ディープダイブ:Hugging Face Optimum GraphcoreにおけるビジョンTransformer
ディープダイブ:Hugging Face Optimum GraphcoreのビジョンTransformer
このブログ投稿では、Hugging Face Optimumライブラリを使用して、事前学習済みのTransformerモデルをあなたのデータセットに簡単に微調整する方法をGraphcoreのIntelligence Processing Units(IPUs)で紹介します。例として、大規模で広く使用されている胸部X線データセットを取り上げ、ビジョンTransformer(ViT)モデルを訓練する手順とノートブックを提供します。
ビジョンTransformer(ViT)モデルの紹介
2017年、GoogleのAI研究者グループがTransformerモデルアーキテクチャを紹介する論文を発表しました。Transformerは新しいセルフアテンションメカニズムによって特徴付けられ、言語アプリケーションのための新しい効率的なモデルのグループとして提案されました。実際、過去5年間でTransformerは爆発的な人気を見ており、自然言語処理(NLP)の事実上の標準として受け入れられています。
言語のためのTransformerは、急速に進化するGPTとBERTモデルファミリーによって特に代表されています。両方とも、Hugging Face Optimum Graphcoreライブラリの一部としてGraphcore IPUs上で簡単かつ効率的に実行することができます。
![]()
Transformerモデルアーキテクチャの詳細な説明(NLPに焦点を当てたもの)は、Hugging Faceのウェブサイトで見つけることができます。
Transformerは言語で初期の成功を収めましたが、非常に多目的であり、このブログ投稿でカバーするように、コンピュータビジョン(CV)などのさまざまな目的に使用することができます。
CVは、畳み込みニューラルネットワーク(CNN)が間違いなく最も人気のあるアーキテクチャの1つです。しかし、ビジョンTransformer(ViT)アーキテクチャは、Google Researchが2021年の論文で初めて紹介された画像認識のブレークスルーであり、BERTやGPTと同じセルフアテンションメカニズムを主要なコンポーネントとして使用しています。
BERTや他のTransformerベースの言語処理モデルは、文(つまり単語のリスト)を入力として受け取りますが、ViTモデルは入力画像をいくつかの小さなパッチに分割し、言語処理における個々の単語に相当するものにします。各パッチは、Transformerモデルによって線形にエンコードされ、個別に処理できるベクトル表現に変換されます。この画像をパッチやビジュアルトークンに分割するアプローチは、CNNが使用するピクセル配列とは対照的です。
事前学習により、ViTモデルは画像の内部表現を学習し、それを下流タスクに役立つ視覚的な特徴を抽出するために使用できます。たとえば、事前学習されたビジュアルエンコーダの上に線形層を配置することで、新しいラベル付き画像データセットで分類器を訓練することができます。通常、[CLS]トークンの上に線形層を配置します。このトークンの最後の隠れ状態は、画像全体の表現と見なすことができます。
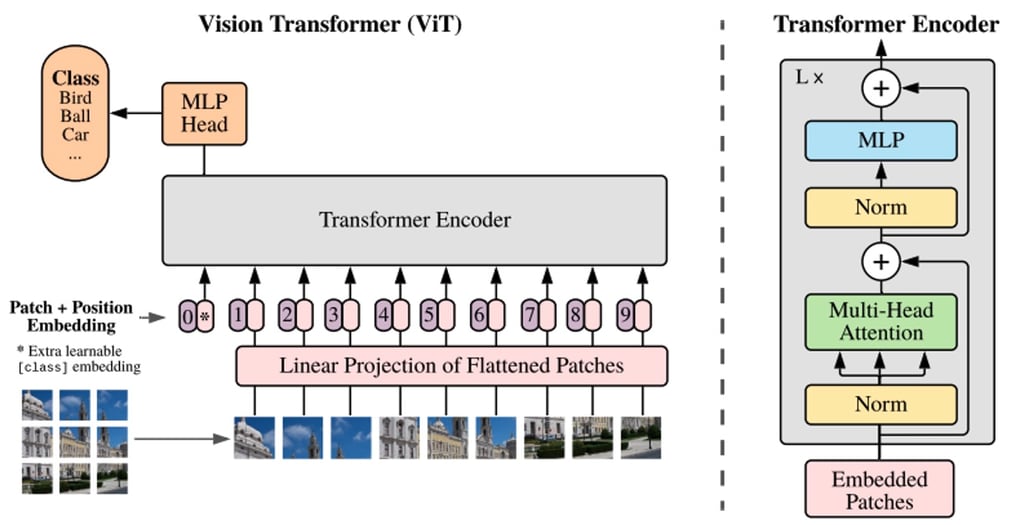
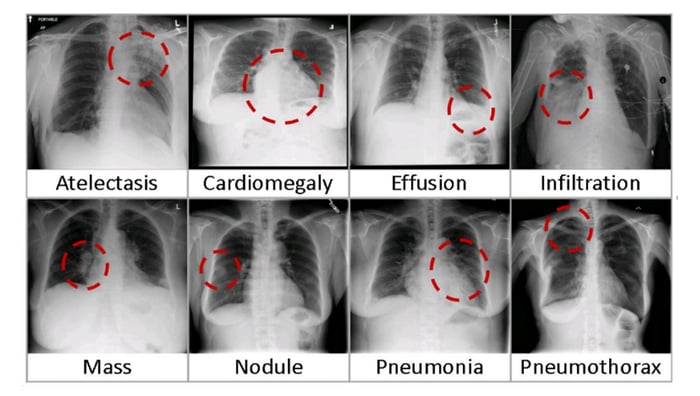
CNNと比較して、ViTモデルはより高い認識精度を持ちながら、より低い計算コストで動作し、画像分類、物体検出、セグメンテーションなどのさまざまなアプリケーションに適用されています。医療領域のユースケースには、COVID-19、大腿骨骨折、肺気腫、乳がん、アルツハイマー病などの検出と分類などが含まれます。
ViTモデル – IPUに最適なモデル
GraphcoreのIPUは、データパイプライニングとモデル並列処理の組み合わせを使用して、ViTモデルに特に適しています。この大規模並列プロセスの高速化は、IPUのMIMDアーキテクチャとIPU-Fabricを中心としたスケールアウトソリューションによって可能になっています。
パイプライン並列処理を導入することにより、データ並列学習の1つのIPUが処理することができるバッチサイズが増加し、1つのIPUが処理するメモリ領域へのアクセス効率が改善され、データ並列学習のためのパラメータ集約の通信時間が短縮されます。
Hugging Face Optimum Graphcoreライブラリには、事前最適化された一連のTransformerモデルが追加されており、ViTなどのモデルをIPU上で高いパフォーマンスと効率性で実行および微調整することが非常に簡単になっています。
Hugging Face Optimumを介して、GraphcoreはIPUでモデルをトレーニングするのに最大限の効率性を持つモデルチェックポイントと設定ファイルを準備済みで提供しています。これは特にViTモデルが通常大量のデータで事前学習を必要とするため、非常に役立ちます。この統合により、Hugging Faceモデルハブ内で元の著者自身が公開したチェックポイントを使用できるため、自分自身でトレーニングする必要はありません。Optimumは、ユーザーが任意の公開データセットをプラグアンドプレイできるようにし、AIモデルの全体的な開発ライフサイクルを短縮し、Graphcoreの最先端のハードウェアとのシームレスな統合を可能にします。
このブログ投稿では、Dosovitskiyらによる「画像は16×16の単語の価値がある:スケールでの画像認識のためのトランスフォーマー」という論文に基づき、ImageNet-21kで事前学習済みのViTモデルを使用します。例として、Optimumを使用してChestX-ray14データセットでViTを微調整するプロセスを紹介します。
X線分類におけるViTモデルの価値
医療画像のタスクでは、放射線医学技師はX線画像を基に問題を確実にかつ効率的に検出し、仮診断を行うために多くの年月を費やしています。この困難さは、画像の非常に微小な違いと空間的制約から生じるため、コンピュータ支援検出および診断(CAD)技術は臨床医のワークフローと患者の結果改善に大きな潜在能力を示しています。
同時に、X線分類のためのモデル(ViTまたはそれ以外)を開発するには、次のような課題があります:
- ゼロからモデルをトレーニングするには、膨大なラベル付きデータが必要です。
- 高解像度およびボリュームの要件により、そのようなモデルをトレーニングするためには強力なコンピューティングが必要です。
- 肺診断などの多クラスおよび多ラベルの問題の複雑性は、疾患カテゴリの数によって指数関数的に増加します。
上記のように、Hugging Face Optimumを使用したデモの目的では、ViTをゼロからトレーニングする必要はありません。代わりに、Hugging Faceモデルハブにホストされたモデルの重みを使用します。
X線画像には複数の疾患が存在する可能性があるため、多ラベル分類モデルで作業します。対象のモデルは、google/vit-base-patch16-224-in21kのチェックポイントを使用しています。これはTIMMリポジトリから変換され、ImageNet-21kの1400万枚の画像で事前学習されています。IPUのジョブを並列化および最適化するために、構成はGraphcore-ViTモデルカードを介して利用可能になっています。
これがIPUを使用するのが初めての場合は、基本的なコンセプトを理解するためにIPUプログラマーガイドを読んでください。IPUで独自のPyTorchモデルを実行する方法については、PyTorchの基本チュートリアルを参照し、Hugging Face Optimum Notebooksを介してOptimumの使用方法を学んでください。
ChestXRay-14データセットでのViTのトレーニング
まず、National Institutes of Health(NIH)クリニックセンターの胸部X線データセットをダウンロードする必要があります。このデータセットには、1992年から2015年の間に30,805人の患者から収集された112,120の匿名化された正面ビューX線が含まれています。このデータセットは、NLP技術を使用して放射線学報告のテキストから抽出されたラベルに基づいて、14の一般的な疾患をカバーしています。
環境の設定
このチュートリアルを実行するためには、次の要件があります:
- 最新のPoplar SDKおよびPopTorch環境が有効になっているJupyter Notebookサーバー(IPUをJupyterノートブックから使用する方法については、当社のガイドを参照してください)
- Graphcore TutorialsリポジトリのViTトレーニングノートブック
Graphcore Tutorialsリポジトリには、このガイドで説明されているステップバイステップのチュートリアルノートブックとPythonスクリプトが含まれています。リポジトリをクローンし、tutorials / tutorials / pytorch /vit_model_training/にあるwalkthrough.ipynbノートブックを起動してください。
私たちは、HF Optimum Gradientを作成し、無料のIPUで始めるチュートリアルを開始できるようにしました。ランタイムにサインアップして起動してください:![]()
データセットの入手
データセットの/imagesディレクトリをダウンロードしてください。次のようにbashを使用してファイルを展開できます:for f in images*.tar.gz; do tar xfz "$f"; done。
次に、ラベルを含むData_Entry_2017_v2020.csvファイルをダウンロードしてください。デフォルトでは、チュートリアルはスクリプトが実行される場所と同じフォルダに/imagesフォルダと.csvファイルがあることを想定しています。
Jupyter環境にデータセットがある場合、最新のHugging Face Optimum Graphcoreパッケージとその他の依存関係をrequirements.txtにインストールしてインポートする必要があります:
%pip install -r requirements.txt
` `
Chest X-rayデータセットに含まれる検査は、X線画像(グレースケール、224×224ピクセル)と対応するメタデータで構成されています:Finding Labels, Follow-up #,Patient ID, Patient Age, Patient Gender, View Position, OriginalImage[Width Height] and OriginalImagePixelSpacing[x y]。
次に、ダウンロードした画像とラベルがダウンロードされるファイルの場所を定義します。
Graphcore Optimum ViTモデルを使用して、画像から疾患(「Finding Label」で定義される)を予測するためにトレーニングします。 「Finding Label」は、14種類の疾患または「No Finding」ラベルのいずれかであり、これは疾患が検出されなかったことを示します。 Hugging Faceライブラリと互換性を持たせるために、テキストラベルをN-hotエンコードされた配列に変換する必要があります。 N-hotエンコードされた配列は、ブール値のリストとしてラベルを表し、画像に対応する場合はtrue、そうでない場合はfalseとします。
まず、データセット内の一意のラベルを特定します。
次に、ラベルをN-hotエンコードされた配列に変換します:
datasets.load_dataset関数を使用してデータをロードする際、ラベルは各ラベルのフォルダを持つか(「 ImageFolder 」ドキュメントを参照)、またはmetadata.jsonlファイルを持つことで指定できます(「 ImageFolder with metadata 」ドキュメントを参照)。このデータセットの画像には複数のラベルがあるため、metadata.jsonlファイルを使用することを選択しました。画像ファイル名とそれに関連するラベルをmetadata.jsonlファイルに書き込みます。
データセットの作成
さあ、PyTorchデータセットを作成し、トレーニングセットと検証セットに分割する準備が整いました。このステップでは、データセットをArrowファイル形式に変換し、トレーニングと検証中にデータを高速に読み込むことができます(ArrowとHugging Faceについての情報)。データセット全体がロードされ、前処理されるため、数分かかる場合があります。
IPUでモデルをトレーニングするためには、Hugging Face Hubからモデルをインポートし、IPUTrainerクラスを使用してトレーナーを定義する必要があります。 IPUTrainerクラスは、元のTransformer Trainerと同じ引数を受け取り、IPU上でのコンパイルと実行の動作を指定するIPUConfigオブジェクトと連携して動作します。
さて、Hugging FaceからViTモデルをインポートします。
このモデルをIPUで使用するには、IPU設定IPUConfigをロードする必要があります。これにより、Graphcore IPUsに固有のすべてのパラメータを制御することができます(既存のIPU設定はこちらで見つけることができます)。私たちはGraphcore/vit-base-ipuを使用します。
トレーニングのハイパーパラメータを IPUTrainingArguments を使用して設定しましょう。これは、Hugging Face の TrainingArguments クラスをサブクラス化し、IPU とその実行特性に特化したパラメータを追加します。
評価のためのカスタムパフォーマンスメトリックの実装
マルチラベル分類モデルのパフォーマンスは、ROC(受信者操作特性)曲線の下の面積(AUC_ROC)を使用して評価することができます。AUC_ROC は、異なるクラスと異なる閾値値における真陽性率(TPR)と偽陽性率(FPR)のプロットです。これは、クラスの不均衡に対して感度が低く、解釈が容易なため、マルチラベル分類タスクでよく使用されるパフォーマンスメトリックです。
このデータセットでは、AUC_ROC はモデルが異なる疾患を分離する能力を表します。スコアが0.5の場合、正しい疾患を取得する確率は50%であり、スコアが1の場合、疾患を完全に分離できます。このメトリックは Datasets では利用できないため、自分で実装する必要があります。HuggingFace Datasets パッケージでは、load_metric() 関数を介してカスタムメトリックの計算が可能です。私たちは compute_metrics 関数を定義し、これを Transformer の評価関数に他のサポートされているメトリックと同様に公開します。 compute_metrics 関数は、ViT モデルによって予測されたラベルを取り、ROC 曲線の下の面積を計算します。 compute_metrics 関数は、EvalPrediction オブジェクト(predictions と label_ids フィールドを持つ名前付きタプル)を受け取り、文字列を浮動小数点数に変換する辞書を返さなければなりません。
モデルをトレーニングするために、IPUTrainer クラスを使用してトレーナーを定義します。これは、モデルを IPUs 上で実行するためのコンパイルと、トレーニングと評価を行うことを担当します。 IPUTrainer クラスは Hugging Face Trainer クラスと同様に動作しますが、追加の ipu_config 引数を受け取ります。
トレーニングの実行
トレーニングを加速するために、前回のチェックポイントが存在する場合はそれを読み込みます。
さあ、トレーニングを開始しましょう。
収束のプロット
トレーニングが完了したので、トレーナーの出力を整形してプロットし、トレーニングの振る舞いを評価できます。
トレーニングの損失と学習率をプロットします。
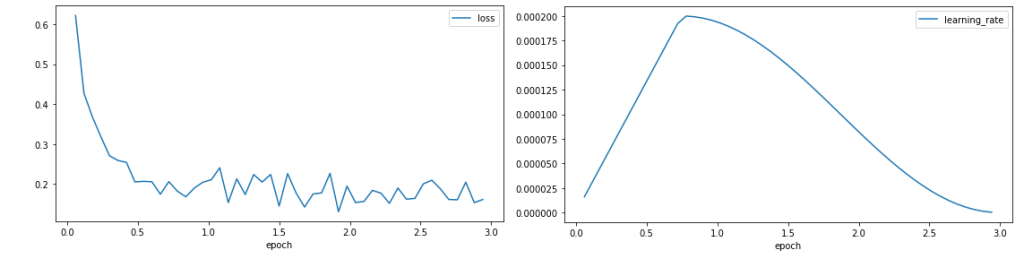 ロス曲線は、トレーニングの開始時にロスが急速に減少し、0.1の周囲で安定化することを示しています。これはモデルが学習していることを示しています。学習率はトレーニング期間の25%のウォームアップを経て増加し、その後コサイン減衰を追います。
ロス曲線は、トレーニングの開始時にロスが急速に減少し、0.1の周囲で安定化することを示しています。これはモデルが学習していることを示しています。学習率はトレーニング期間の25%のウォームアップを経て増加し、その後コサイン減衰を追います。
評価の実行
モデルのトレーニングが完了したので、検証データセットを使用して未知のデータのラベルを予測する能力を評価できます。
メトリックは、チュートリアルが3エポック後に達成した検証 AUC_ROC スコアを示しています。
モデルの精度を改善するためには、より長いトレーニングなど、いくつかの方法を試すことができます。また、最適化手法、学習率、学習率スケジュール、損失スケーリング、または自動損失スケーリングを変更することで、検証パフォーマンスも向上する可能性があります。
Hugging Face Optimum を IPUs 上で無料で試す
この記事では、ViT モデルを紹介し、ローカルデータセットを使用して IPU 上で Hugging Face Optimum モデルをトレーニングするためのチュートリアルを提供しました。
上記で概説した完全なプロセスは、Graphcore の Paperspace との新しいパートナーシップにより、数分でエンドツーエンドで実行できるようになりました。今日のローンチにより、サービスは Gradient で提供され、Graphcore IPUs を搭載した Hugging Face Optimum モデルの選択肢にアクセスできるようになります。Gradient は、Paperspace のウェブベースの Jupyter ノートブック上で動作します。
![]()
ViT、BERT、RoBERTa などを含む Hugging Face Optimum と IPUs を使用して Paperspace Gradient で Hugging Face Optimum を試してみたい場合は、こちらでサインアップし、こちらで入門ガイドを見つけることができます。
IPUs上のHugging Face Optimumのさらなるリソース
- GraphcoreのGitHubでのViT Optimumチュートリアルコード
- Graphcore Hugging Faceモデル&データセット
- GitHub上のOptimum Graphcore
この詳細な解説は、GraphcoreからのEva Woodbridge、James Briggs、Jinchen Ge、Alexandre Payot、Thorin Farnsworth、およびその他の貢献者の広範なサポート、指導、洞察によるものであり、また、Hugging FaceのJeff Boudier、Julien Simon、Michael Benayounも貢献しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






