTorchは、ディープラーニングモデルの開発のためのライブラリであり、多くの高度なAPIに簡単にアクセスするためのフレームワークを提供しています。Lightning AIもこのライブラリをサポートしており、モデルの開発を簡素化し、開発の柔軟性を高めるフレームワークを提供しています。この記事では、ライブラリの特徴と簡単なコードの実装を紹介しました。Cornellius Yudha Wijayaは、データサイエンスアシスタントマネージャーおよびデータライターです。Allianz Indonesiaでフルタイムで働きながら、ソーシャルメディアと執筆メディアを通じてPythonとデータのヒントを共有することが大好きです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「コンテキストに基づくドキュメント検索の強化:GPT-2とLlamaIndexの活用」
- 「AIはどれくらい環境に優しいのか?人間の作業と人工知能の二酸化炭素排出量を比較する」
- 大規模言語モデル:RoBERTa — ロバストに最適化されたBERTアプローチ
- 「TikTokがAI生成コンテンツのためのAIラベリングツールを導入」
- デシAIは、DeciDiffusion 1.0を公開しました:820億パラメータのテキストから画像への潜在的拡散モデルで、安定した拡散と比べて3倍の速度です
- 「Hugging FaceはLLMのための新しいGitHubです」
- 「Google DeepMindが、7100万件の「ミスセンス」変異の効果を分類する新しいAIツールを発表」





